Clear Sky Science · ja
言語モデルが導く哺乳類代謝物の予測と発見
身体の内側に潜む化学
血液や尿の一滴には、私たちの食事や生活習慣、病気の兆候を反映する数千の微小な分子が含まれています。しかし、それらの多くについて科学者は名前や機能を把握していません。本論文はDeepMetという人工知能システムを紹介します。DeepMetはこれらの分子の“言語”を読み取り、現在のヒトや動物の化学地図に欠けていると思われる分子を予測します。最も有望な候補に実験を誘導することで、DeepMetはこの化学的ダークマターの解明を助け、身体の仕組みをより深く理解する手がかりを提供します。
なぜ多くの分子が未知のままなのか
現代の機器は、組織試料中の何千もの分子を同時に秤量し、部分的な指紋を取得できます。しかし、これらの指紋を正確な構造に変換するのは困難です。既存のデータベースには多くの既知の代謝物が登録されていますが、実際の試料で観測される信号の多くはこれらのカタログに一致しません。この差は代謝地図が不完全であり、多くの哺乳類由来の天然分子が未記述であることを示唆します。著者らは既知の代謝物から学び、欠けている最もありそうな分子を想像できるツールを構築しようとしました。それはちょうど言語モデルが文中の次の語を予測するのと同じような発想です。
代謝の文法を機械に教える
研究チームはDeepMetというニューラルネットワークを、約2,000の確立されたヒト代謝物で学習させ、各分子をその構造を表す短い文字列として符号化しました。まず薬物様分子で一般的な化学ルールを学習させ、その後で代謝物集合に対してファインチューニングを行いました。新たな構造を生成するように求めると、モデルは実際の代謝物と同じ化学空間の領域に位置する分子を生み出し、明示的に教えられていないにも関わらず多くの既知の酵素反応タイプを再現しました。言い換えれば、DeepMetは糖やアミノ酸のような基本的な構成要素を生物学的に妥当な小分子につなげる「書かれていない文法」を内部化しているように見えました。
どの新規分子が実在しそうかを予測する
研究者らは次にDeepMetから10億個の候補分子をサンプリングし、各ユニークな構造が何回出現したかを数えました。頻繁に繰り返される構造ほど既知の代謝物に似ており、共通の化学コアを共有し、妥当な酵素変換に合致する傾向がありました。これら高頻度候補が実在する分子に対応しているかを検証するため、チームはモデルの学習データが終了した後にHuman Metabolome Databaseに追加された代謝物とDeepMetの予測を比較しました。DeepMetはそうした後発の発見の多くを既に生成しており、多くを有力候補として高くランク付けしていました。データベースに存在しない上位ランクの構造群から著者らは80種を購入または合成し、質量分析で実際のヒト試料を検査しました。その結果、既存の文献に出ているにも関わらず見落とされていたものを含め、いくつかの未認識の代謝物の存在が確認されました。
