Clear Sky Science · ja
二十四史 古代・現代品詞タグ付けコーパスの構築
AI時代における古い編年史の重要性
二千年以上にわたり、中国の歴史家たちは戦争や朝廷、飢饉、日常生活を『二十四史』という大規模なシリーズに記録してきました。今日、これらの古典は研究者だけでなくコンピュータにも再発見されています。本研究は、これらの古い編年史とその現代中国語訳をどのように精緻にラベル付けされた言語データベースに変換したかを説明します。この資源は、人工知能が歴史的な文章をより正確に読み、翻訳し、分析するのに役立ち、遠い過去を一般にもずっとアクセスしやすくします。
古びた冊子からデジタルテキストへ
プロジェクトは基本的だが気の遠くなる作業から始まります:数百万字の印刷文字をきれいで正確なデジタルテキストに変換することです。チームは二十四史の決定版現代版と大規模なオンラインコレクションという二つの情報源を利用して光学文字認識システムに供給しました。次に、文字化けした箇所を丹念に取り除き、誤認された文字を修正し、ページヘッダーやフッターのような雑音を除去しました。その結果、原書に忠実で計算処理に適した、古文と現代中国語それぞれの並列ファイル群が得られました。 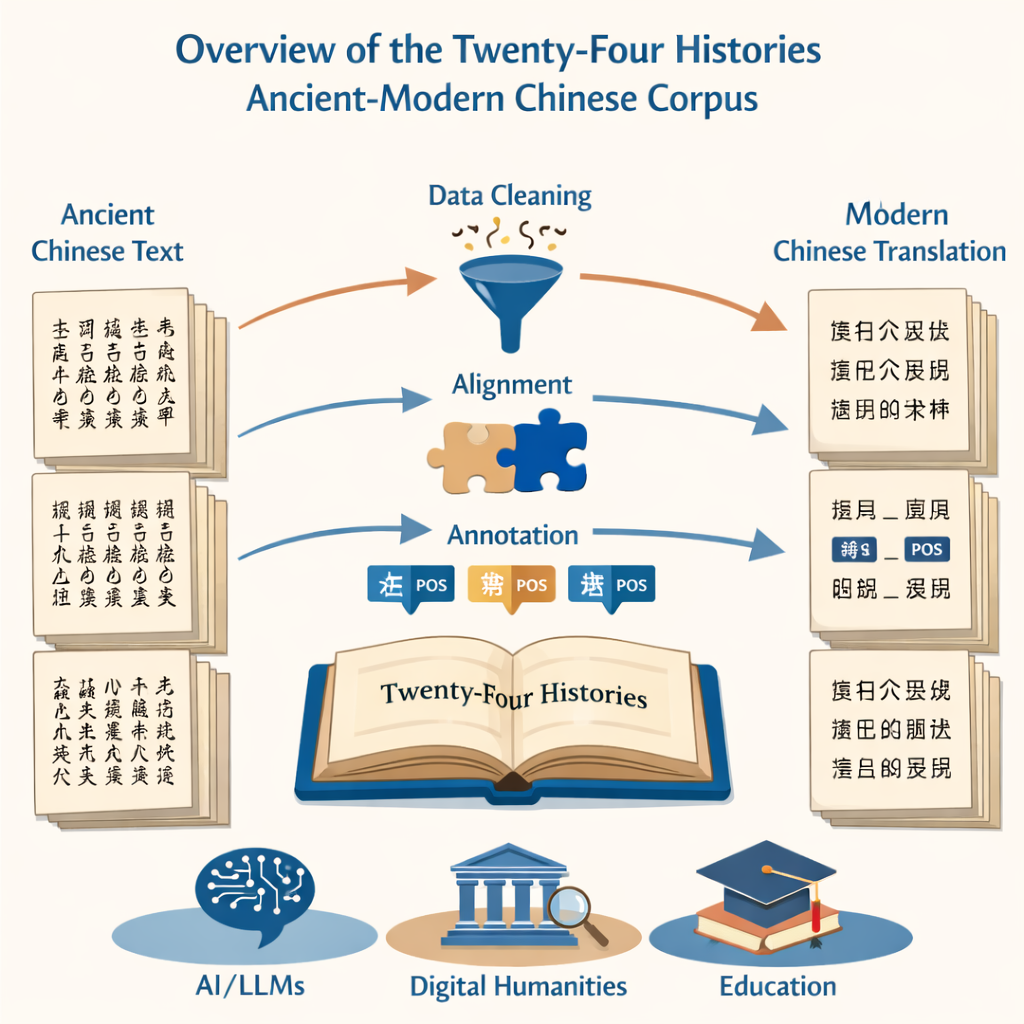
古文の文と現代文の文を対にする
言語がどのように変化したかを比較することが目的だったため、古い版と新しい版を文単位で整列させることが不可欠でした。研究者たちはまず段落を対応づけ、次にそれらを対応する文に分割するための専用のアラインメントソフトを使用しました。自動化ツールが大きな処理を担いましたが、古代中国語の文法は現代と大きく異なることがあるため、人間の専門家が各候補ペアを確認する必要がありました。