Clear Sky Science · ja
転移学習で代表性の低い集団へのポリジェニックスコア予測を改善する
なぜあなたのDNAリスクスコアは当てにならないかもしれないのか
遺伝的「リスクスコア」は、糖尿病や心臓病、高血圧などの一般的な疾患を発症する確率を推定するためにますます使われています。しかし、これらのスコアの多くはヨーロッパ系の人々のDNAデータを用いて作られており、その結果、他の背景を持つ人々に対しては予測精度が低くなることが多く、公平性や実臨床での有用性に関する懸念を生んでいます。本研究は単純な問いを立てます:大規模なヨーロッパ系データから得た知見を、生のデータを共有することなく代表性の低い集団向けにより良く公平な遺伝スコアを作るために再利用できるか、ということです。
何百万ものDNAマーカーから一つのリスクスコアへ
ポリジェニックスコアは、ゲノム全体に散らばる多数の遺伝マーカーの小さな効果を合算する成績表のようなものです。各マーカーには、大規模な遺伝学的研究に基づき、その形質との関連の強さを反映した重みが与えられます。これらの研究が主にヨーロッパ系で行われると、得られたスコアはヨーロッパ系で最もよく機能する傾向があります。特定のDNA変異の頻度や連鎖不平衡(変異がどのように継承されるか)など遺伝的背景の違いにより、同じ重みがアフリカ系アメリカ人やヒスパニックなどの集団ではうまく当てはまらないことが多いのです。すべての集団に対して同等の大規模データを集めるのは費用と時間がかかるため、著者らは転移学習という機械学習の戦略に着目しました:各集団で一から始めるのではなく、他で学習された既存モデルを改良するのです。
生データを共有せずに知識を借りる方法
研究チームはGPTLというオープンソースのRパッケージを開発し、遺伝スコア向けの3つの転移学習アプローチを実装しました。いずれの手法も、大規模なヨーロッパ系データセットから得られた既存のDNA効果推定値を出発点とし、そこからアフリカ系アメリカ人やヒスパニックなどのターゲット集団のデータを使って慎重にその推定を調整します。一つ目の方法は勾配降下法でヨーロッパの重みを一歩ずつ微調整し、完全に上書きする前に早期停止します。二つ目はペナルタイズド回帰と呼ばれる手法で、ターゲットデータが強い証拠を示さない限り新しい推定値を元の値に引き寄せます。三つ目はベイズ混合モデルで、各DNAマーカーが複数の情報源(複数の祖先集団や「効果なし」オプションなど)から選択し、ターゲットデータの説明力に応じてそれらを混合します。
手法を実際に試す
