Clear Sky Science · it
Valutazione sistematica e linee guida per il modello Segment Anything nell’analisi di video chirurgici
Perché gli strumenti video intelligenti contano in sala operatoria
La chirurgia moderna è sempre più guidata dal video: telecamere minuscole osservano l’interno del corpo mentre i chirurghi manovrano strumenti delicati su uno schermo. Trasformare questi filmati ricchi ma disordinati in mappe chiare e annotate di strumenti e tessuti potrebbe rendere le operazioni più sicure, migliorare la formazione e rendere più affidabile l’aiuto robotico futuro. Questo studio prende un potente nuovo sistema visivo generalista, addestrato originariamente su video di uso quotidiano, e pone una domanda semplice ma cruciale: può «vedere» abbastanza bene all’interno del corpo umano da risultare utile in chirurgia reale—senza essere riaddestrato da zero su costosi dati medici? 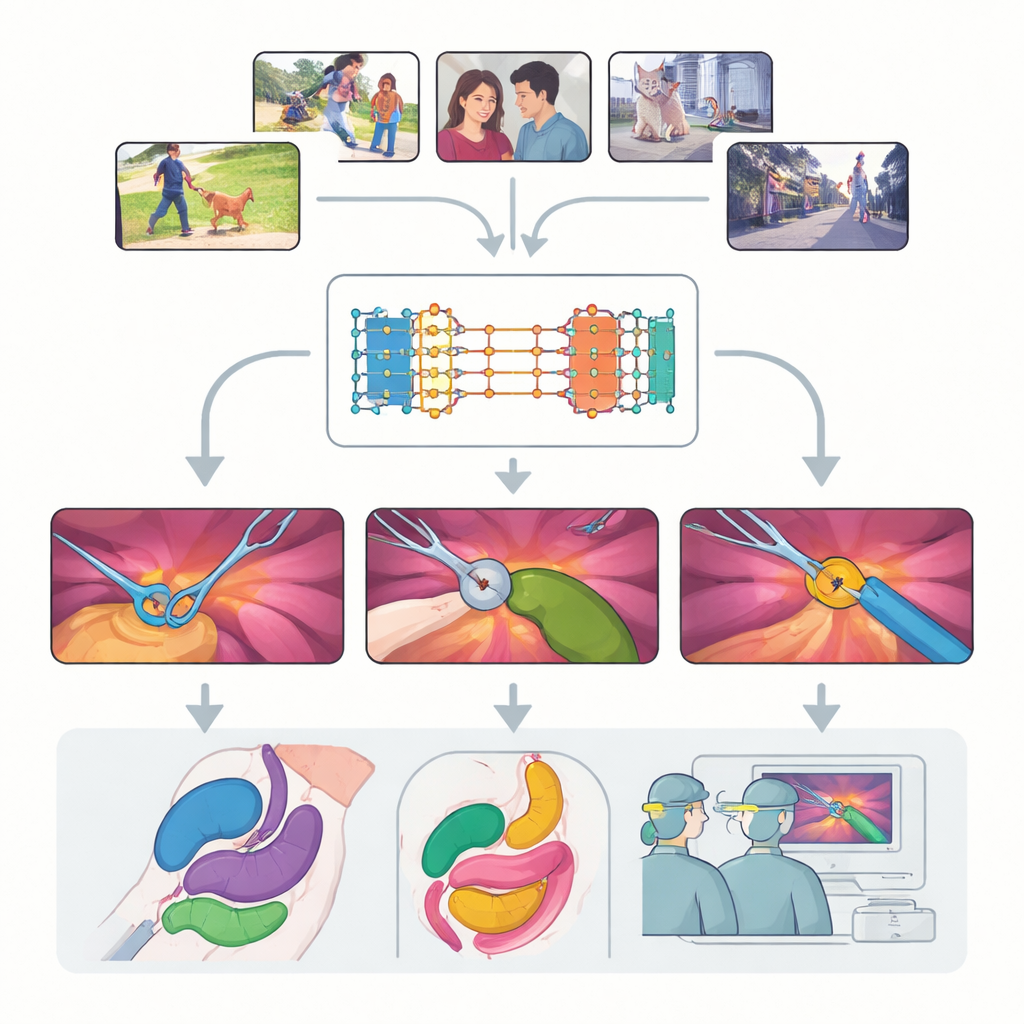
Uno strumento visivo flessibile costruito per qualsiasi scena
Il lavoro si concentra sul Segment Anything Model 2 (SAM2), un ampio sistema di intelligenza artificiale progettato per individuare oggetti nei video ogni volta che gli viene fornito un suggerimento, o “prompt”, su cosa cercare. Diversamente dai modelli tradizionali che imparano categorie fisse, SAM2 è agnostico rispetto alle classi: non importa se un oggetto sia un cane, un’auto o una pinza chirurgica, purché l’utente lo indichi con un punto, un riquadro o una maschera di esempio. Un progresso chiave di SAM2 è la sua banca della memoria, che ricorda l’aspetto di un oggetto nei fotogrammi precedenti e usa quella memoria per seguirlo nel tempo. Questo rende SAM2 particolarmente promettente per i video chirurgici, dove gli strumenti entrano e escono dal campo visivo e i tessuti si deformano continuamente.
