Clear Sky Science · ja
非負値行列因子分解のためのメモリ内アナログ計算
大きなデータを分割する意味
映画の推薦、写真アプリ、遺伝子解析などの日常的なサービスは、巨大な数値表の中に隠れたパターンを見つけ出すことに依存しています。その一般的な手法の一つが非負値行列因子分解(NMF)で、大きなデータ表をより解釈しやすい単純な構成要素に分解します。しかし、ユーザー数やアイテム数、ピクセル数が数百万単位に達すると、現行のデジタルチップではリアルタイム処理が追いつかなくなることがあります。本論文は、アナログのメモリ内計算アプローチがこの重い数学的処理をはるかに高速かつ低消費電力で実行できることを示し、より応答性の高い効率的なAI駆動サービスへの道を開きます。
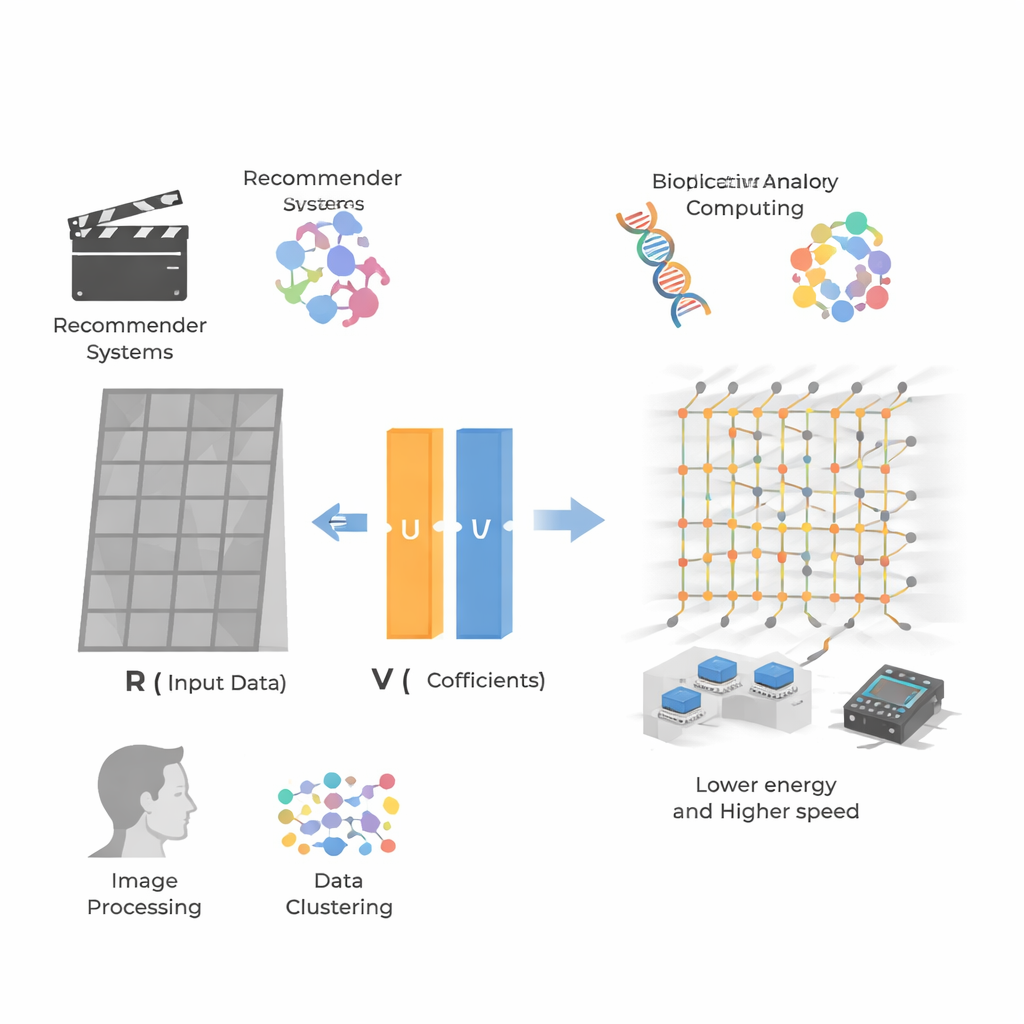
巨大な表からパターンを取り出す
本研究の中心にあるのは非負値行列因子分解(NMF)です。これは、ユーザーの映画評価や画像のピクセル値のような非負の数で構成された大きな格子を、二つのより小さな格子の積として書き換える手法です。一方の格子は隠れた「特徴」(例えばアクション嗜好とロマンス嗜好のようなユーザーの好み)を表し、もう一方は各アイテムやピクセルがその特徴をどの程度示すかを表します。全ての値が非負であるため、これらの特徴は顔のパーツや推薦データの嗜好プロファイルのように直感的な部分として現れやすく、推薦システム、バイオインフォマティクス、画像処理、クラスタリングで広く使われています。一方で、非常に大きく疎なデータセットに対しては計算負荷が大きくなります。
なぜデジタルチップは限界に達するのか
従来のプロセッサ—CPU、GPU、さらにはFPGAでさえ—は行列演算を多数の基本的なステップの連続として扱い、メモリと演算ユニットの間でデータを何度も転送します。小規模な問題ではこれで十分ですが、行や列が数百万に及ぶ現代のデータセットでは、時間とエネルギーのコストが莫大になります。