Clear Sky Science · ja
Kymata Soto 言語データセット:自然な音声処理のための電気磁性脳磁図データセット
脳が実際の会話をどう“聞く”かを覗き見る
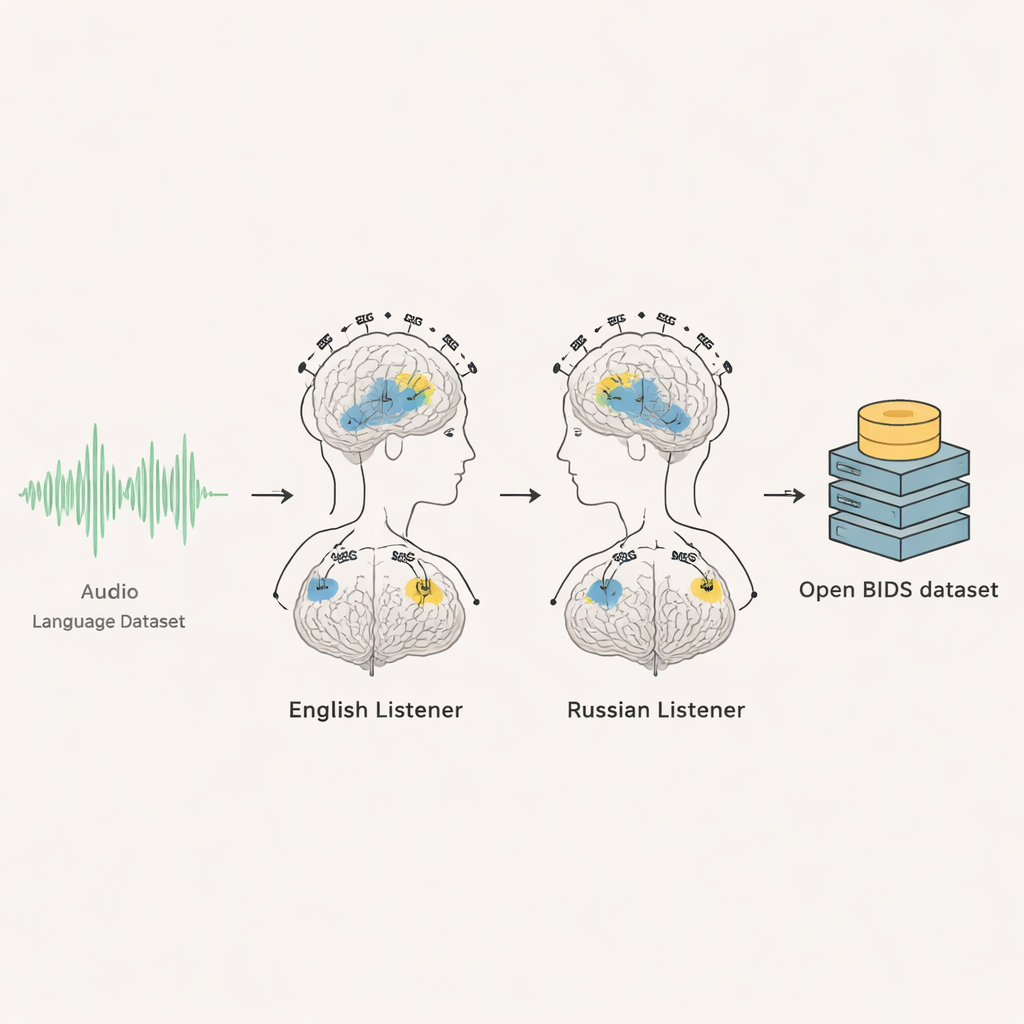
私たちが日常的に話したり聞いたりしているのは、単語や注意深く読まれた文ではなくカジュアルな会話が大半です。しかし、言語に関する脳研究の多くは人工的な課題に依拠してきました。Kymata Soto 言語データセットは、この状況を変えます。英語とロシア語の活発なラジオ討論をただ聴いている人々の豊富で公開された脳記録を提供することで、脳が自然な音声をどのように処理するかを研究者に強力な窓を与えます。
実際の音声に対する脳応答の新しいライブラリ
このプロジェクトは、2つの先端的な脳計測法――脳波計(EEG)と脳磁図(MEG)――を組み合わせ、35名の成人(英語母語話者20名、ロシア語母語話者15名)から収集しました。参加者は静かに座って、自分の言語で約6分半のラジオ風会話を聞いている間、1秒間に千回のサンプリングで脳活動が記録されました。各人は同じ音声を複数回聞くため、研究者は繰り返しの平均を取って背景雑音から確実な脳応答を抽出できます。その結果、議論が展開する中で人が追っている瞬間ごとの脳応答を時間的に厳密に記録した詳細なデータが得られます。

アイスクリームやコーヒーに関する会話
古典的な物語や人工的な文を使う代わりに、チームは身近で興味を引く話題を選びました:英語聴取者にはアイスクリームの歴史、ロシア語聴取者にはコロンビア産コーヒーの歴史です。両方の録音はBBCのスタジオ討論から採られ、話者は男女合わせて3名でした。会話は約400秒に編集され、イヤーピースを通じて快適な音量で提示されました。各リピートの後、参加者は内容について1〜2問の簡単な選択式質問に答え、積極的に試験するのではなく注意を保ち話を追ったことを確認する程度の設計になっています。
視線を安定させつつ音に集中させる工夫
聴取中、参加者は画面中央の十字を見つめていました。その周囲では、色付きの点の群れがランダムに見える動きをし続けました。これらの動く点は二つの目的を果たします:視線を安定させることでデータ品質を向上させること、そして後の解析で他の研究者が利用できる制御された視覚的運動と色のパターンを作ることです。重要なのは、点の動きは音声内容と同期されておらず、物語を「図示」したり意味を付加したりするものではなく、音声と併せて研究できる一貫した視覚的背景を提供している点です。
生データから利用可能なデータへ