Mettere il modello alla prova su molteplici interventi
Gli autori conducono una valutazione sistematica su larga scala di SAM2 su nove dataset diversi che coprono diciassette tipi di procedure, dalla colecistectomia laparoscopica alla chirurgia prostatico-robotica e all’endoscopia. Esaminano tre sfide principali: tracciare gli strumenti, segmentare più organi e comprendere scene che mescolano strumenti e tessuti. Per ciascuna sfida testano diverse modalità di prompting—punti singoli, punti multipli, riquadri e maschere complete—and esplorano quanto spesso i prompt debbano essere aggiornati durante il video. Confrontano inoltre il modello pronto all’uso con vari approcci di leggero riaddestramento su immagini chirurgiche per capire fino a che punto si può spingere la performance senza richiedere enormi nuovi dataset.
Ciò che funziona meglio all’interno del corpo
Nel complesso, SAM2 si dimostra sorprendentemente efficace in questo ambiente non familiare. Senza alcun riaddestramento chirurgico, segmenta già strumenti e molti organi in modo competitivo rispetto a modelli specialistici medici, soprattutto quando riceve prompt ricchi come riquadri o maschere. Il ri-inizializzare periodicamente i prompt ogni 30 fotogrammi—sostanzialmente ricordando al sistema cosa si trova dove—migliora notevolmente il tracciamento su clip lunghe e complesse. Quando i ricercatori affinano solo parti specifiche di SAM2, come il modulo che trasforma i prompt in maschere, l’accuratezza nelle scene multi-organo aumenta sensibilmente mantenendo modeste le esigenze di addestramento. Al contrario, cercare di adattare l’intero encoder di immagine con dati chirurgici limitati può danneggiare le prestazioni, suggerendo che gran parte della conoscenza visiva generale di SAM2 dovrebbe restare intatta. 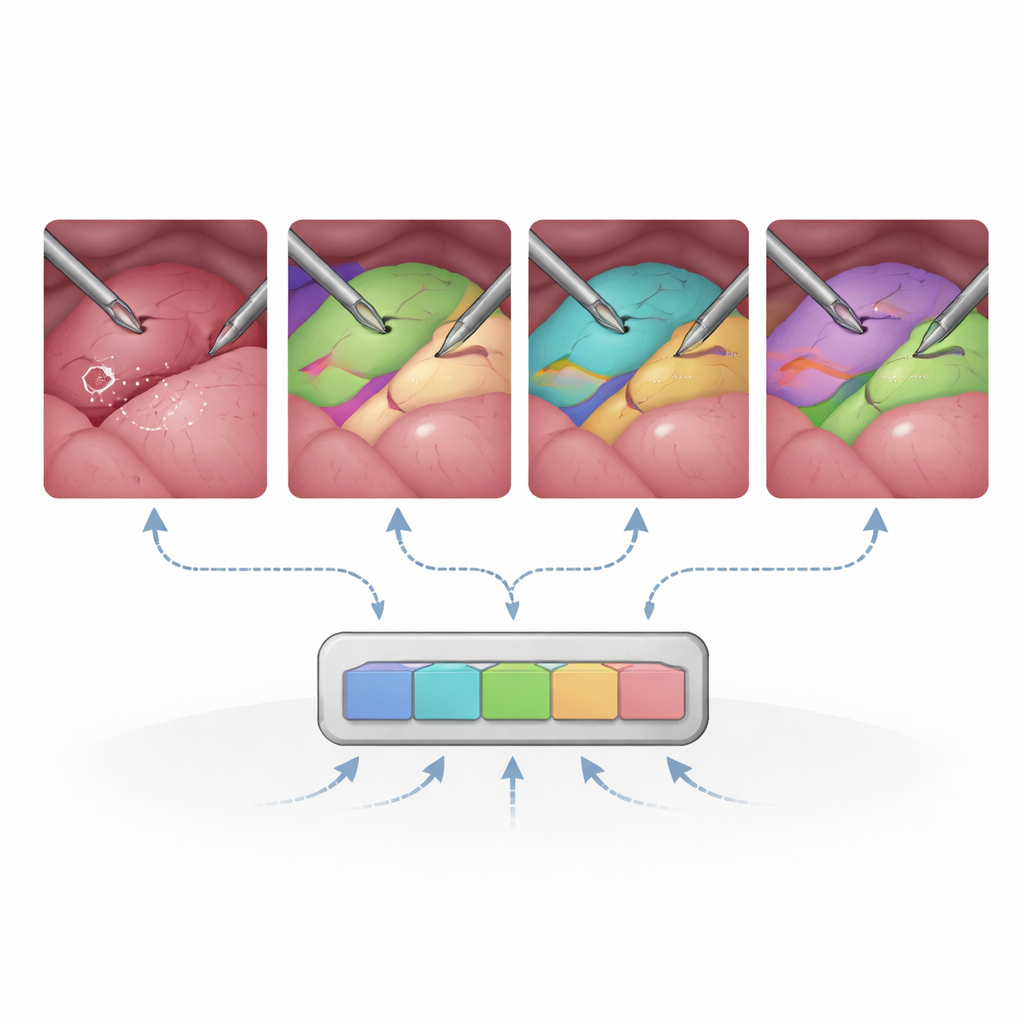
Limiti in scene caotiche e in rapido cambiamento