ムーアの法則の鈍化や、メモリアクセスが消費電力と遅延を支配する所謂フォン・ノイマンボトルネックが、リアルタイム応用(ライブ推薦や高速画像解析など)へNMFをスケールさせることをますます困難にしています。巧妙なデジタルアルゴリズムであっても、行列を繰り返し更新する必要がある場合には多項式時間の計算量と大きなメモリトラフィックに直面します。
アナログ信号でメモリ内計算を行う
著者らは抵抗メモリ素子として知られるメムリスタを用いたアナログ行列計算という別の道を採ります。これらの素子は各接点に導電率値を格納する高密度のクロスバー配列として配置できます。配列の一方向に電圧を印加すると、他方から流れる電流が自然に多数の乗算加算操作を並列に実行します。これらの配列を少数の演算増幅器と閉ループで配線することで、研究チームはコンパクトな一般化逆(GINV)回路を構築し、多くのデジタル反復を行う代わりに事実上一つのアナログステップで回帰問題全体を解きます。導電率補償スキームで設計を洗練し、回路の安定性を保ちながら増幅器の数を大幅に削減し、チップ面積と消費電力を節約します。
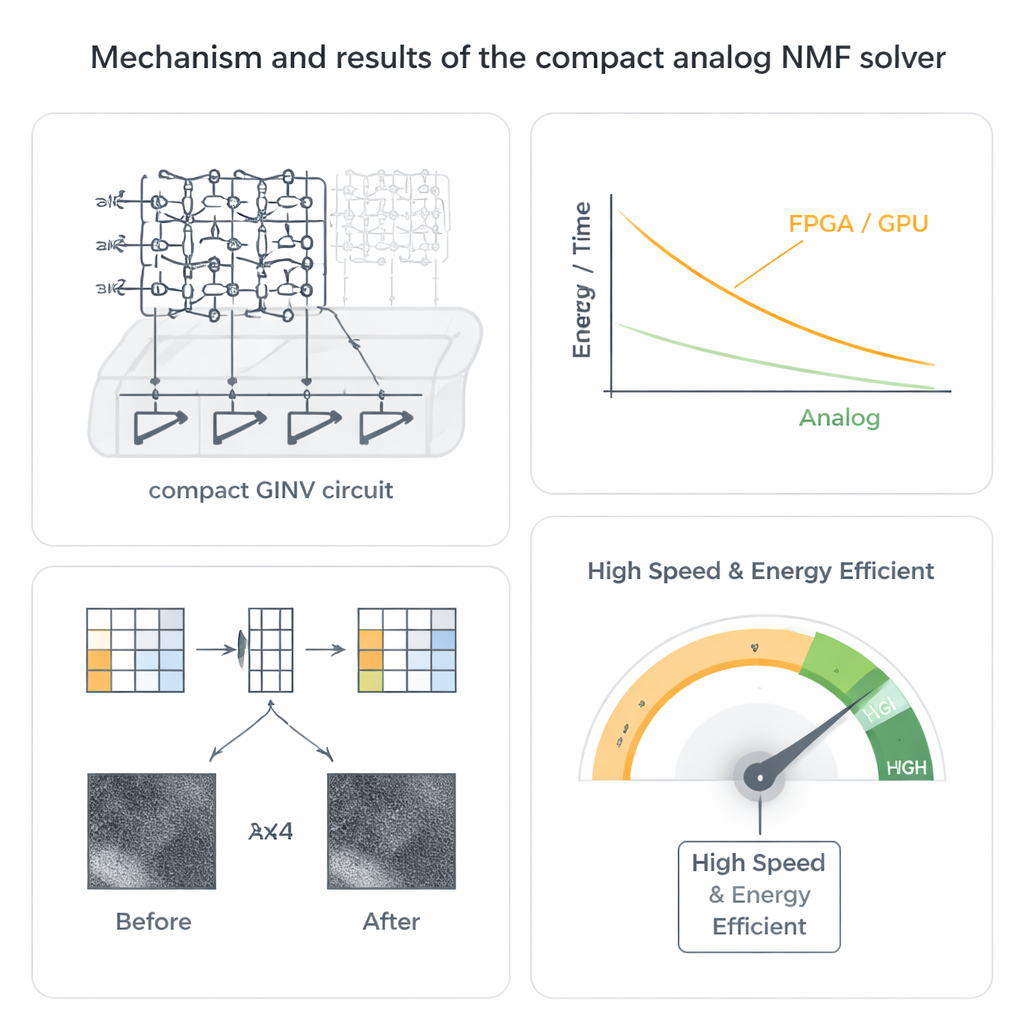
数学的トリックから動作するハードウェアへ
NMFを実用化するために、研究者らはコンパクトなGINV回路を交互非負最小二乗法として知られるよく知られた戦略と組み合わせます。両方の因子行列を同時に解こうとする代わりに—困難な非凸問題—この手法は一方の行列を固定して他方を交互に改善することで、より単純な非負回帰問題の連鎖に分解し、アナログ回路で解けるようにします。彼らはハフニウム酸化物メムリスタ配列を試作し、プリント基板プラットフォームを構築して、二つの主要な用途を実証します。画像圧縮では星雲写真を小さなパッチに分割して因子分解し、記憶容量を半分にしつつ視覚的劣化をほとんど生じさせません。レコメンダーシステムでは、MovieLens 100kのようなユーザー–アイテム評価データを因子分解し、行列が非常に疎であっても欠損評価を正確に予測します。
実世界での速度、効率、そして頑健性
