Clear Sky Science · ja
脂質オミクスおよび代謝物オミクスデータの統計処理と可視化におけるRとPythonのベストプラクティスとツール
実験データを分かりやすい図に変えることが重要な理由
現代の計測機器は、血液や組織の一滴から何千もの小さな分子(脂質やその他の代謝物)を測定できます。これらの測定値は、疾患リスク、治療反応、食事や加齢に対する体の反応についての手がかりを提供します。しかし、生の出力は既製の答えではなく、膨大な数値テーブルであり、洗浄、解析、理解しやすい図に変換する必要があります。本稿では、研究者が広く使われている2つのプログラミング言語、RとPythonを用いて、信頼性が高く透明性のある、発表に耐える品質のグラフィックスを作る方法を説明します。
化学的測定から複雑なデータ表へ
脂質オミクスやメタボロミクスでは、質量分析やクロマトグラフィーが大規模なデータセットを生成します。各行がサンプル、各列が分子に対応するテーブルです。これらの表は教科書的に整った例とは異なり、欠測値、外れ値、極端に高い値を示すごく偏った分布を含むことが多いです。濃度は数桁にわたって変動し、年齢、性別、食事、薬剤、日内リズム、機器ドリフトやバッチ効果などの技術的要因によって影響を受けます。国際的な専門グループはサンプル採取・処理・報告の標準化ガイドラインを示していますが、優れたラボ実践があっても、この雑音の中から真の生物学的信号を引き出すためには注意深い統計処理が依然として不可欠です。
数値のクリーンアップと準備
健常群と疾患群の比較が意味を持つ前に、データを適切に準備する必要があります。レビューは、欠測値がどのように発生するか――ランダムな事故、計測限界、信号干渉など――を説明し、いつ無視できるか、再測定すべきか、あるいはk近傍法、ランダムフォレスト、単純な低値代入のような方法で妥当に推定(補完)できるかを示します。次に、バッチ効果を品質管理サンプルで補正したり、サンプル量の差を調整したりする正規化戦略を概説します。その後、対数変換のような変換(右に長い裾を整える)や、後の解析で非常に変動の大きい化合物が支配的にならないよう全ての分子を比較可能にするスケーリング手法について論じます。 
統計検定と視覚的物語
データが適切に準備されたら、さまざまな統計ツールが登場します。単一分子については、フォールドチェンジを計算し、t検定やそのノンパラメトリックな対応(マン・ホイットニー検定など)といった古典的検定を用いて群間でレベルが異なるかを問えます。複数群の比較では、ANOVAやKruskal–Wallis検定などが紹介され、どの群が異なるかを特定するための事後解析手順も示されます。これらの検定の力は、結果を明確に可視化したときに発揮されます。記事では箱ひげ図(歪んだデータ向けに改善された版を含む)、バイオリンプロット、効果量と統計的有意性を組み合わせたボルケーノプロットを強調します。脂質に関しては、系全体で同期した変化を示す脂質ネットワークや、炭素鎖長と不飽和度のパターンを明らかにする脂肪酸アシル鎖プロットなど、より専門的な可視化も説明されます。
多数の変数に一度に目を向ける
