Clear Sky Science · ja
空間・スペクトルのハイパー多重化並列回折に基づくワンショット行列-行列フォトニックプロセッサ
なぜより速く、より省エネな計算が重要なのか
デジタルアシスタントに質問したりソーシャルメディアを眺めたりするたびに、強力な人工知能モデルが舞台裏で動作しています。これらのモデルは非常に大規模化しており、従来の電子チップでは膨大なエネルギーを消費せずには追従しきれなくなっています。本稿は、重要なAI計算を電気ではなく光で実行する新しい種類の計算ハードウェアを紹介し、将来の機械をより高速かつはるかに省エネルギーにすることをめざしています。
光を計算機に変える
現代のAIは行列乗算と呼ばれる演算に依存しており、ニューラルネットワークが画像やテキストを解析する際にはこれが何十億回、あるいは何兆回と繰り返されます。電子チップはこれらを確実に実行しますが、チップ内部でデータを往復させるだけで多くのエネルギーを浪費します。本研究の着想は別の方向にあります:光そのものに計算させることです。光学ニューラルネットワークでは、情報がレーザービームに符号化され、レンズや変調器を通過する中で操作され、光センサーで読み出されます。フォトンは電子のように配線を加熱しないため、理論的にははるかに高い速度と効率に到達できます。
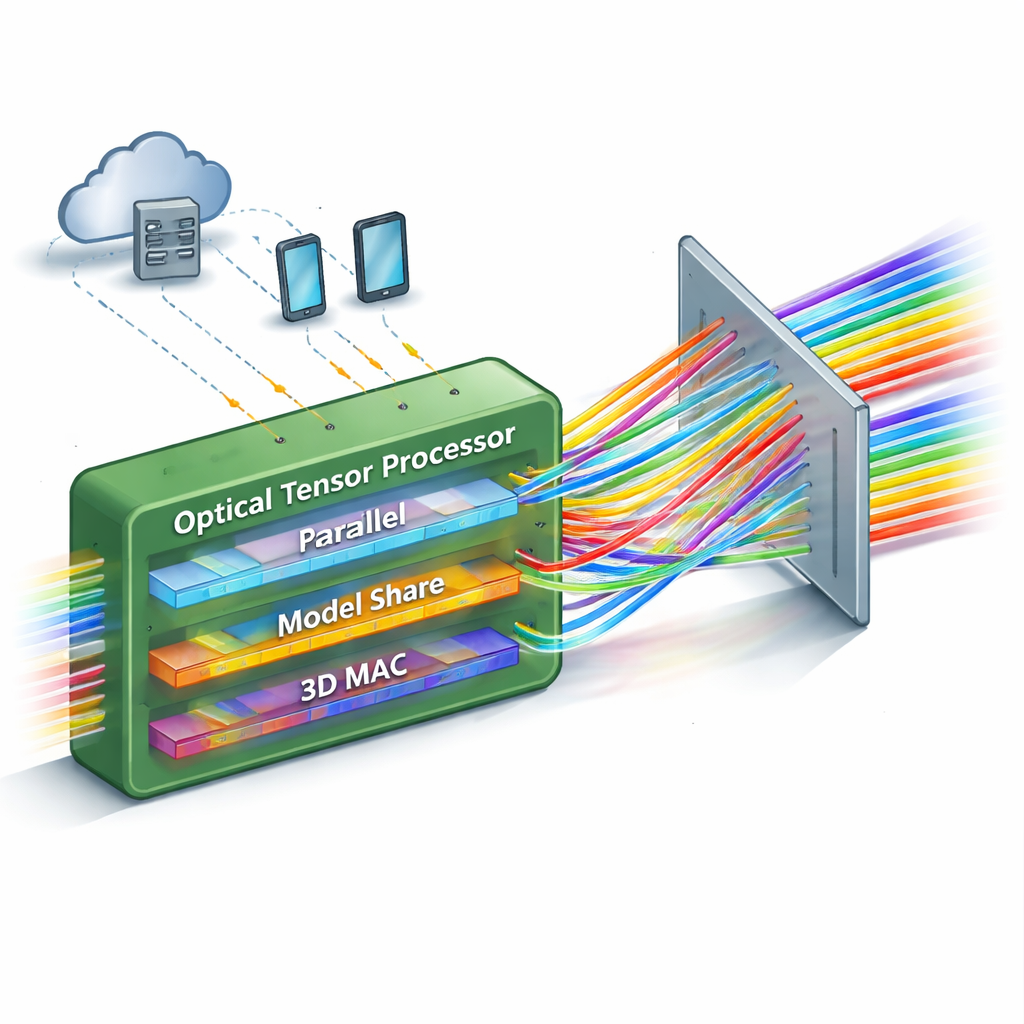
一度に多くの計算を行う
既存の光学ニューラルネットワークの多くは、並列で処理できる計算数が限定されるか、あるいは大規模化すると複雑になりすぎるという制約があります。本研究は、「ワンショット」の行列–行列フォトニックプロセッサを導入し、一度に実行できる演算数を劇的に増やします。鍵となるのは、光の三つの異なる属性――空間位置、色(波長)、時間――に同時に情報を詰め込むことです。これらの次元を精密に配置することで、デバイスは光がシステムを一度通過するだけで、数千の乗算・加算(multiply-and-accumulate)を含むフルの行列–行列乗算を実行できます。
