Clear Sky Science · it
Analisi tematica con IA generativa open-source e apprendimento automatico: un nuovo metodo per lo sviluppo induttivo di un codebook qualitativo
Perché questo è importante per le domande di tutti i giorni
Ogni volta che le persone compilano questionari o rispondono a interviste, lasciano storie ricche su lavoro, scuola, salute o vita comunitaria. Leggere qualche dozzina di queste risposte è facile; dare senso a migliaia non lo è. Questo articolo descrive un nuovo modo per i ricercatori di usare l’intelligenza artificiale open-source per aiutare a setacciare enormi pile di commenti scritti e tirarne fuori le idee principali, mantenendo però gli esseri umani al comando dell’interpretazione. L’obiettivo è rendere possibile una ricerca qualitativa accurata e sfumata su scale che di solito sono riservate alle statistiche dei big data.
Un modo più intelligente per leggere migliaia di commenti
Gli autori si concentrano su un approccio popolare nelle scienze sociali chiamato analisi tematica, in cui i ricercatori leggono testi e cercano schemi ricorrenti o “temi” che rispondono alle loro domande di ricerca. Tradizionalmente questo significa codificare lentamente ogni commento a mano e costruire un codebook—un elenco strutturato di temi e sotto-temi. Quel processo può funzionare bene per qualche dozzina di interviste, ma diventa opprimente quando ci sono decine di migliaia di risposte aperte. L’articolo si chiede: i modelli di testo generativi disponibili liberamente e altri strumenti open-source possono aiutare nelle fasi iniziali e ripetitive di questo lavoro senza sostituire il giudizio umano?
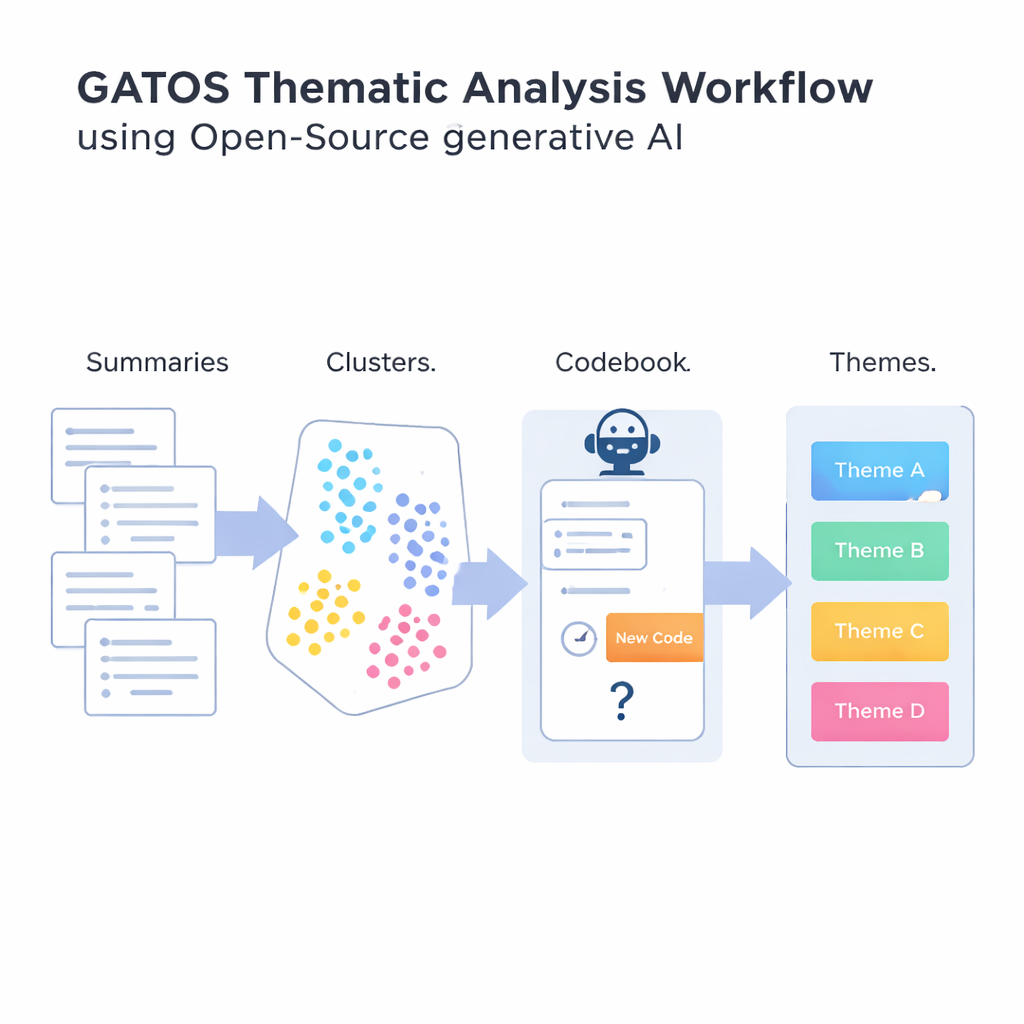
Presentazione del flusso di lavoro GATOS
Per rispondere a quella domanda, gli autori introducono il flusso di lavoro Generative AI-enabled Theme Organization and Structuring, o GATOS. Questo flusso di lavoro concatena diversi passaggi. Per prima cosa, un modello linguistico open-source legge le risposte individuali e scrive brevi punti riassuntivi focalizzati su ciò che ciascuna persona sta dicendo. Poi, un altro strumento trasforma questi riassunti in rappresentazioni numeriche in modo che un computer possa confrontare e raggruppare idee simili. I riassunti vengono quindi clusterizzati in gruppi che probabilmente riflettono temi condivisi, come preoccupazioni sul bilanciamento lavoro–vita o frustrazioni per comunicazioni poco chiare.