ソフトが誤って思考を分割したり文字を誤読した箇所では、アノテータが元のスキャン画像を照合してデジタルテキストを修正し、各古文の文が現代文の対応文ときれいに対応するようにしました。
コンピュータに文法を学習させる
単純な転写を越えて、プロジェクトの核心は文法のラベリングにあります。古文と現代文の両方のテキスト内のすべての語に、名詞・動詞・時詞などの品詞タグが付与されました。古代中国語に対する単一の標準が存在しないため、チームはまず現代の国家規格に基準を置き、そこから古い用法に合わせて適応させました。彼らは「活かす」「国のために死ぬ」のような古特有の動詞用法に対する特別ラベルを含む22種類のタグ体系を考案しました。古文用の言語モデルと系列ラベリング層を組み合わせたカスタムのニューラルネットワークが初期タグを生成し、それを多数の訓練を受けた大学院生チームが検査・修正しました。アノテータ間の厳密な一致テストは非常に高い一致率を示し、最終的なタグ付けコーパスが規模と信頼性の両面で優れていることを確認しました。
新しいレンズが明らかにするもの
タグ付けされたコーパスが整備されると、著者らはそこに現れるいくつかのパターンを検討しました。古代中国語では一字語が支配的で、よく知られた簡潔な文体を反映している一方、現代中国語では二字語が好まれます。古文で最も頻出する項目は「之」や「以」のような小さな文法的助詞であり、動詞や普通名詞は両時期ともに語彙の約半分を占めます。データはまた、どの語が共起しやすいかを示します—例えば、役人・軍隊・外交使節を記述する構造などです。