Clear Sky Science · ja
ChatGPT以前の時代における中西部アメリカ合衆国のデータサイエンス学術プログラム:精選データセット
学生とコミュニティにとってなぜ重要か
米国全体で毎学期のように新しいデータ関連学位が登場している一方で、「データサイエンス」「データアナリティクス」「学際的プログラム」が実際に何を意味するのかはわかりにくいことがあります。本稿は、ChatGPTのようなツールが広まる直前の時点で中西部アメリカ合衆国内のすべてのデータ関連学術プログラムをマッピングし整理した、慎重に構築されたデータセットを説明します。これにより、大学が次世代のデータ専門家をどのように育成していたかの明確なスナップショットが得られます。
AIの波が来る前に撮られたスナップショット
著者らは、生成型人工知能が教育や技術的業務を再構築し始める直前の2023年時点におけるデータサイエンス教育の状況を記録することを目的としました。対象は中西部の12州にわたる高等教育機関で、コミュニティカレッジから主要大学まで含まれます。プログラム名に「data(データ)」が含まれる場合はすべて詳細に調査しました:どこで教えられているのか、専攻か副専攻か証明書か、学部生向けか大学院生向けか、どの学部が運営しているのか、講義はどのような科目を含むのか。こうして時点を固定することで、AIツールの普及に伴って教育内容がどのように変化するかを将来の研究者が追跡できる基盤を提供します。
さまざまなタイプのデータプログラムを整理する
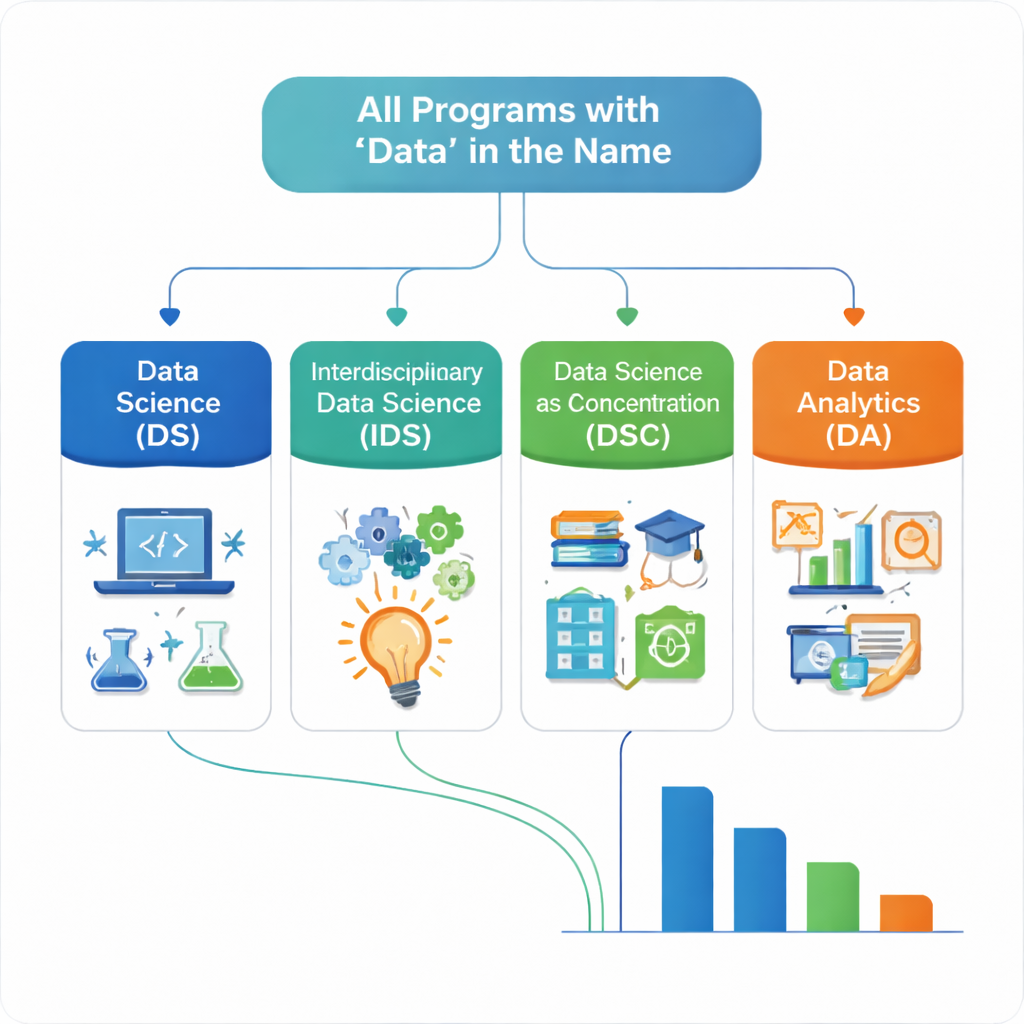
著者らが直面した最大の課題の一つは、「データサイエンス」という用語が非常に多様な使われ方をしていることです。同じような名前の二つの学位が、まったく異なる職業に学生を育てる場合があります。この混乱に秩序を与えるため、著者らは再現可能な分類体系を作成し、四つの主要グループに分けました。典型的なData Scienceプログラムは、相当な数学・統計学・コンピュータサイエンスを統合し、通常はそれらの学部が主導します。Interdisciplinary Data Science(学際的データサイエンス)プログラムは同じ技術的核を共有しますが、非技術系学部が部分的に運営したり、学生に第二専攻や副専攻を求めたりします。Data Science as a Concentration(専攻内のデータサイエンス)は、他の学位内のトラックとして「データ」が位置づけられるケースを指します。Data Analyticsプログラムは、「データ」という語を含むものの、数学と計算の両方を十分に含まないか、定量系以外の学部が主導している提供物を含みます。
情報の収集と検証方法
データセットを構築するために、チームはまずCollege BoardのCollege Searchツールを使って中西部の教育機関一覧を作成しました。次に各校のウェブサイトを手作業で訪問し、タイトルに「data」を含むプログラムを検索して、構造化されたスプレッドシートに詳細を記録しました。各プログラムについて、州、学校、都市、プログラム名、対面かオンラインか、レベルとタイプ、専攻・副専攻・証明書かどうかを記録しました。専攻と副専攻は別個の提供物として扱い、どの学部が公式に責任を持っているかを注意深く確認しました。学部の管轄が不明瞭な場合は、コース一覧や科目タグを使ってカリキュラムが本当に数学と計算を融合しているかを推定しました。手作業の後に、Pythonコードを使ってデータをクリーンアップし、重複を除去し、カテゴリの一貫性を保ち、矛盾や欠落情報にフラグを立てました。
