Clear Sky Science · ja
Geo-TCAM: トピックモデリングと幾何学誘導空間注意を統合したタンカ自動キャプション手法
古典美術と先端技術の出会い
タンカ絵画—多くのチベット寺院で目にする鮮やかな色彩の掛け軸—は、細部にわたる装飾や重層的な宗教的意味に満ちています。専門知識のない博物館来訪者やオンライン閲覧者にとって、その象徴性の多くは理解しにくいものです。本研究はGeo‑TCAMという人工知能(AI)システムを提案します。Geo‑TCAMはタンカ画像の豊かで正確な記述を自動生成し、世界中の人々がこの独自の文化遺産をよりよく理解し保存するのを助けます。
なぜタンカ画像はコンピュータにとって難しいのか
日常的な写真と異なり、タンカ作品は意図的に密度が高く象徴性に富んでいます。一枚の絵に中心となる神像、数十の小像、文様のある縁取り、特定の手のジェスチャー、持ち物、色彩、ポーズといった、いずれも宗教的意味を持つ要素が詰め込まれます。一般の画像キャプション生成プログラムは「砂浜の犬」といった単純な場面には強い一方で、ここでは苦戦します。例えば主仏を識別しても、碗を持っているのか剣を持っているのかを見落としたり、姿勢を誤認したり、似た別の神と混同したりしかねません。こうした誤りは些細なものではなく、絵画が伝えようとする物語や教義を覆してしまい、その教育的・文化的価値を損ねます。
聖像を記述するための新しい設計図
Geo‑TCAMは三つの考えを組み合わせることでこれらの問題に対処します。多層の視覚特徴、タンカ美術に関するトピック知識、そして顔など重要領域に導く幾何学誘導の注意です。まず、深層ネットワーク(ResNet50)を用いて一つの画像を複数レベルで同時に解析します。中間層はエッジや質感、単純な形状を捉え、より深い層は全体構図を要約します。これらのレベルを融合することで、装飾のような微細な特徴と背景や人物の広がりという両方に気づけるため、単一層に依存する従来手法より豊かな視覚理解が得られます。 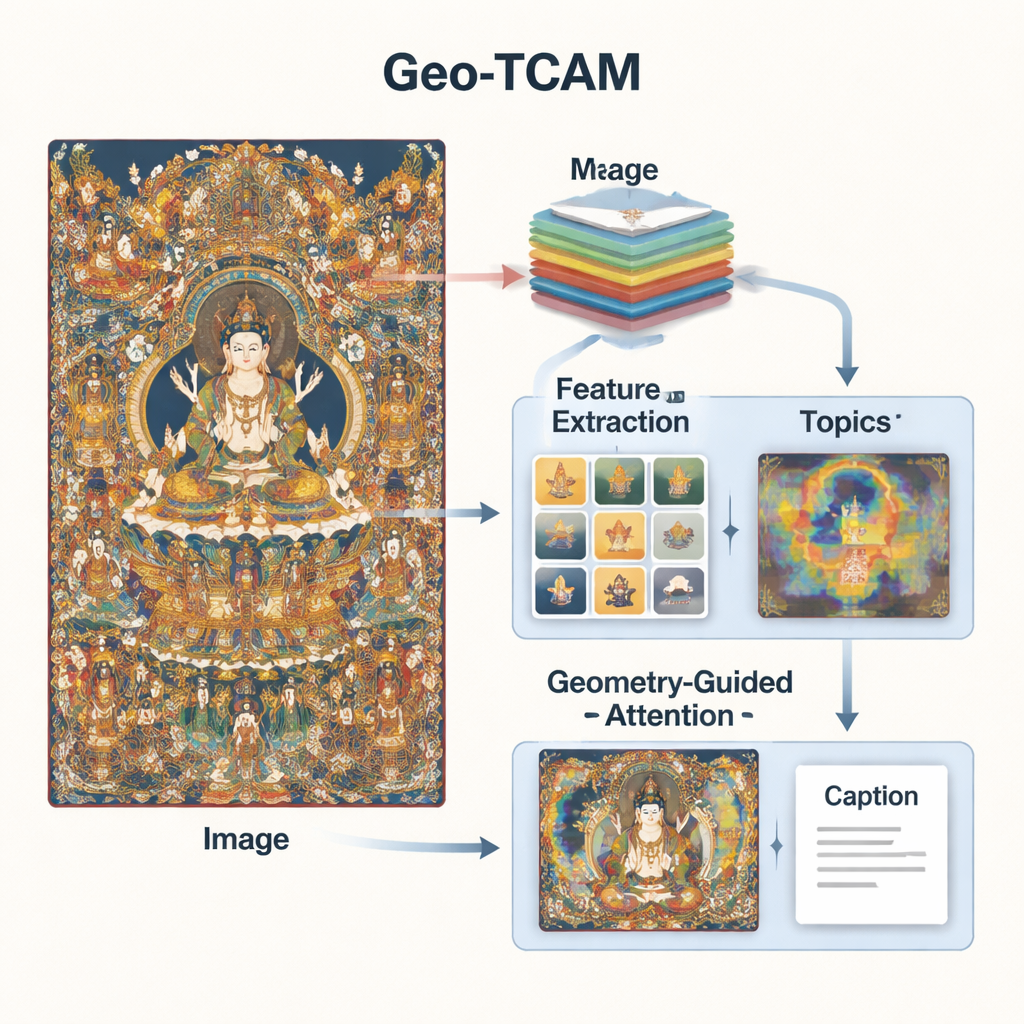
