Clear Sky Science · ja
配列から機能へのモデリングを用いた単一細胞ATAC-seqアトラス技術の評価
細胞の説明書を読む
体内のすべての細胞は同じDNAを読みますが、脳細胞、筋肉細胞、免疫細胞はまったく異なる振る舞いをします。本論文は、その多様性の核心にある問題に取り組みます。すなわち、エンハンサーと呼ばれる短いDNA配列がどのようにして特定の細胞型で遺伝子をオン・オフするスイッチとして働くか、という点です。著者らは、配列を読み取りどのエンハンサーがどの細胞で活性化するかを予測する現代のディープラーニングモデルを訓練するために必要な大規模データセットを、より安価な新しい実験技術で生成できることを示し、ゲノムの調節“文法”を真に解読する一歩に近づいています。
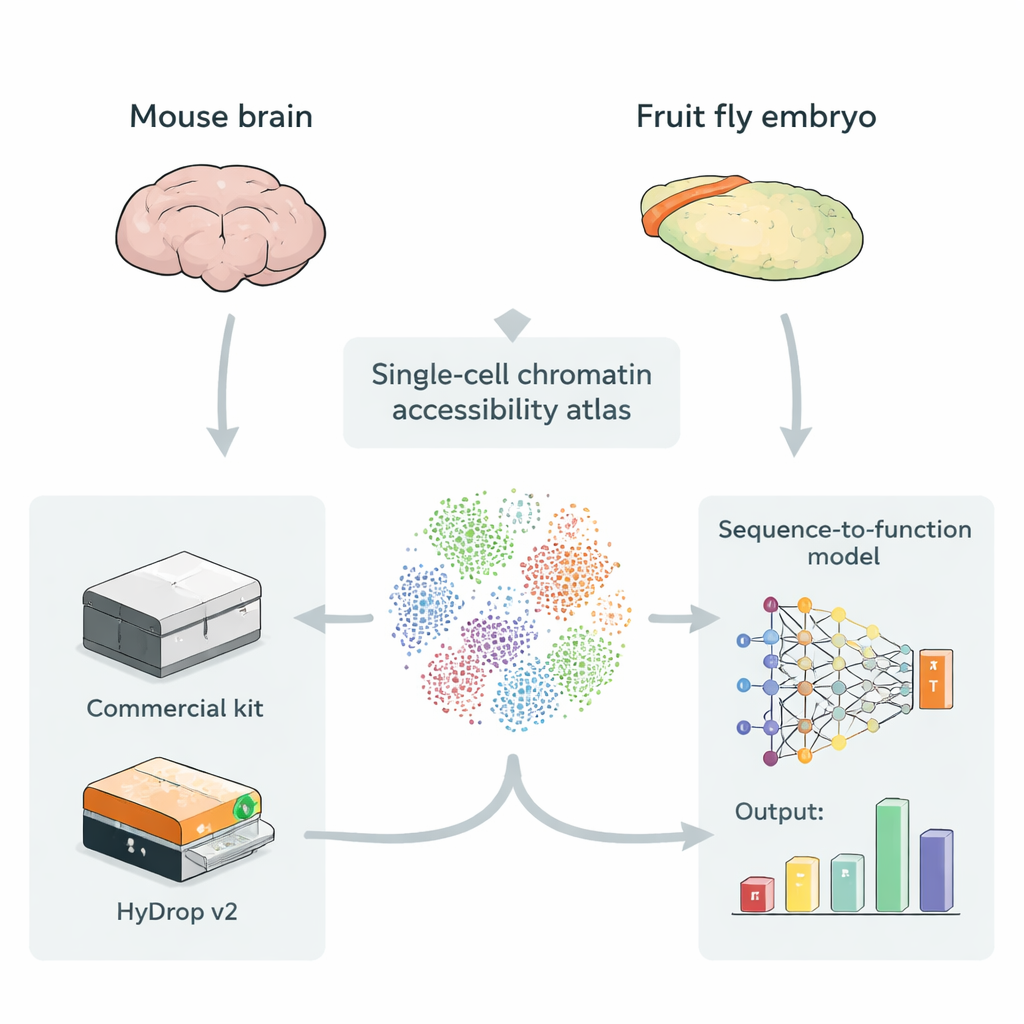
単一細胞の開放されたDNAの地図を作る
エンハンサーは通常、より開放的でアクセスしやすいDNA領域に存在し、調節タンパク質が結合しやすくなっています。single‑cell ATAC‑seqと呼ばれる手法は、数千から数十万の個々の細胞でゲノムのどの部分が開いているかを同時に測定し、多くの細胞型にわたるアクセス可能なDNAの「アトラス」を作成します。これらのアトラスは、生のDNA配列を入力として取り、各小領域が各細胞型でどれだけエンハンサーとして働くかを予測するディープラーニングモデルの理想的な学習材料です。しかし、これまでの多くのアトラスは高価な商用機器に依存しており、低コストのオープンソース法がこれらのモデルの訓練に等価な価値のデータを提供できるかという疑問がありました。
商用プラットフォームに代わるオープンソースの選択肢
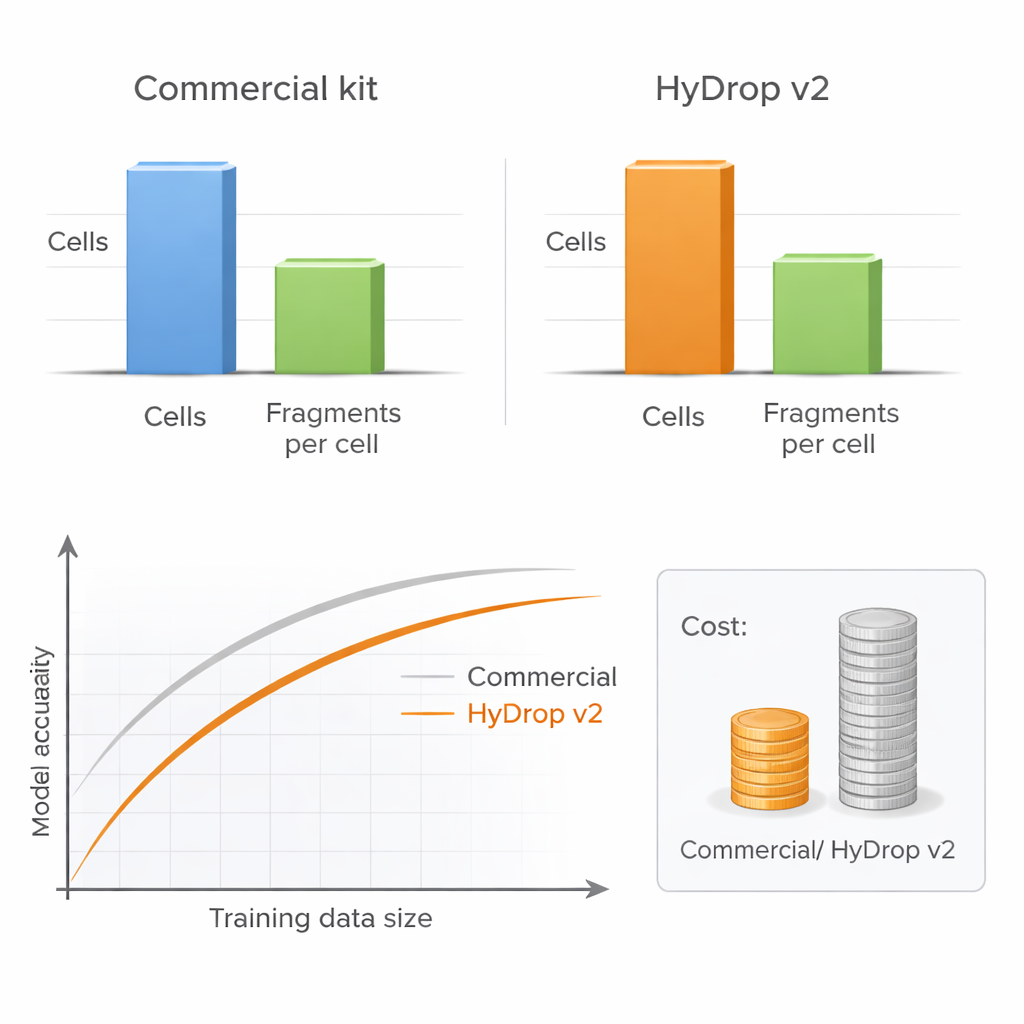
著者らは、個々の細胞をバコードするためにカスタムハイドロゲルビーズを用いる、改良型のドロップレットベースの単一細胞ATAC‑seq法、HyDrop v2を導入します。彼らはHyDrop v2を広く使われる商用キットと比較評価し、成人マウス運動皮質と胚の後期ショウジョウバエという非常に異なる二つの系から大規模アトラスを構築しました。