Clear Sky Science · ja
検索拡張型言語モデルによる科学文献の統合
なぜ科学についていくのがこれほど難しいのか
毎年、何百万もの新しい科学論文がオンラインに出現します。どの研究者もそれらをすべて読むことは不可能でありながら、重要な医療治療法、気候に関する洞察、技術的なブレークスルーがこの情報の洪水に埋もれていることがあります。本稿は、進んだAIシステムがこうした研究の海を検索し、信頼できる明確な要約へと編んでいく手助けができるか――しかも事実をでっち上げずに――を検討します。
新しいタイプの研究アシスタント
著者らはOpenScholarを紹介します。これは科学文献を読み、統合するために特化して設計された人工知能システムです。汎用チャットボットとは異なり、OpenScholarは約4,500万本の研究論文を収めた巨大なオープンデータベース「OpenScholar DataStore」に密接に結び付いています。研究者が「浮遊ナノ粒子を冷却する方法」や「脳画像に最も適した手法は何か」といった質問をすると、システムはまずこのデータベースを探索して関連する抜粋を探し出し、続いて人間のレビュー論文のように行内引用を付けた回答を作成します。これを数回繰り返し、草稿に対する自己批評と修正を行って、明瞭さ、網羅性、引用の質を高めます。
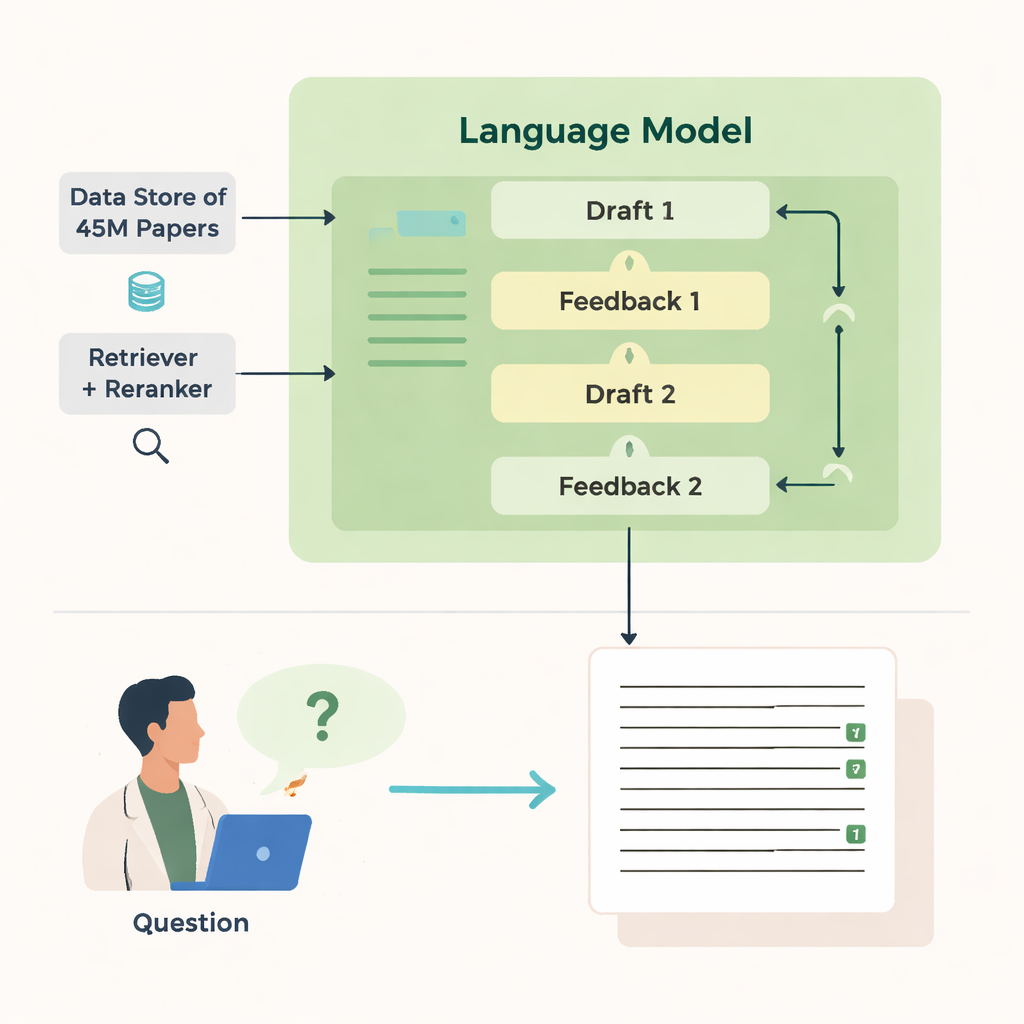
どのように検索し、書くか
OpenScholarの力は複数の連動する要素から生まれます。「リトリーバー」モジュールは、何百万もの論文から事前に計算されたテキスト埋め込みを走査して有望な抜粋を見つけ、「リランキング」モジュールがそれらを再順位付けして最も関連性の高いものに焦点を当てます。言語モデルはその証拠を用いて番号付きの参照を含む長文の回答を生成します。最初の草稿の後、モデルは自分自身にフィードバックを生成し――不足している視点、構成の弱点、裏付けの薄さを指摘し――必要に応じてより的を絞った検索を起動します。次に回答を書き直し、新たな論文を織り込みつつ引用を調整します。最終チェックでは、裏付けを要する記述に対して少なくとも一つの検索で得られたソースが付いていることを確認します。
