Clear Sky Science · ja
一般向け医療アシスタントとしての大規模言語モデルの信頼性:無作為化事前登録研究
なぜあなたのスマホが最初の医師に最適とは限らないのか
体調が悪いときに、心配すべきかどうか、症状が何を意味するのか、病院に行くべきかをすばやく知りたいと考えて、AIチャットボットに頼る人が増えています。本研究は単純だが差し迫った問いを投げかけます:一般の人が自宅で強力な言語モデルを医療アシスタントとして使うとき、本当により適切な健康判断が下せるのか――それとも技術が誤った安心感を与えてしまうのか?
実生活風の症例でスマート機械を検証する
これを確かめるため、英国の研究者は突発的な激しい頭痛や呼吸困難など、私たちが直面する可能性のある一般的な状態に基づく現実的な医療ストーリーを10件作成しました。経験豊富な医師チームが各ストーリーに対する最適な「次の一手」を合意し(自宅療養から救急車要請まで幅広く設定)、注意深い人が考慮すべき主要な疾患を列挙しました。次に英国全土から集めた1,298人の成人を無作為に四つの選択肢のいずれかに割り当てました:主要な3つのAIチャットボットのいずれかを使うか、あるいは通常自宅で頼る検索や個人的経験といった方法を使うかです。
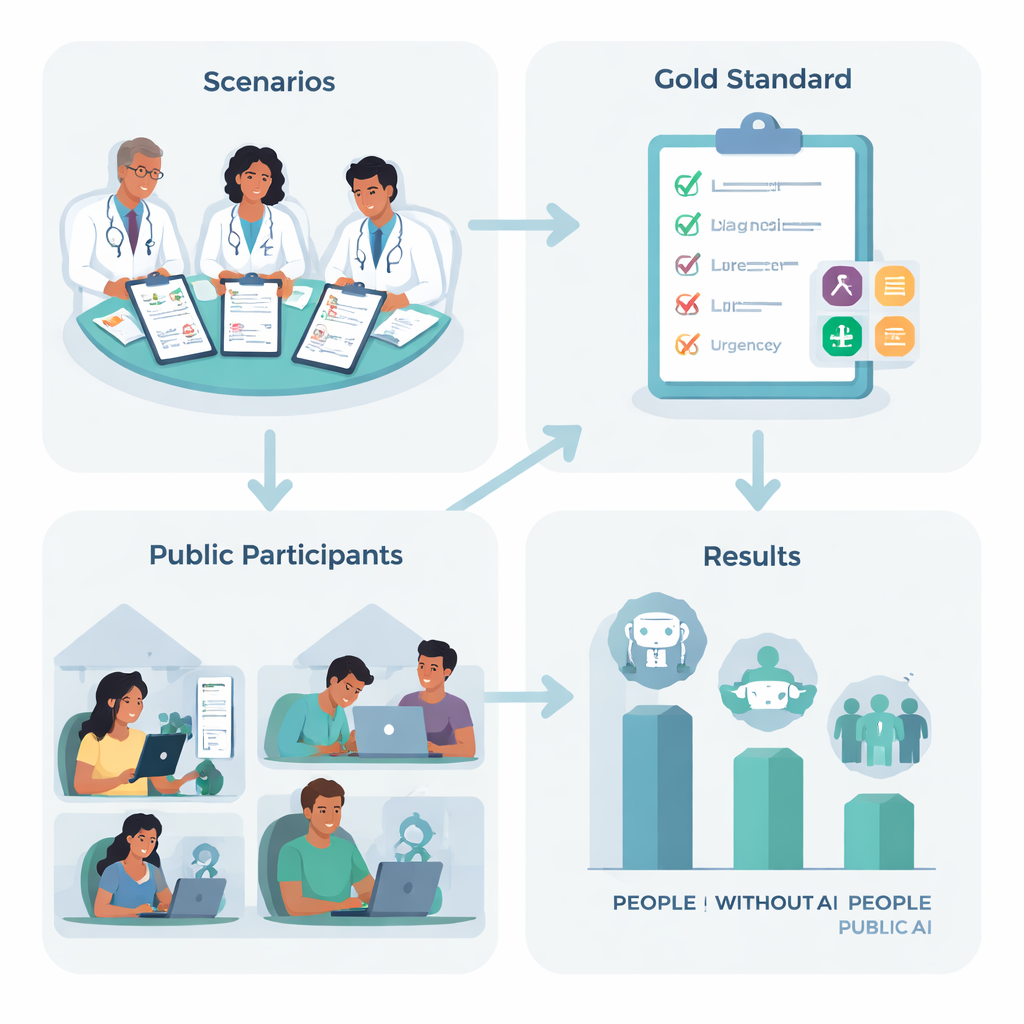
人と機械の成績――個別と連携の両面で
言語モデルを単独で評価した場合、つまりケースの全文を与えて直接診断と推奨行動を求めたとき、印象的な成果を示しました。3システムを通じて、少なくとも一つの関連する医療的状態を正しく示した割合は約95%で、適切な緊急度を選んだ割合は半数以上に達し、ランダムな推測よりはるかに優れていました。書面上では、これらのシステムは心配する患者を導く有力な候補に見えました。