HyDrop v2は主要な細胞型を回復し、アクセス可能なDNA領域の集合も非常に類似しており、データ品質は商用と比較できる一方で、マウス脳試料あたりのコストは約14分の1に抑えられます。重要なのは、HyDrop v2のデータは商用データとスムーズに統合できるため、研究者は非常に大規模なアトラスを構築する際にプラットフォームを組み合わせることが可能だという点です。
エンハンサーの論理を読むためのディープラーニングの訓練
より安価なデータが高度なモデリングに十分かどうかを検証するため、研究チームは商用アトラスまたはHyDrop v2アトラスのいずれかで配列から機能へのディープラーニングモデルを訓練しました。これらのモデルはDNA配列から直接学習して、各領域が各細胞型でどれだけアクセス可能かを予測し、特定の調節タンパク質の結合部位に対応すると思われる短い配列パターンを強調できます。マウス皮質では、HyDrop v2データで訓練したモデルは、商用データで訓練したモデルと全体的な精度および生体内で既に検証された既知のエンハンスャースイッチを回復する能力において一致しました。ショウジョウバエ胚では、両プラットフォームともに2,000塩基対の領域を詳細に解析し、神経芽細胞や筋肉遺伝子発現を制御するような組織特異的エンハンサー活性を実際に駆動する約500塩基対の中核領域を特定できるモデルを支えました。
より多くの細胞はより深いシーケンスに勝ることがある
どのラボにとっても実用的な重要な問題は、各細胞を非常に深くシーケンシングするか、多くの細胞をより低い深度でプロファイリングするか、という点です。著者らは細胞数と細胞ごとの断片数を体系的に変えて示しますが、十分な細胞数が含まれている限りシーケンス深度を中程度に下げてもモデル性能はほとんど損なわれないことを示しました。対照的に、細胞数を減らすと特に多くの細胞型を同時に評価する場合にモデル精度が明らかに低下します。HyDrop v2は細胞あたりのコストが大幅に低いため、研究者は数万の追加細胞を容易に加えることができ、商用ベースのモデルの性能を回復あるいは上回ることが少ない費用で可能になります。
DNA上のタンパク質のフットプリントを見る