Lasciare che l’IA suggerisca, ma non inondi, nuove idee
Il passaggio più innovativo arriva quando il sistema inizia a costruire una bozza di codebook. Per ogni cluster di riassunti correlati, un altro modello generativo esamina le idee in quel cluster e i codici già presenti nel codebook. Poi ragiona se è necessario un codice davvero nuovo o se i codici esistenti sono sufficienti. Se emerge una nuova angolazione—per esempio, “strumenti affidabili per videoconferenze” come preoccupazione specifica—propone un’etichetta breve e una definizione, che viene aggiunta. In caso contrario, sceglie di riutilizzare ciò che già esiste. Un passaggio finale raggruppa i codici correlati in temi più ampi, creando una mappa strutturata dai commenti grezzi a intuizioni organizzate. L’enfasi, in tutto il processo, è evitare un’ondata di codici quasi duplicati pur catturando le sottili differenze nelle esperienze delle persone.
Testare il metodo con dati fittizi realistici
Poiché negli studi del mondo reale raramente esiste una “chiave di risposta” nota, il team ha testato GATOS usando dati sintetici (generati al computer) dove i temi nascosti erano noti in anticipo. Hanno creato tre grandi dataset realistici: feedback tra pari sul lavoro di squadra, opinioni sulla cultura etica sul lavoro e pareri sul ritorno in ufficio dopo la pandemia di COVID-19. Per ciascun dataset hanno prima definito otto temi e diversi sotto-temi, poi hanno usato un modello linguistico per scrivere centinaia di risposte realistiche da diverse persona, come membri di sindacati, dirigenti o studenti. Dopo aver eseguito GATOS su questi dataset, revisori umani hanno confrontato i temi generati dall’IA con i sotto-temi originali e nascosti per vedere quanto bene si allineassero.
Quanto ha funzionato e quali sono i compromessi?
Nei tre casi di test, il flusso di lavoro ha ricostruito la maggior parte dei sotto-temi originali in modo abbastanza accurato: la grande maggioranza aveva almeno una corrispondenza forte, e solo una piccola manciata non aveva un buon corrispettivo. È significativo che, all’aumentare dei dati esaminati, il sistema abbia proposto sempre meno codici nuovi, suggerendo che imparava a riutilizzare idee esistenti piuttosto che inventare variazioni infinite. Gli autori sostengono che questo tipo di configurazione open-source, eseguibile localmente, può attenuare i timori sulla privacy e rendere più semplice per diversi team di ricerca replicare il lavoro degli altri. Allo stesso tempo sottolineano che i dati sintetici sono più semplici di molte situazioni reali, che il flusso di lavoro può ancora creare codici sovrapposti e che i ricercatori umani sono ancora necessari per raffinare, interpretare e valutare il codebook finale.
Cosa significa per i non esperti
Per i lettori al di fuori dell’accademia, la conclusione è che l’IA open-source può aiutare gli scienziati sociali e altri ricercatori ad ascoltare molte più persone senza ridurre le loro parole a numeri rozzi. Invece di sostituire gli analisti umani, il flusso di lavoro GATOS funziona come un assistente molto rapido e molto organizzato che suggerisce schemi e etichette preliminari, lasciando agli esseri umani la decisione su cosa quei schemi significhino veramente. Se ulteriori studi confermeranno questi risultati su dati del mondo reale, strumenti come GATOS potrebbero rendere più semplice basare le politiche del posto di lavoro, i programmi educativi e le decisioni pubbliche sulla ricchezza completa di ciò che le persone dicono realmente, non solo sulle caselle a scelta multipla dei sondaggi.
Citazione: Katz, A., Fleming, G.C. & Main, J.B. Thematic analysis with open-source generative AI and machine learning: a new method for inductive qualitative codebook development. Humanit Soc Sci Commun 13, 209 (2026). https://doi.org/10.1057/s41599-026-06508-5
Parole chiave: analisi dei dati qualitativi, analisi tematica, IA generativa, modelli linguistici open-source, metodi di ricerca nelle scienze sociali