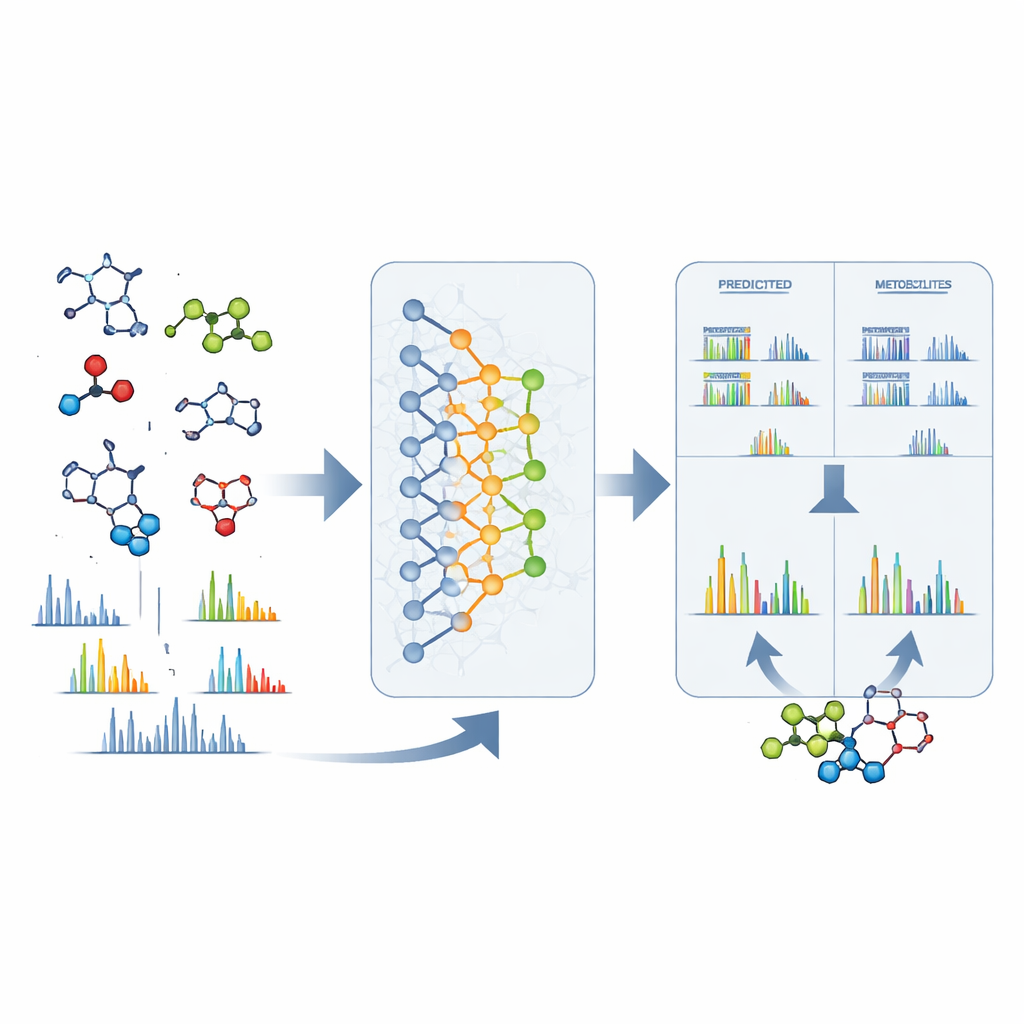
生の信号から具体的な構造へ
DeepMetは、質量分析計で未知のピークが観測された後でも有用です。未知分子の正確質量のみが分かっている場合、モデルは同じ質量を持つ多くの構造を列挙し、それらをどれだけ代謝物らしいかで順位付けできます。テストケースのほぼ3分の1では、正解構造が最上位に来ました。さらに多くの場合では、正解はごく少数の高ランク候補の中に含まれ、通常はモデルの第一候補と形状が非常に似ていました。絞り込みを進めるために、著者らはDeepMetを各候補が質量分析でどのように断片化するかを予測する別のソフトウェアと組み合わせました。これらの予測パターンを実験スペクトルに合わせることで、同定精度はほぼ2倍になりました。この統合的手法で大規模な公開データセットを探索すると、多くの以前は匿名だった信号に対する仮の構造が得られ、病気や食事、マイクロバイオーム状態で異なる代謝物が示唆されました。
生命の化学的ダークマターを照らす
データから学んだ化学的直感と質量スペクトルに対する強力なパターン照合を融合することで、DeepMetは新しい代謝物をターゲットを絞って実用的に発見するためのロードマップを提供します。すべての未知分子を今すぐ明らかにできるわけではありません—学習したものからあまりにも離れた構造や、特殊な手法なしには区別できない立体異性体も存在します。しかし本研究は、言語モデル様のツールが現実的な分子を創出するだけでなく、後に生物学者が動物やヒトで確認するような実在の化合物を予測できることを示しています。一般向けの要点は、AIが今や化学者の手助けをして私たちの体内に潜む隠れた化学を体系的に明らかにし、新たなバイオマーカーの発見、食事—微生物—宿主の関係の追跡、そして今日の代謝のダークマターを将来の詳細に記された生物学へと徐々に変えていく可能性がある、ということです。
引用: Qiang, H., Wang, F., Lu, W. et al. Language model-guided anticipation and discovery of mammalian metabolites. Nature 651, 211–220 (2026). https://doi.org/10.1038/s41586-025-09969-x
キーワード: メタボロミクス, 化学言語モデル, DeepMet, 質量分析, 代謝のダークマター