タンカの「トピック」をモデルに教える
視覚情報だけでは不十分であり、システムにはタンカ固有の言葉遣いやテーマの理解も必要です。そのため研究者らは何千もの専門家が作成したタンカの記述文でトピックモデルを学習させました。このモデルは語を仏、菩薩、蓮台、儀礼用具、護法神などの共通テーマにまとめます。新しい画像ごとにGeo‑TCAMはどのテーマが関連性が高いかを推定し、その情報を視覚特徴と混合します。注意機構はその後、推定されるトピックと最も一致する画像領域を強調します。つまり、どの物や記号が一緒に現れる傾向があるかという事前知識が、AIをより意味のある、文化的に配慮された記述へと導くのです。
重要な場所を「見る」ための仕組み
三つ目の革新は幾何学誘導顔空間注意(GFSA)モジュールです。タンカの構図では、中心像の顔が概ね予測しうる領域に配置されることが多いです。Geo‑TCAMは単純なエッジ検出手法でその領域や周辺の手や姿勢を絞り込み、専用の注意機構を適用してキャプション生成時にこれらのピクセルの影響力を高めます。「まず位置を特定し、その後導く」という戦略は、中心の神格を早期に誤認することを防ぎます。誤認が起こるとジェスチャーや属性、序列についての長い一連の誤りに波及し得るからです。視覚的なヒートマップは、GFSAを用いることでモデルが中心像の顔や重要な持物により明確に集中しつつ、背景の重要モチーフも追跡していることを示しています。 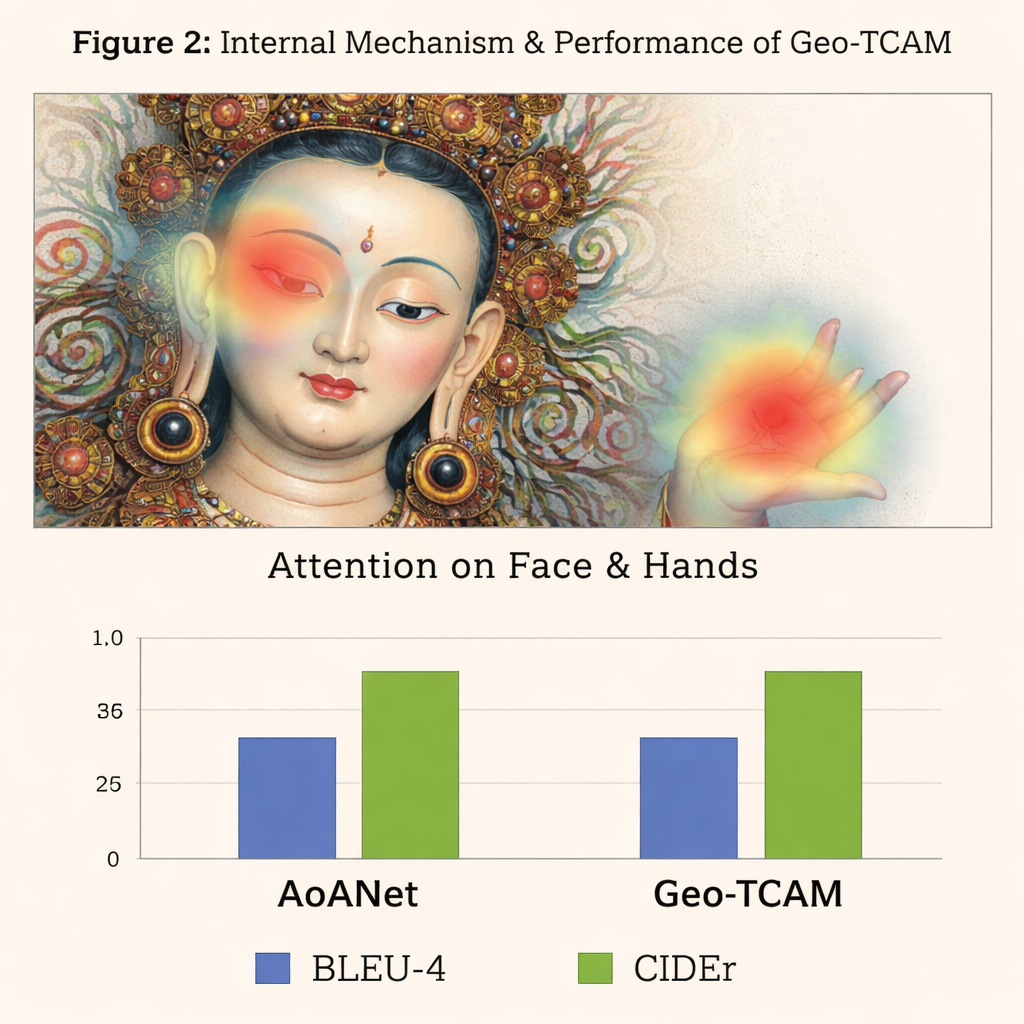
Geo‑TCAMの性能はどれほどか