中西部についてデータセットが示すこと
最終的なコレクションは225の学区から404のユニークなプログラムを含みます。そのうち過半数がData Scienceに分類されており、多くの中西部機関がより技術的で数学・コンピューティングに重点を置くモデルを採用していることを示唆しています。約3分の1はData Analyticsに該当し、しばしばビジネス、情報、技術系ユニットに結びついており、数学とコンピュータサイエンスの両方に同等の重点を置かない傾向があります。Interdisciplinary Data ScienceやData Science as a Concentrationは規模は小さいものの重要な部分を占めており、ビジネス、工学、社会科学などとデータ技能を融合しようとする試みを反映しています。著者らはまた学校をコミュニティカレッジ、工科・工学校、大学、その他のカレッジに分類しており、大学が提供数を支配する一方で、コミュニティカレッジや工科校はData Analyticsプログラムに傾きがちであることを示しています。
他者がこの資源をどう活用できるか
データセットはHarvard Dataverseで公開され、処理と検証に用いられたコードとともに再利用を意図しています。政策立案者は、労働力育成への投資を計画する際に、州別や学校タイプ別のデータ関連プログラムの分布を検討できます。学部長やカリキュラム設計者は、自校のプログラムを近隣や同種の他校と比較するベンチマークとして利用できます。教育研究者は、特にAIツールが教室や職場に深く組み込まれていく過程で、プログラム名、構造、運営体制が時間とともにどのように変化するかを追跡できます。教員は授業プロジェクトでこのデータを使い、学生に実際の教育環境を探らせることもできます。
平たく言えばこの研究が伝えること
本稿は本質的に、生成型AIブーム直前に中西部の大学がどのようにデータ技能を教えていたかについての整理された地図を提供します。異なる種類の「データ」プログラムを明確に区別し、誰がそれを運営し何を求めているかを記録することで、著者らは急速な技術変化に教育がどう追随するかを理解するための基準点を示します。数年後には、このスナップショットがプログラムがより技術的になったのか、より学際的になったのか、あるいはAIによってどのように形づくられたのかを示す手がかりとなり、学校や地域社会が学生をデータ主導の世界にどう備えさせるか判断する際の指針となるでしょう。
引用: Blackford, D., Maria Selvitella, A. Data science academic programs in the pre-ChatGPT erain the Midwestern United States: a curated dataset. Sci Data 13, 236 (2026). https://doi.org/10.1038/s41597-026-06553-4
キーワード: データサイエンス教育, 学術プログラム, 中西部の大学, データ分析学位, 高等教育データセット