Clear Sky Science · ja
欧州のゲノミクス分野におけるドイツ人間ゲノム—フェノームアーカイブ(GHGA)メタデータモデルの意味的整合性
ゲノムデータ共有にファイル以上のものが必要な理由
現代医療は病気の診断や治療の個別化のためにDNAを読み取ることにますます依存しています。しかし、ゲノミクスの真の力は、多くの病院や国からのデータを結合できたときに発揮されます。そのためには各データセットが明確で互換性のある形で記述され、ヨーロッパのGDPRのようなプライバシー法が厳格に順守される必要があります。本稿は、ドイツ人間ゲノム—フェノームアーカイブ(GHGA)が、貴重なデータが欧州全体で発見され、理解され、安全に共有されるように、ゲノム研究を詳細に「記述するための仕組み」を構築している方法を説明します。
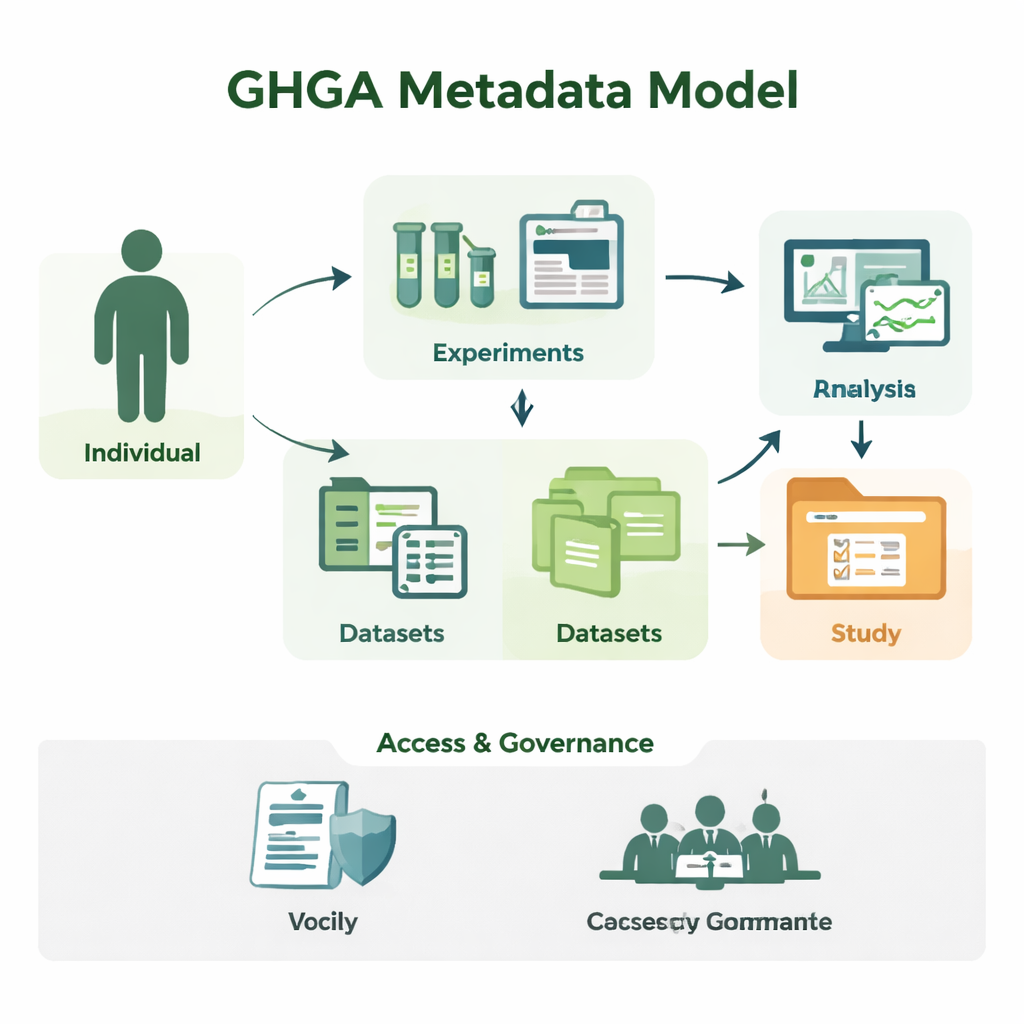
生の配列から理解可能な研究へ
ゲノム研究は膨大な配列データを生み出しますが、単独のDNA配列ファイルは意味を成しません。研究者はサンプルが誰から採取されたか、どの組織が使われたか、実験がどのように行われたか、そしてデータをどの条件で再利用できるかを知る必要があります。GHGAはこの周辺情報をメタデータとして捉えます。モデルは、研究参加者(「個人」)、採取されたサンプル、実施された実験や解析、作成されたデータファイル、それらを束ねるデータセットや研究といった16の構成要素にメタデータを整理します。科学的な詳細をアクセス条件などの管理的要素と分離することで、このモデルは実際の研究所やデータポータルの動きを反映しつつ、コンピュータが確実に処理できる形になっています。
データの有用性を保ちつつ個人識別を防ぐ
GHGAはセンシティブな人間の健康データを扱うため、モデルは科学的に豊富でありながら個人を特定しにくい設計である必要がありました。欧州のGDPRは、名前が除かれていても個人に遡って結び付けられる合理的な可能性がある情報は個人データに該当すると規定しています。記事は、年齢、郵便番号、希少な診断名などの詳細を組み合わせると身元が明らかになる可能性があることを示した綿密なプライバシー分析を説明します。これを受けて、GHGAの公開ポータルでは詳細な位置情報を避け、年齢は正確な年ではなく広い区分にまとめ、詳細な診断コードは粗いカテゴリに統合します。こうすることで、研究者はデータセットが自分の研究に関連するかどうかを判断できる一方で、個人を特定するために必要な労力は現実的でない水準になります。
欧州のゲノミクスエコシステムとの互換性を検証する