Lo studio mette anche in luce punti deboli evidenti. SAM2 fatica quando il campo visivo è stretto, l’immagine è rumorosa o poco illuminata, o i tessuti non hanno confini netti, come in alcune procedure endoscopiche. Strutture ramificate sottili come vasi sanguigni e dotti sono difficili da separare quando si sovrappongono o condividono un contorno simile. L’uso della memoria video non sempre aiuta: in scene altamente dinamiche con rapidi movimenti di camera, i segnali temporali possono fuorviare il modello invece di stabilizzarlo. Questi risultati evidenziano che, sebbene un modello foundation generalista possa arrivare lontano, alcune realtà chirurgiche richiedono ancora messa a punto specifica del dominio e una migliore gestione del movimento e dei cambiamenti di aspetto.
Linee guida per i futuri sistemi chirurgici intelligenti
Dalle prove estese gli autori traggono consigli pratici per ricercatori e clinici che vogliono usare SAM2 in progetti chirurgici. Raccomandano di partire con prompt a maschera o a riquadro e un fine-tuning semplice basato sull’immagine focalizzato sul decoder delle maschere, aggiungendo aggiornamenti periodici dei prompt per video lunghi, e di esplorare l’addestramento video più complesso solo quando le scene risultano relativamente stabili. Dimostrano che anche clip annotati in modo sparso—con solo alcuni fotogrammi etichettati—possono essere sufficienti per adattare efficacemente il modello. In termini chiari, la conclusione è incoraggiante: un singolo modello visivo ampiamente addestrato può affrontare molti diversi compiti di segmentazione chirurgica, riducendo drasticamente la necessità di costruire uno strumento nuovo per ogni procedura. Con un prompting accurato e una leggera personalizzazione, sistemi come SAM2 potrebbero diventare componenti potenti per la prossima generazione di strumenti di navigazione chirurgica, automazione e formazione.
Citazione: Yuan, C., Jiang, J., Yang, K. et al. Systematic evaluation and guidelines for segment anything model in surgical video analysis. npj Digit. Surg. 1, 2 (2026). https://doi.org/10.1038/s44484-025-00002-2
Parole chiave: analisi di video chirurgici, segmentazione delle immagini, modelli foundation, chirurgia assistita da computer, IA medica