Clear Sky Science · it
Colmare il divario computazionale‑sperimentale: sfruttare i grandi modelli linguistici per dare priorità ai trattamenti per l’Alzheimer basandosi sul confronto di modelli di apprendimento
Perché è importante per famiglie e pazienti
Il morbo di Alzheimer priva le persone della memoria, dell’indipendenza e della qualità della vita, eppure trattamenti veramente efficaci sono ancora rari. Questo studio esplora un modo più rapido per trovare nuovi trattamenti usando farmaci già esistenti, combinando potenti modelli computazionali con un grande modello linguistico — lo stesso tipo di IA ora impiegata nei chatbot quotidiani — per setacciare enormi quantità di dati medici e pubblicazioni scientifiche. L’obiettivo è ridurre una lunga lista di potenziali farmaci a un piccolo insieme realistico che scienziati e medici possano effettivamente testare sui pazienti.
Riutilizzare farmaci esistenti per un nuovo scopo
Sviluppare un farmaco completamente nuovo da zero può richiedere più di un decennio e costare miliardi di dollari, senza alcuna garanzia di successo. Un’alternativa è la “riproposta di farmaci”, che cerca nuovi impieghi per medicinali già approvati per altre condizioni, come il morbo di Parkinson o la depressione. Poiché questi farmaci hanno profili di sicurezza noti, possono spesso passare più rapidamente alle sperimentazioni cliniche per l’Alzheimer. Ma i metodi computazionali moderni che analizzano banche dati biologiche e la letteratura medica ora generano elenchi enormi di candidati — molto più numerosi di quelli che i ricercatori possono valutare manualmente — creando un nuovo collo di bottiglia nel processo.
Mettere insieme più modelli intelligenti