古今のタグを比較することで機能の変化をたどると、古い前置詞や副詞の一部が現代では完全な動詞に相当するようになったり、いくつかの動詞が固定化して官職名や法的用語になったりしていることが明らかになりました。ある事例研究では地名を抽出して各王朝での分布をマッピングし、政治・経済の中心が北西から長江下流域やそれ以南へと移動したことを浮かび上がらせました。 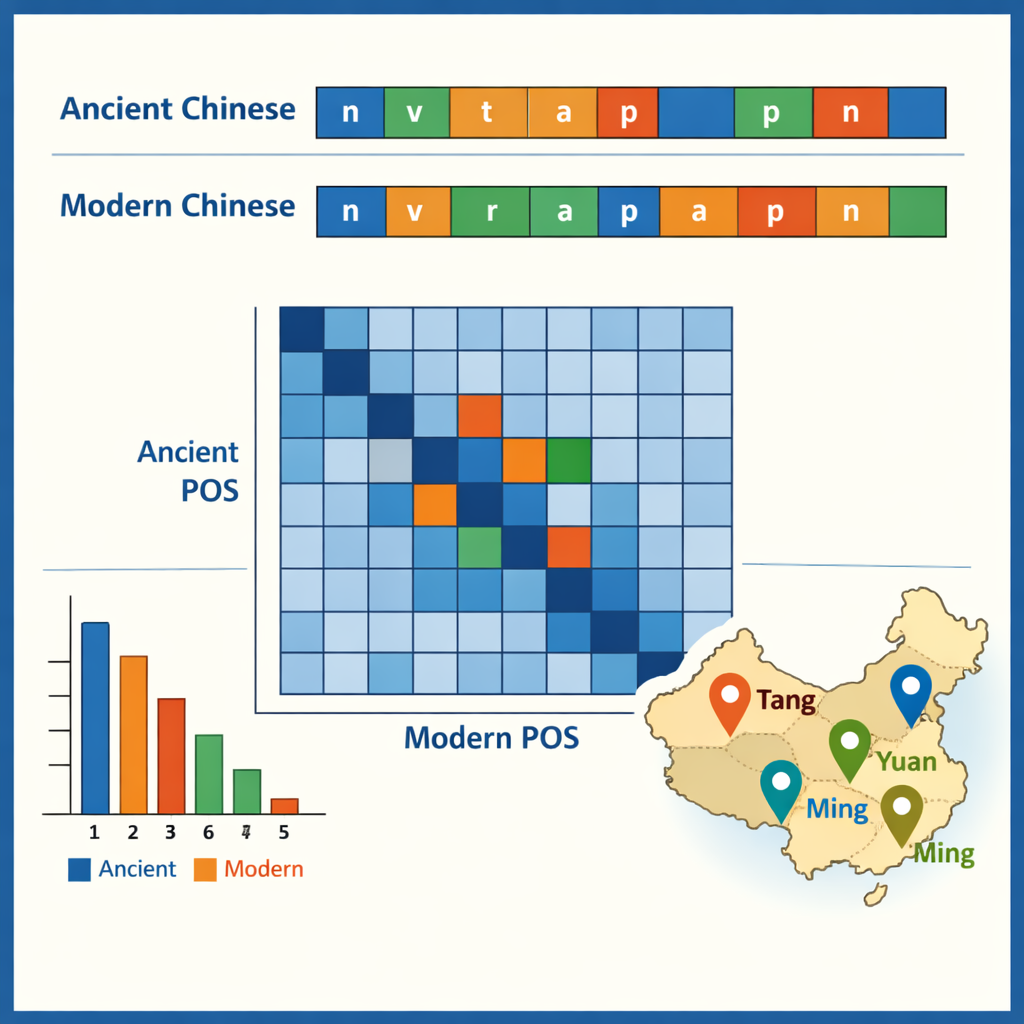
過去をデジタルな未来へつなぐ
平たく言えば、本プロジェクトは古典散文という高い壁を、人間にも機械にも扱いやすい構造化データへと変換します。歴史家や言語学者にとっては、語彙や文法、さらには国家の境界が何世紀にわたってどのように変化したかを追跡する強力なツールを提供します。AI開発者にとっては、古典中国語を文字の寄せ集めとして扱うのではなく実際に処理できる言語モデルを構築するための高品質な学習素材を提供します。そして学生や一般読者にとっては、古文と現代文の文ごとの対照が古典読解の敷居を下げます。二十四史を注意深くラベル付け・整列することで、著者らは過去の手書きの巻物と現代・未来の知的システムをつなぐ架け橋を築きました。
引用: Ye, W., Xu, Q., Zhao, X. et al. Construction of the twenty-four histories ancient-modern part-of-speech tagged corpus. npj Herit. Sci. 14, 97 (2026). https://doi.org/10.1038/s40494-026-02309-w
キーワード: 古代中国語コーパス, 品詞タグ付け, デジタル人文学, 並列テキスト, 歴史的言語変化