各サンプルには何百、何千もの分子が測定されるため、多変量手法が重要です。レビューは主成分分析(PCA)がこの複雑さをいくつかの新しい軸に圧縮し、主要な変動方向を捉えることで群分離、バッチ効果、解析の安定性を素早く確認できることを説明します。より高度な非線形手法であるt-SNEやUMAPは、高次元空間で微妙なクラスタや構造を露わにします。サンプルを分類することが目的の場面、たとえば患者と対照を識別する場合には、部分最小二乗法(PLS)とその直交拡張(PLS-DA、OPLS-DA)に基づく教師ありアプローチが述べられます。これらの手法は分子プロファイルをサンプルラベルに結びつけ、特徴選択を支援し、スコアプロット、ロードプロット、受信者動作特性曲線で要約されることが多いです。
RとPythonの実践的ツールキット
初心者が理論から実践へ移れるように、記事は幅広いソフトウェアパッケージのエコシステムを概観します。Rではtidyverseやtidymodelsのようなコレクションがデータ整形とモデリングを簡素化し、ggplot2やggpubr、ggstatsplot、tidyplotsといったアドオンが発表に耐える図の作成を容易にします。PCA、クラスタリング、PLSベースのモデルを扱う専門ライブラリや、複雑なヒートマップやインタラクティブなグラフィックスをサポートするBioconductorパッケージもあります。Pythonではpandasが表操作を提供し、matplotlib、seaborn、plotlyが可視化を、scikit-learnが多変量手法の幅広いスイートを担います。全体を通じて、著者らは読者がワークフローを再現し自分のデータに適用できるよう、付随するGitBookで段階的な例を提供している点を強調します。 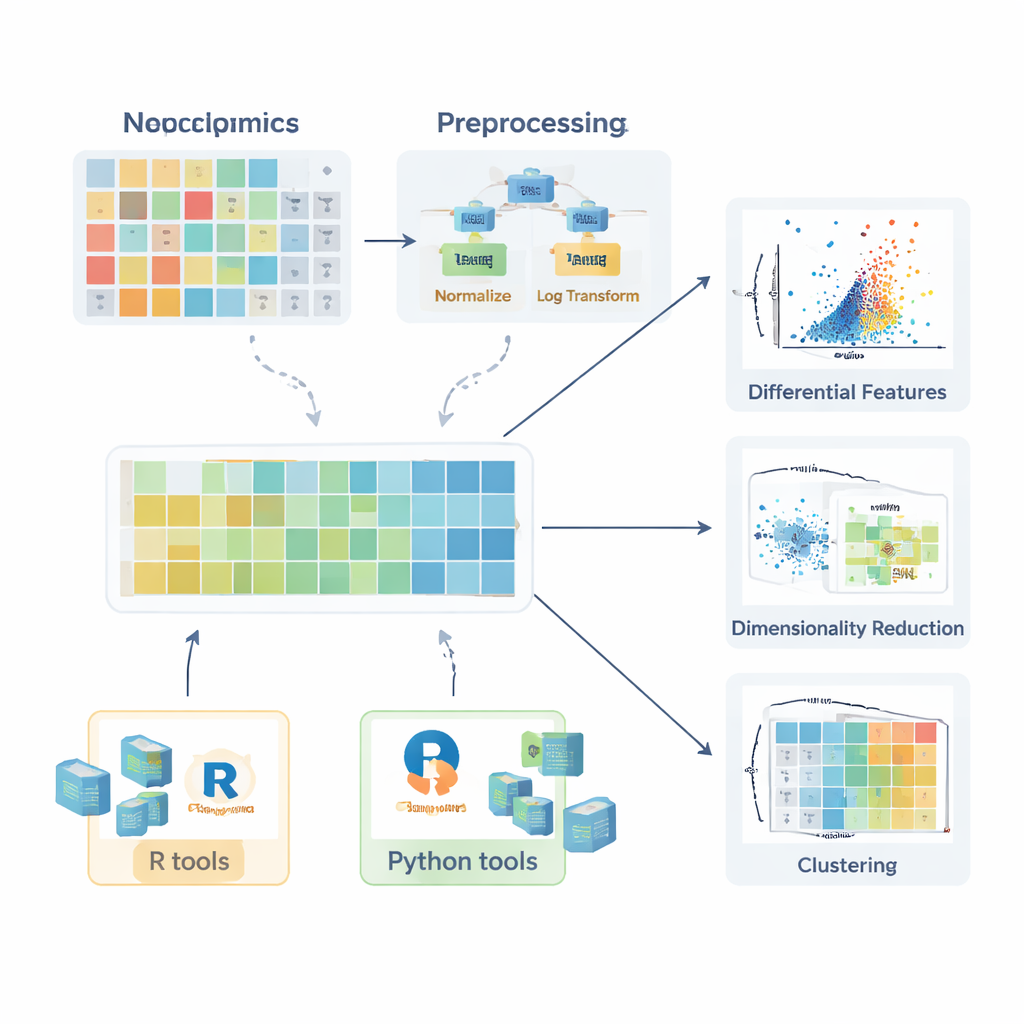
複雑な化学情報を信頼できる洞察に変える
記事の結びとして、脂質オミクスとメタボロミクスの真の可能性は強力な機器だけでなく、その出力をいかに丁寧に処理し可視化するかにあると述べています。良好な統計実践に従い、RやPythonの公開された分かりやすいツールを使い、共有されたコード例に依拠することで、研究者は堅牢で再現可能なパイプラインを構築できます。これにより、微小分子で見つかったパターンが信頼できるバイオマーカーや疾患メカニズムの理解、最終的に患者に利益をもたらすより個別化された医療へとつながる可能性が高まります。
引用: Idkowiak, J., Dehairs, J., Schwarzerová, J. et al. Best practices and tools in R and Python for statistical processing and visualization of lipidomics and metabolomics data. Nat Commun 16, 8714 (2025). https://doi.org/10.1038/s41467-025-63751-1
キーワード: リピドミクス, メタボロミクス, データ可視化, Rプログラミング, Python