Il team di ricerca ha affrontato questo problema costruendo un quadro per la riproposta di farmaci per l’Alzheimer che parte da tre diversi modelli computazionali avanzati. Ciascun modello esamina una grande “mappa” biomedica chiamata grafo della conoscenza, che collega malattie, farmaci, geni e altri concetti medici, e suggerisce farmaci che potrebbero essere utili per l’Alzheimer. Siccome ogni modello individua pattern in modo diverso, le loro liste non coincidono completamente. Gli autori hanno combinato le prime 30 proposte di ciascun modello in un unico insieme di 90 farmaci candidati, poi hanno utilizzato un grande modello linguistico (LLM) nel ruolo di revisore automatizzato ma prudente, che legge gli studi pubblicati per ciascun farmaco e giudica se le evidenze appaiono utili, neutre o dannose per l’Alzheimer.
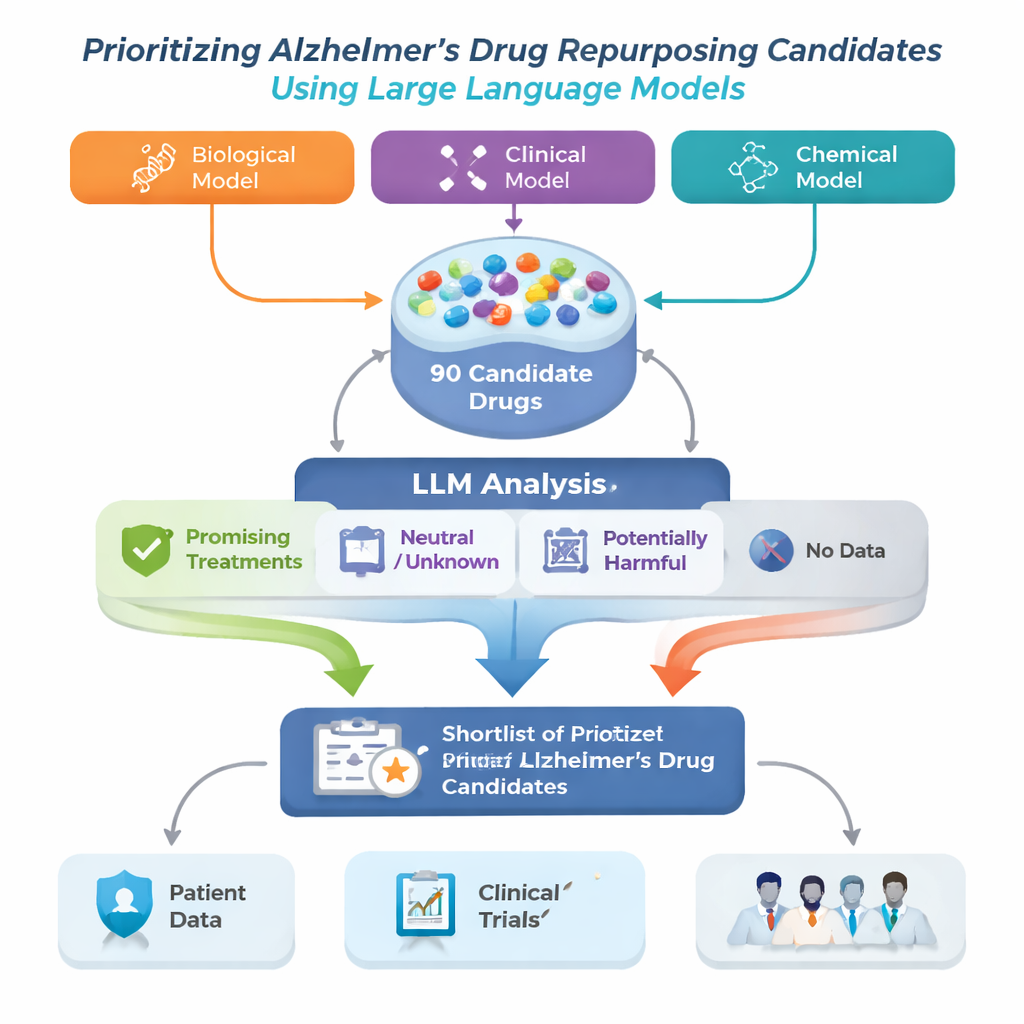
Come l’IA legge la letteratura medica
Per ogni farmaco candidato, il sistema ha estratto fino a 200 abstract scientifici da PubMed oltre a descrizioni dettagliate dei farmaci da un database farmaceutico. All’LLM è stato chiesto di basare il proprio giudizio solo sul testo mostrato e di etichettare ogni abstract come positivo, neutro o negativo riguardo al trattamento dell’Alzheimer. Queste etichette sono state quindi convertite in punteggi semplici: la percentuale di abstract positivi, neutrali o negativi. Usando due set di regole — una più rigorosa che richiedeva chiara evidenza positiva e una più permissiva che segnalava anche un accenno di beneficio — il framework ha ordinato i farmaci in quattro gruppi: trattamenti promettenti, potenzialmente dannosi, oscuri o neutri e farmaci senza alcun articolo correlato all’Alzheimer. Quest’ultimo gruppo, sebbene poco studiato, può contenere opportunità particolarmente nuove.
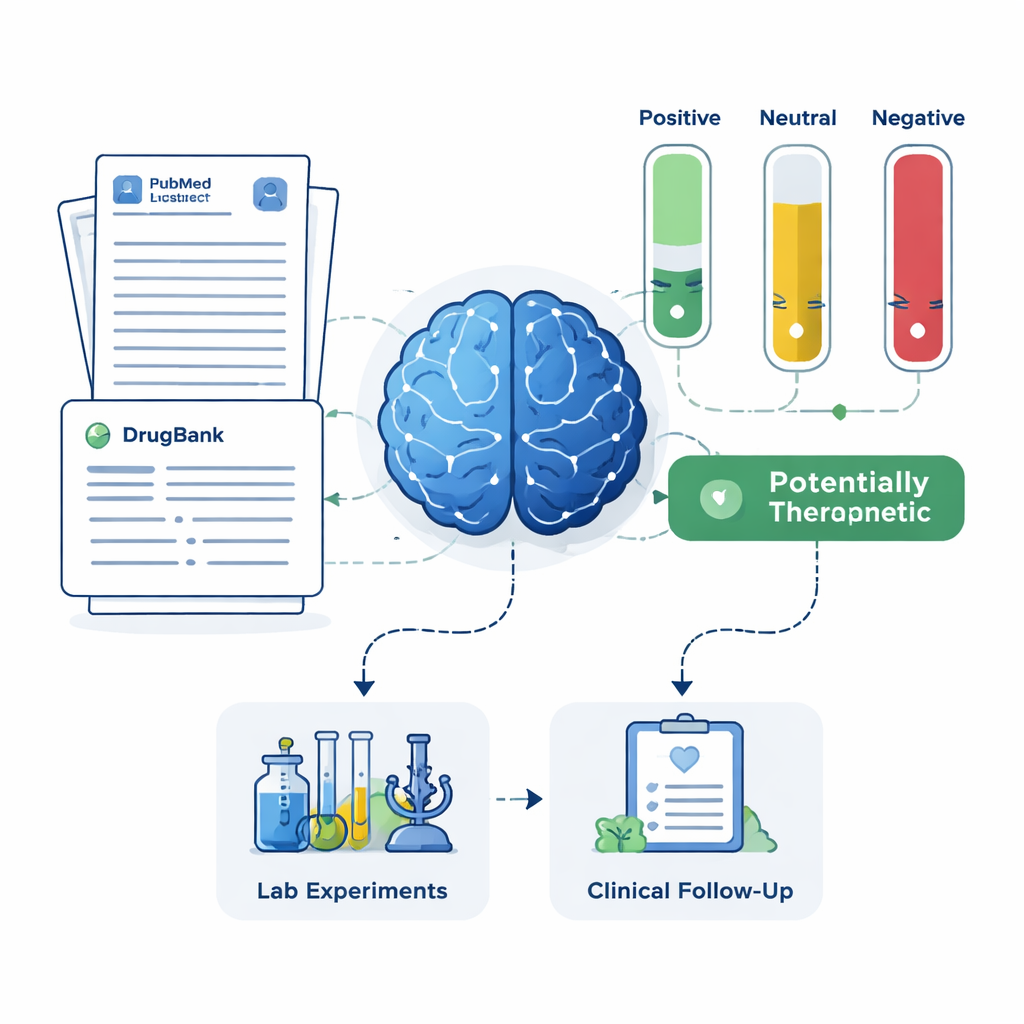
Confronto con pazienti reali e sperimentazioni cliniche