手法を検証するため、著者らは詳細に注釈された約4,000枚の画像からなる専用のD‑Thangkaデータセットを構築しました。このデータセット上でGeo‑TCAMは、人気のあるAoANetや大規模なビジョン–ランゲージモデルなど複数の強力なキャプション生成システムを明確に上回りました。評価指標によってはベースライン比で約120%まで改善し、人間の評価者も正確さ、流暢さ、細部の豊かさにおいてその生成文を圧倒的に好みました。重要な点として、同じモデルを日常写真の標準的コレクション(COCOデータセット)で評価しても主要手法と競争力を保っており、その設計は強力でありながら汎用性も有していることが示されました。
文化遺産とその先にある意義
非専門家にとっての主な結論は、Geo‑TCAMが視覚的に複雑なタンカを、誰が描かれているのか、何をしているのか、そしてその細部がなぜ重要かを明確に伝える情報豊かな記述に変えられることです。階層的な視覚解析、専門家テキストから学んだテーマ、顔やジェスチャーに特化した注意を組み合わせることで、システムはこれらの美術作品を人間の専門家が読み取る方法により近い形でキャプション化します。長期的には、このようなツールがデジタルアーカイブ、博物館のガイド、教育プラットフォームを支え、難解な宗教美術をよりアクセスしやすくするとともに、保存修復者や研究者が壊れやすい文化財の記録と保護を行う助けとなるでしょう。
引用: Zhong, P., Hu, W., Zhao, Y. et al. Geo-TCAM: a Thangka captioning method integrating topic modeling with geometry-guided spatial attention. npj Herit. Sci. 14, 87 (2026). https://doi.org/10.1038/s40494-026-02343-8
キーワード: タンカ画像のキャプション作成, 文化遺産とAI, 視覚的注意機構, トピックモデリング, 美術保存