基本的な正確性を超えて、アナログソルバーは驚くべき速度とエネルギー優位性を示します。クロスバーを流れる電流が多数の演算を同時に表すため、回帰問題を解く時間は行列サイズにほとんど依存しなくなり、デジタル手法とは対照的です。システムレベルの推定では、高度なFPGAやGPU実装に対して数百〜数千倍の速度向上と、エネルギー効率で数桁の改善が示唆されています。驚くべきことに、ハードウェアのアナログ的性質は弱点ではなく強みでもあります。NMFアルゴリズムはデバイスノイズやプログラミング誤差を自然に許容し、シミュレーションでは基盤となるメムリスタ値がかなり不正確であったり温度でドリフトしても、最終的な画像や推薦の品質は高く保たれます。
日常技術にとっての意味
簡潔に言えば、この研究は新しい種類の「メモリ内電卓」が、現代データサイエンスの主要な手法の一つを、現行のデジタルチップよりもはるかに高速かつ効率的に処理できることを示しています。行列因子分解をコンパクトなアナログ回路に直接組み込むことで、ストリーミング推薦、パーソナライズされたコンテンツランキング、デバイス上での画像処理といったサービスが、より低い消費電力でリアルタイムに動作する可能性があります。本研究は回路の設計図と実験的な証拠の両方を提供し、アナログ・メモリ内計算が実用的なデータセットをフル精度ソフトウェアに近い精度で処理できることを示しており、将来、大量のデータストリームを光がガラスを通るように容易にふるい分けできるハードウェアへの道を指し示しています。
引用: Wang, S., Luo, Y., Zuo, P. et al. In-memory analog computing for non-negative matrix factorization. Nat Commun 17, 1881 (2026). https://doi.org/10.1038/s41467-026-68609-8
キーワード: アナログ・メモリ内計算, 非負値行列因子分解, メムリスタ・クロスバー, 画像圧縮, レコメンダーシステム