AIの助言が現実の人に出会うとき
しかし、日常のユーザーが介在すると状況は変わりました。AIを使った参加者は、次にすべきことを選ぶ正確さにおいて対照群と変わらず、むしろ関連する基礎疾患を挙げる点では劣っていました。非AI群の人々は、チャットボット利用者に比べて正しい疾患を特定する確率が約1.8倍高かったのです。すべてのグループで大多数の参加者が事態の深刻さを過小評価していました。言い換えれば、高度な言語モデルにアクセスできても、人々が自分の症状をよりよく理解する助けにはならず、安全な選択へと明確に導く結果にはなりませんでした。
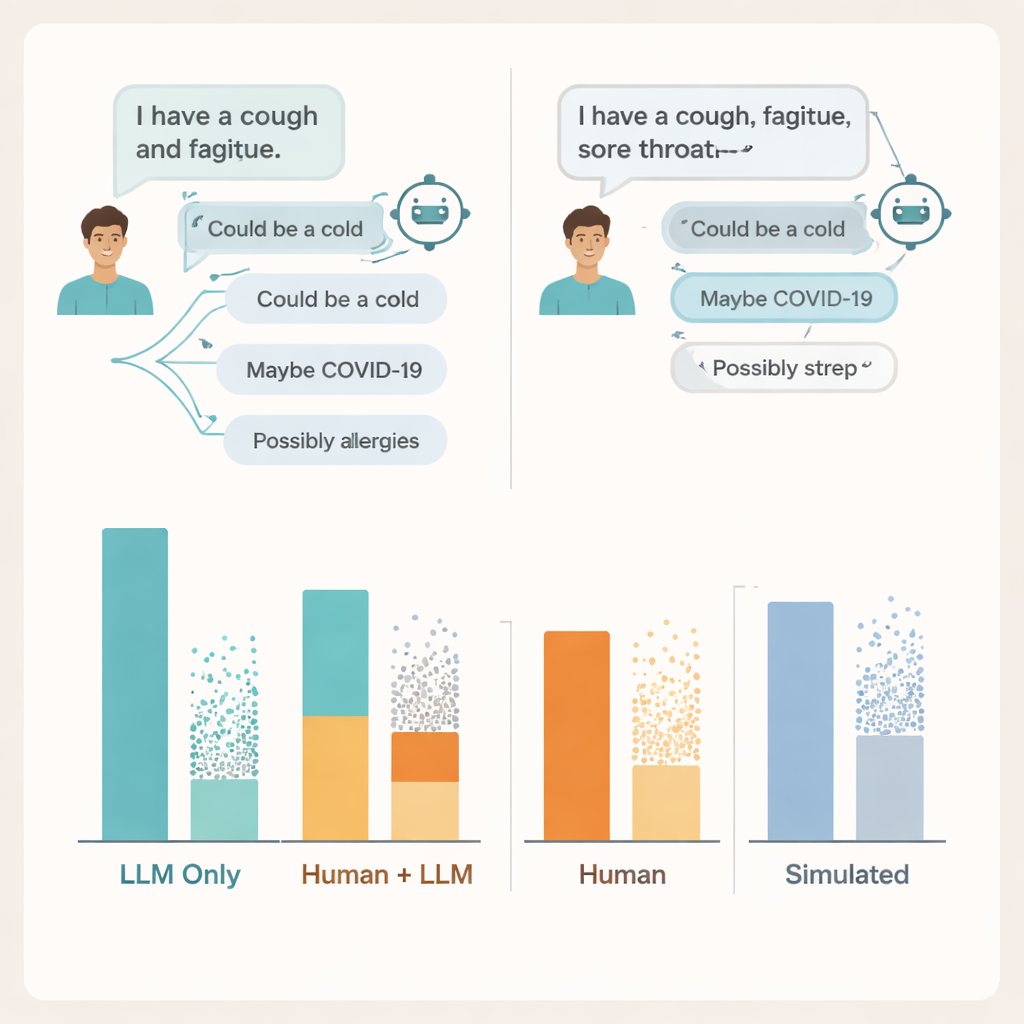
会話が破綻する理由
研究者たちはその理由を突き止めるために実際のチャットの記録を詳しく調べました。そこで会話の両側に問題があることが明らかになりました。多くのユーザーはAIが的確な助言を出すのに十分な症状の詳細を共有しませんでした――患者が医師に話すときに重要な情報を省くことがあるのと同様です。モデルは多くの場合少なくとも一つの関連疾患を挙げていましたが、誤りや気を散らす複数の可能性も追加し、ユーザーはどの提案が重要か見極めるのに苦労しました。場合によっては、ほとんど同じ症状の説明に対して同じモデルがまったく異なる助言を返すことがあり、人々が画面上の情報をいつ信用すべきかをはっきり理解するのを困難にしていました。
なぜ標準的なテストは現実のリスクを見落とすのか