これらのアプローチの有効性を評価するために、著者らはコンピュータシミュレーションと、英国バイオバンクおよび米国のAll of Us研究プログラムに登録された数十万のボランティアからの実データの両方を用いました。ターゲット集団としてアフリカ系アメリカ人とヒスパニックの参加者に焦点を当て、ヨーロッパ系データを主要な事前情報源として利用しました。身長、体格指数、血中脂質、血圧、腎機能マーカーなど11の形質にわたり、転移学習したスコアは一貫してターゲット集団のみで構築したスコアや単にヨーロッパ由来のスコアを使うよりも予測性能が向上しました。しばしば、その精度は複数集団の生データを結合することを要するより複雑な「多祖先」手法に匹敵するか、わずかに上回ることもありました。重要なのは、GPTLの手法は個人レベルの遺伝データではなく要約統計(遺伝効果に関する集計値)のみを必要とするため、機関間で個人情報を晒すことなく協力が可能という点です。
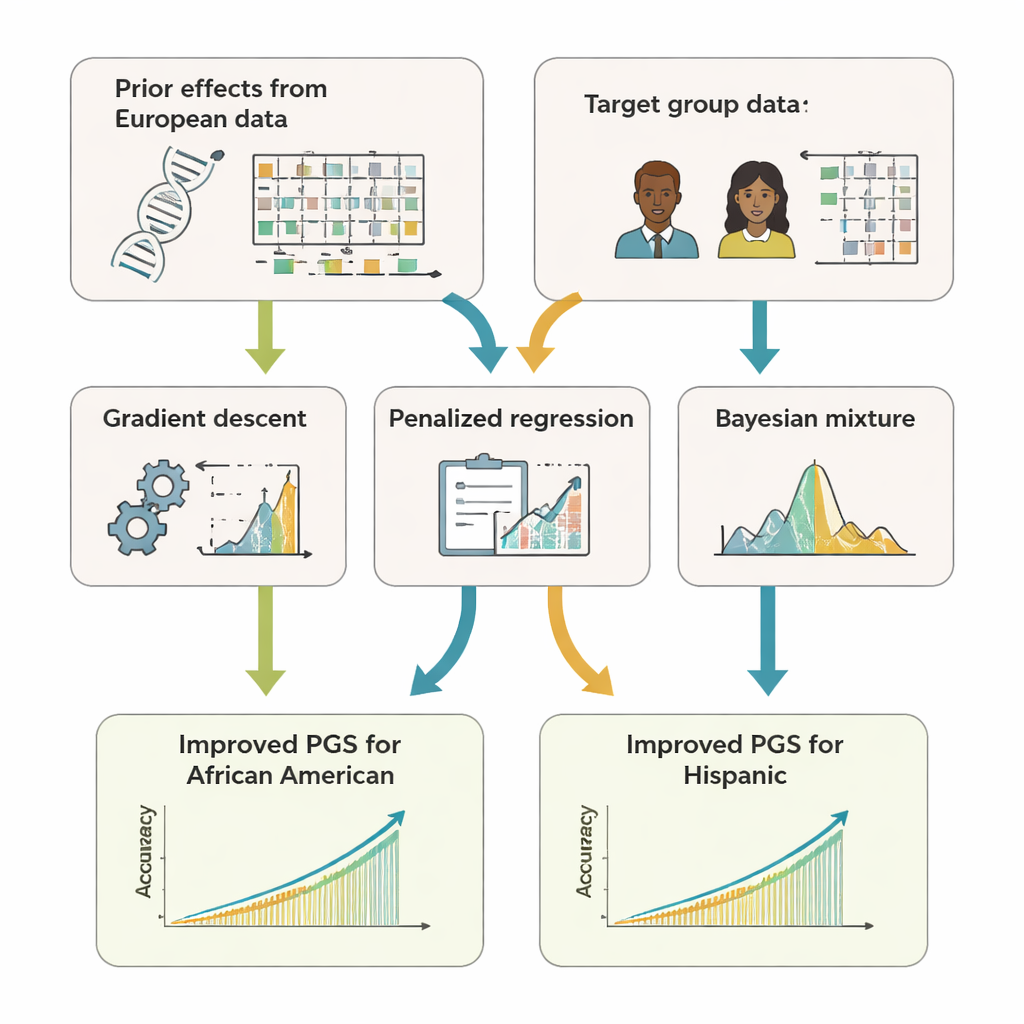
より多くのDNAが常に良いとは限らない
研究者らは、どの遺伝マーカーを含めるべきかについても検討しました。利用可能なすべてのマーカーを使えば常に有利だという一般的な考えに反し、アフリカ系アメリカ人や特にヒスパニック集団では、非常に弱い信号を数百万含めることが、遺伝相関の単純化された表現を使う場合に性能を悪化させることがあると分かりました。より支持の強いマーカーに焦点を当て、変異がどのように一緒に継承されるかに関する豊富な情報を使うことが、しばしばより正確なスコアにつながりました。また、複数の祖先集団からの事前情報を追加し、集団間の違いを注意深くモデル化することでも予測が改善しました。
公平な遺伝的リスク予測にとっての意義
非ヨーロッパ系の集団にとって、現状の既製の遺伝的リスクスコアは大きく性能が劣ることがあり、それが健康格差を拡大する可能性があります。本研究は、転移学習—既存のヨーロッパベースのスコアを代表性の低い集団の控えめなデータで賢く精練すること—がその差の多くを埋め得ることを示しています。現実には、医療機関や研究者は機関間や祖先間で生データをプールすることなく、より正確で公平な遺伝的ツールを構築できるということです。すべての形質や集団に対して単一の手法が常にベストというわけではありませんが、GPTLツールキットは、過去のモデルを固定された成果物ではなく、誰にでも適応可能な出発点として扱えば、公平な遺伝予測は技術的に到達可能であることを示しています。
引用: Wu, H., Pérez-Rodríguez, P., Boehnke, M. et al. Improving polygenic score prediction for underrepresented groups through transfer learning. Nat Commun 17, 1973 (2026). https://doi.org/10.1038/s41467-026-68696-7
キーワード: ポリジェニックリスクスコア, 転移学習, 遺伝的予測, 健康格差, 集団遺伝学