主張と引用を検証する
OpenScholarが実際に役立つかを確かめるため、著者らはScholarQABenchという大規模なベンチマークを作成しました。これは実際の文献レビューの質問を模したもので、コンピュータサイエンス、物理学、神経科学、生命医科学にまたがるほぼ3,000件の専門家が作成した質問と数百件の長い回答を含みます。重要なのは、これらの質問は通常、一つの抄録だけでなく複数の論文を読むことを要求する点です。チームは事実の正確さ、重要点の網羅性、文章の明瞭さ、引用が基礎となる論文をどれだけ正確に反映しているかといった複数の軸で評価しました。自動チェックと、博士レベルの専門家による詳細な査定を組み合わせ、AI生成の回答と人間が書いた回答を比較しました。
強力なチャットボットを上回り、専門家に匹敵する成果
このベンチマーク上で、OpenScholarは標準的な言語モデルや、単に検索機能を汎用チャットボットに付けた従来のツールを上回りました。完全にオープンデータで訓練された小容量の80億パラメータ版は、より大きな独自モデルを使うGPT-4oや競合システムのPaperQA2よりも、多論文を統合する要求の高い課題で良好な成績を示しました。注目すべき発見の一つは、一般的なチャットボットがどれほど頻繁に参照文献を誤記するかという点です:それらの引用リストは78~90%のケースで存在しない論文や主張を裏付けない論文を含んでいました。対照的に、OpenScholarの引用の正確性は専門家に匹敵しました。専門家が回答を直接比較したところ、OpenScholar-8Bは専門家の書いた回答と比べて約半分の割合で好まれ、GPT-4o上に構築したOpenScholarパイプラインは約70%で好まれました。主な理由は、AIがより関連する研究を多く取り上げ、明確に整理していたためです。