チームはこれらの結果を二つの一般的な医療AIの評価方法――選択式試験問題と、二つのモデル間で行う完全にシミュレートされた「患者」チャット――と比較しました。どちらの方法でもシステムは再び強力に見え、試験形式の問題で合格圏内あるいはそれ以上の得点を出し、シミュレート患者との会話では実際の患者よりも良好に振る舞いました。しかし高得点や磨かれた模擬会話は、同じツールを使った現実の人々の成績と一致しませんでした。著者らは、知識を孤立してテストするベンチマークは、現実の人間とAIのやり取りが持つ混沌とした脆弱性を見逃していると主張します。
これは患者と医療システムに何を意味するか
現時点で研究の結論は、現在の汎用言語モデルは一般向けの無監督な一次相談役としては準備が整っていない、というものです。確かに大量の医療知識を含んでいますが、不安な人々が自宅で断片的で混乱した質問を入力する状況では、その知識が安全な選択に自動的に結びつくわけではありません。医療のような重大な場面でAIを真に役立たせるには、優れた試験成績以上のものが必要であり、慎重な設計、多様な実ユーザーでのテスト、そして会話の中で情報がどのように収集・説明・信頼されるかに関するより厳密なチェックが求められます。
引用: Bean, A.M., Payne, R.E., Parsons, G. et al. Reliability of LLMs as medical assistants for the general public: a randomized preregistered study. Nat Med 32, 609–615 (2026). https://doi.org/10.1038/s41591-025-04074-y
キーワード: 医療チャットボット, 自己診断, ヘルスケアAI, 患者の意思決定, 大規模言語モデル