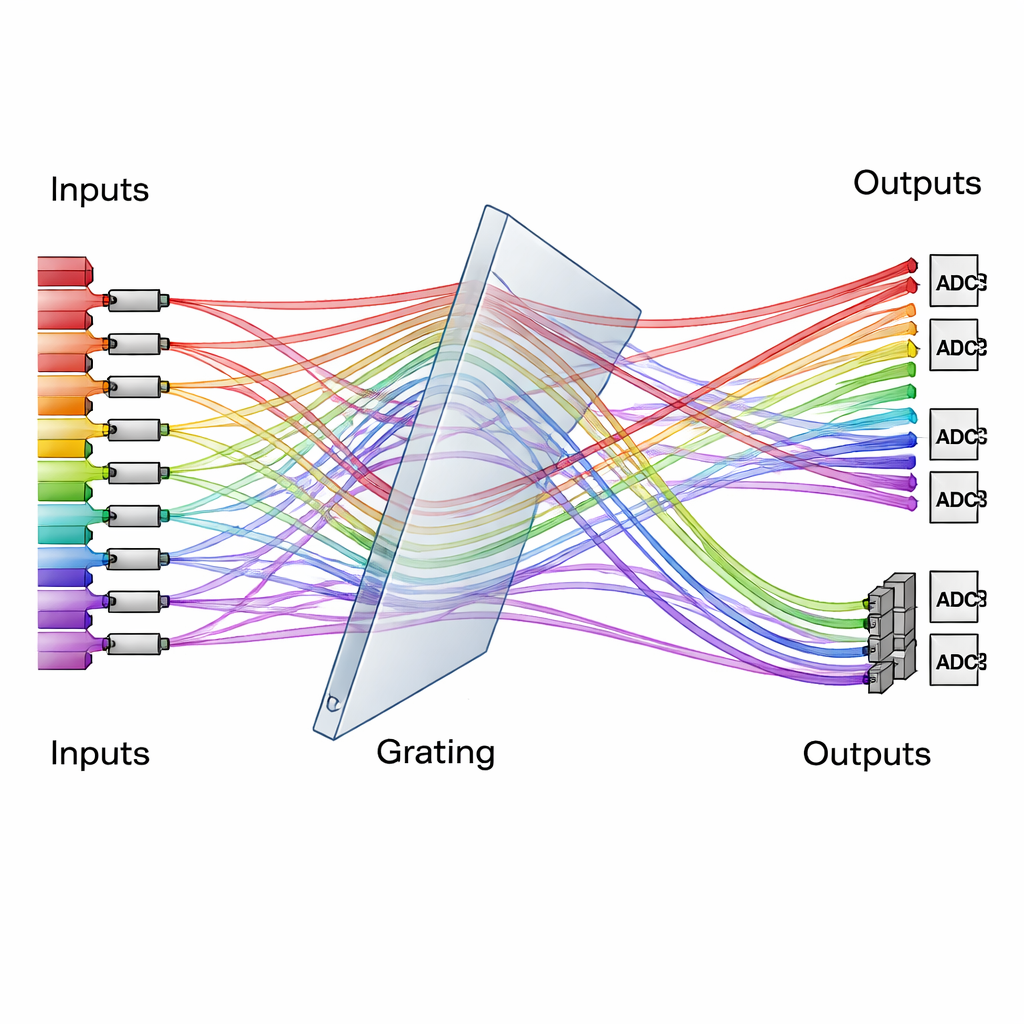
光の交通整理役としての回折格子
設計の中心には単純だが強力な光学素子、回折格子があります。回折格子は色に応じて光を異なる角度に分けます。研究チームは三次元に配置した特別な格子システムを交通整理のように用い、多数の色付きビームを多数の入力チャネルから再配置された出力チャネルへと振り分けます。処理するデータは一群の変調器上の光強度として符号化され、ニューラルネットワークの「重み」は別の変調器群に符号化されます。ビームが出会って格子を通過すると、その経路が再配置され、各出力チャネルはデータと重みの正しい組合せを自然に加算します。時間積分型検出器は複数の短い時間ステップにわたる寄与を積算し、光学系の複雑さを増やすことなく計算の規模を実質的に拡張します。
実験室セットアップから実際のAIタスクへ
著者らは16×16×16×16の光学テンソルプロセッサを実証しました。つまり16×16行列を別の16×16行列とワンショットで乗算でき、4096の基本演算を同時に実行します。システムはマルチギガヘルツのクロックレートで動作し、有効な計算精度は8ビット以上に達し、多くの実用的なAIアクセラレータと匹敵します。単なる物理実証にとどまらないことを示すために、著者らはプロセッサを用いて小規模な画像認識パイプラインの一部を動かしました:数字画像から特徴を抽出する畳み込みニューラルネットワークと、それを分類する全結合ニューラルネットワークです。光学ノイズやハードウェアの不完全性があっても、このセットアップは手書き数字を約96%の精度で正しく認識し、同じモデルの全デジタル実装に近い性能を示しました。
エネルギー消費、感度、そしてスケール可能性