研究はまた、異なる実験プラットフォームがATAC‑seq酵素のDNA切断に微妙なバイアスを導入し、タンパク質の位置を推定しようとするモデルを誤らせる可能性があるかどうかを検討します。酵素の選好性を補正する別のニューラルネットワークツールを用いて、HyDrop v2と商用キットがマウスおよびハエの細胞の両方でほぼ同一の酵素活性パターンを生成することを著者らは示しました。補正後、両データセットは調節タンパク質やヌクレオソームがDNAを切断から保護している微細な“フットプリント”を明らかにし、これらのフットプリントは配列から機能へのモデルが強調した配列パターンと整合します。この一致は、オープンソースと商用の両プラットフォームがタンパク質とDNAの相互作用を詳細に研究するのに等しく適していることを示唆します。
ゲノム解読における意義
専門外の読者に向けた要点は、個々の細胞でDNAがどのように使われているかの非常に大規模で手頃な地図を今や構築でき、それらの地図を用いて強力なディープラーニングモデルを訓練する際に高価な専有ハードウェアに依存する必要がなくなった、ということです。HyDrop v2は、十分な数の細胞がプロファイルされていれば、エンハンサー予測、配列パターンの解釈、タンパク質結合フットプリントの解析において主要な商用法と匹敵するデータを提供します。これは、健康と疾病における調節要素の生物全体規模のアトラスを構築する道を開き、ゲノムの調節指示を読み解き、研究や将来の治療のために新たで精密な遺伝子スイッチを設計する取り組みを加速します。
引用: Dickmänken, H., Wojno, M., Mahieu, L. et al. Evaluating single-cell ATAC-seq atlasing technologies using sequence-to-function modeling. Nat Commun 17, 1951 (2026). https://doi.org/10.1038/s41467-026-68742-4
キーワード: 単一細胞ATAC-seq, エンハンサー, ディープラーニングモデル, 遺伝子制御, オープンソースゲノミクス