真に有用であるためには、GHGAのメタデータは欧州の広範なゲノムアーカイブやツールのネットワークに適合している必要があります。そこで著者らは自分たちのモデルを、ヨーロピアン・ゲノム—フェノーム・アーカイブ(EGA)の2バージョン、ISA-tab標準、オランダの医療発のFAIR Genomesモデルという4つの広く使われるフレームワークと項目ごとに比較しました。各GHGAフィールドについて、他のモデルに同等の項目があるか、逆に他のモデルの項目がGHGAに対応するかを問う詳細な「クロスウォーク」を実施しました。結果、研究、サンプル、実験、解析、ファイル形式の記述に関しては、GHGAの主要なプロパティの多くが他に明確な対応物を持つことが分かりました。これはGHGAのデータセットが他の欧州システムに保存されたデータとともに理解され、統合され得ることを意味します。
共通点を見いだす—そしてまだ欠けているもの
この比較から、チームは5つのモデルのうち少なくとも3つに現れる25の「コンセンサス」メタデータ項目を抽出しました。これらは、参加者の性別や健康状態、使用された組織、シーケンシングの種類と機器、解析手法、ファイル形式、基本的な研究記述や連絡先情報といった必須事項をカバーします。これらの共通項目は既存の最小報告ガイドラインと整合し、新しいゲノムデータポータルを設計する際のコアチェックリストとして役立ちます。一方で、比較は一部のモデルが収集するがGHGAが現時点で省略しているか、自由記述でのみ受け入れている情報も明らかにしました。例えば、採取やシーケンシングの正確な日付、除外された診断、詳細な連絡先名などです。これらの多くの省略は、プライバシーと匿名性を優先するための意図的なトレードオフです。
今後の医療研究にとっての意味
総じて、この研究はGHGAのメタデータモデルが詳細で柔軟かつ国際的な実践とよく整合しており、同時に厳格な欧州のプライバシー規則の範囲内にあることを示しています。すでに他のアーカイブが必須とする項目をすべて網羅しており、単一細胞や空間オミクスなどの新技術にも拡張可能です。誰が何を含む研究か、データがどのように生成されたか、どの条件で再利用できるかを明確に記述する手段を提供することで、GHGAは孤立したデータサイロをつながった研究資源へと変えていきます。患者にとっては、一旦提供されたデータが国境を越えて年単位で安全に発見や治療の改良に寄与する可能性が高まることを意味します。
引用: Mauer, K., Iyappan, A., Parker, S. et al. Semantic alignment of the German Human Genome-Phenome Archive metadata model in Europe’s genomics field. Sci Data 13, 242 (2026). https://doi.org/10.1038/s41597-026-06575-y
キーワード: ゲノムデータ共有, メタデータ標準, プライバシーとGDPR, GHGA, 個別化医療