Per verificare se la lista ristretta dall’IA avesse senso nel mondo reale, il team ha confrontato i risultati con due fonti indipendenti: un grande registro di pazienti con Alzheimer e i registri di sperimentazioni cliniche registrate. Il framework ha recuperato con successo la memantina, un farmaco esistente per l’Alzheimer con segnali protettivi forti nei dati dei pazienti e un’ampia storia di trial, come candidato ad alta priorità. Ha inoltre evidenziato farmaci come magnesio, minociclina, pimavanserina, testosterone e doxiciclina, che hanno livelli variabili di ricerca di supporto ma erano stati considerati promettenti da clinici esperti. Allo stesso tempo, il sistema ha identificato farmaci la cui letteratura suggeriva possibile danno o mancanza di beneficio, raccomandandone la de-prioritizzazione o l’indagine sugli effetti collaterali piuttosto che l’uso terapeutico.
Dalle previsioni computazionali ai passi pratici successivi
In termini pratici, questo framework funziona come un assistente di ricerca ultra‑veloce e attento che legge migliaia di articoli, incrocia pattern in grandi banche dati mediche e consegna agli esperti umani una lista molto più breve e meglio organizzata di candidati farmaci per l’Alzheimer su cui concentrarsi. Lo studio mostra che combinando diversi tipi di IA — modelli basati su grafi per generare idee e un modello linguistico per giudicare le evidenze — i ricercatori possono trovare più rapidamente sia farmaci ben supportati sia opzioni nuove e interessanti da testare. Pur non essendo di per sé una cura per l’Alzheimer, questo approccio offre una nuova potente via per collegare le idee generate dai computer con il lavoro concreto di esperimenti di laboratorio e trial clinici, potenzialmente accelerando il percorso verso trattamenti più efficaci.
Citazione: Li, M., Niu, S., Xu, Y. et al. Bridging the computational-experimental gap: leveraging large language model to prioritize Alzheimer’s therapeutics based on comparison of learning models. npj Health Syst. 3, 20 (2026). https://doi.org/10.1038/s44401-026-00074-3
Parole chiave: Morbo di Alzheimer, riproposta di farmaci, intelligenza artificiale, grandi modelli linguistici, grafi della conoscenza