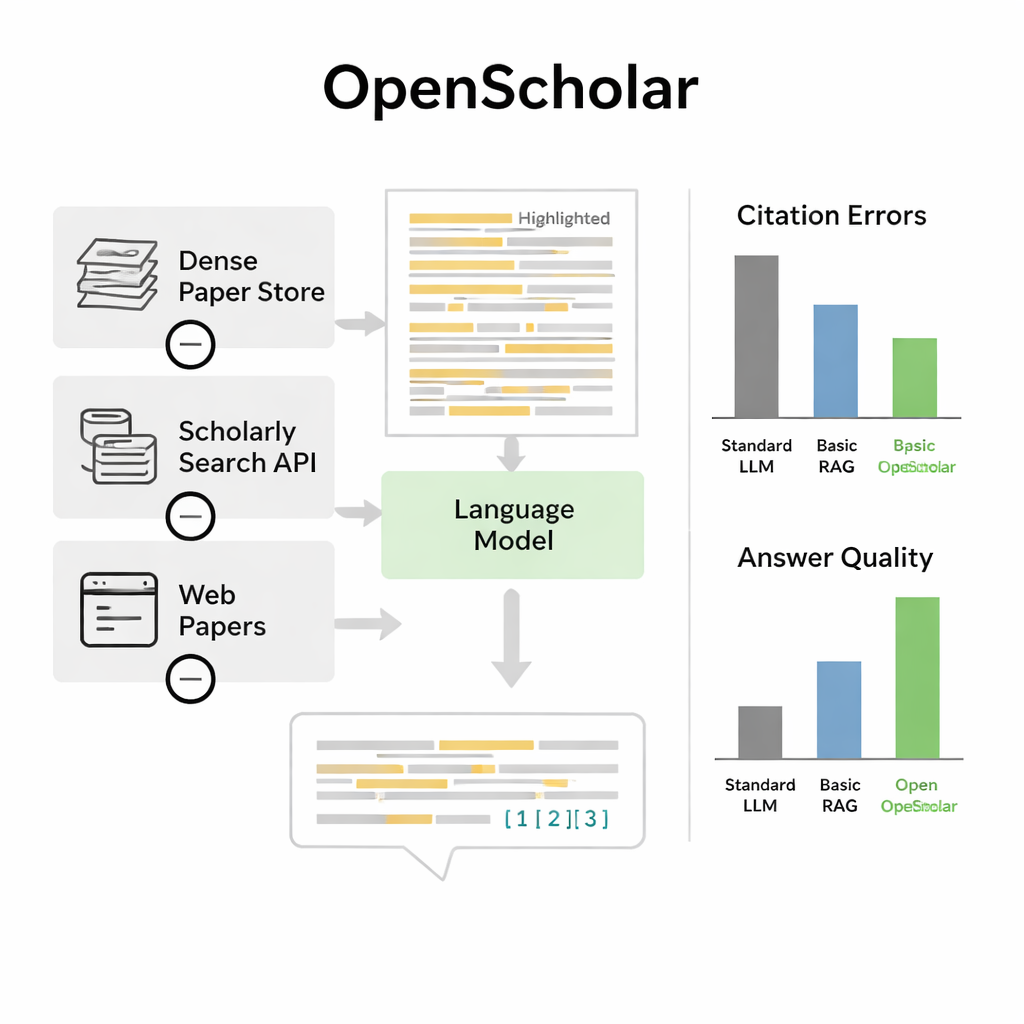
限界と今後の改善点
これらの進展にもかかわらず、著者らはOpenScholarが科学者の代替になるものではないと強調します。システムは依然として代表的な論文を見落としたり、重要度の低い研究を過度に強調したり、特に小型のモデルでは事実誤認を導入する可能性があります。ベンチマーク自体にも限界があります:主にコンピュータサイエンス、生命医科学、物理学に焦点を当てており、専門家の時間が高価なため慎重に注釈付けされた質問はまだ比較的少数です。評価はまた、引用が本当に基礎的な仕事を浮き彫りにしているか、あるいは回答が実際に新しい実験を導くかといったより微妙な資質を完全に捉えるのが難しいという問題に直面しています。
日常の科学にとっての意味
非専門家にとっての主な結論は、慎重に設計されたAIツールは、実データに結び付けられ、証拠と透明性に関する厳格な基準に従う限り、既に研究者が科学文献をより効果的にナビゲートするのを助けられる、ということです。OpenScholarは、検索し、検証し、実際の論文を引用するように基盤から構築され、その性能が人間の専門家と比較して検証されると、読みやすいだけでなく検証可能な文献要約を生成できることを示しています。実務では、そのようなツールは研究者が実験の設計や結果の解釈により集中できるようにしつつも、何が真実で重要かを判断する最終的な責任を人間が負い続ける体制を維持するのに役立つ可能性があります。
引用: Asai, A., He, J., Shao, R. et al. Synthesizing scientific literature with retrieval-augmented language models. Nature 650, 857–863 (2026). https://doi.org/10.1038/s41586-025-10072-4
キーワード: 科学文献レビュー, 検索拡張型言語モデル, OpenScholar, 引用の正確性, AI研究ツール