このアーキテクチャは同じ光学部品を多数の並列チャネルで再利用し、信号を効率的に積算するため、各基本演算あたりのエネルギー消費は極めて小さく――乗算1回当たり数十アトジュールの光エネルギーにまで達し得ます。著者らは既に一部の最先端電子AIアクセラレータを上回る全体的なエネルギー効率を見積もっており、変調器やデジタル-アナログ変換器の小さな改善があれば、1ワット当たり数百兆の演算に到達する可能性があると主張しています。重要なのは、この設計は他の光学方式が直面するスケーリング上の障害のいくつかを回避しているため、同様の部品を用いてより多くのチャネル(例えば30×30あるいは60×60アレイ)を持つ大型版の実現が現実的に見える点です。
日常の技術にとっての意味
平たく言えば、本研究は比較的単純な光学セットアップ――回折格子を通じて色のついた光ビームを賢く経路制御する方式――が、AIスタイルの計算を強力かつ低エネルギーで担えるエンジンになり得ることを示しています。これはまだ実験室プロトタイプに過ぎませんが、将来的には光ベースのプロセッサがデータセンターやエッジデバイスで最も負荷の高いニューラルネットワーク処理を担い、電力コストを削減し、より大きく高速なモデルを可能にする方向を示唆しています。もしこのようなフォトニックテンソルプロセッサが統合・大量生産されれば、次世代の高性能で省エネルギーな人工知能ハードウェアの重要な要素になる可能性があります。
引用: Luan, C., Davis III, R., Chen, Z. et al. Single-shot matrix-matrix photonic processor based on spatial-spectral hypermultiplexed parallel diffraction. Nat Commun 17, 484 (2026). https://doi.org/10.1038/s41467-026-68452-x
キーワード: 光学ニューラルネットワーク, フォトニックコンピューティング, 行列乗算, 省エネルギーAIハードウェア, 回折格子