研究者たちは実験の全過程を丁寧に記録し、BIDSと呼ばれる国際標準に従ってデータセットを整理しました。各参加者について、生のEEGおよびMEG記録、音声開始のタイミングマーカー、秒ごとの視覚イベント、練習セグメントが含まれます。チームは元の音声ファイル、完全な文字起こし、各単語や個々の発話音が開始した正確な時刻も提供しています。使用した正確な音声抜粋を自動的に再現するスクリプトも含まれます。英語グループについては、匿名化されたMRI脳スキャンも共有されており、脳応答を個々の脳解剖にマッピングできます。一方でロシア語グループは同意によりMRI画像の共有が許可されなかったため、利用者は標準的な平均脳テンプレートに依拠することが勧められます。
信号が妥当であることの検証
データが科学的に信頼できることを確かめるため、著者らは音の大きさ(ラウドネス)が時間的にどう変化するかに着目した検証解析を行いました。音声をいくつかの数理的表現の「時間変化するラウドネス」に変換し、脳応答がそれらのラウドネスパターンとどこでいつ整合するかを調べました。英語・ロシア語の両方の聴取者で、脳は類似した時間的パターンを示し、先行研究で報告されている結果と整合しました。言語間および過去研究との一致は、記録がクリーンで信頼でき、他者が利用するに足ることの強い指標です。
将来の脳と言語研究にとっての意義
専門外の方への要点は、このデータセットが多様な研究チームに実際の自発的な会話が脳でどのように処理されるかを研究するための共通資源を提供するということです。公開され、注釈が整い、2言語で記録されているため、会話理解の基礎的な問い、言語間比較、または脳活動から直接音声を復元しようとする野心的な試みにまで対応できます。要するに、Kymata Soto 言語データセットは単一の問いに答えるためのものではなく、日常の会話を脳がどのように意味付けしているかを探るための高品質で共有可能な基盤を科学コミュニティに提供するものです。
引用: Yang, C., Parish, O., Klimovich-Gray, A. et al. Kymata Soto Language Dataset: an electro-magnetoencephalographic dataset for natural speech processing. Sci Data 13, 254 (2026). https://doi.org/10.1038/s41597-026-06579-8
キーワード: 脳と言語, 音声知覚, EEG MEG, 自然主義的会話, 公開ニューロイメージングデータ