Clear Sky Science · it
Specchio magico 3D: ricostruzione dell’abbigliamento da una singola immagine tramite una prospettiva causale
Provare i vestiti senza la cabina
Immagina di scattare con il telefono una singola foto a figura intera e di vederti istantaneamente in 3D, poter ruotare l’immagine, cambiare punto di vista o persino scambiare gli abiti con un amico. Questo articolo affronta il problema tecnico centrale dietro a quel “Specchio magico 3D”: trasformare una normale foto 2D di una persona vestita in un modello 3D dettagliato del suo abbigliamento, senza fare affidamento su costose scansioni 3D o foto in studio controllate.
Perché trasformare foto 2D in 3D è così difficile
Trasformare un’immagine piatta in un oggetto 3D è un rompicapo classico. I sistemi esistenti spesso partono da un template digitale del corpo fisso e lo deformano per adattarlo alla foto. Questo funziona abbastanza bene per parti del corpo rigide come braccia e gambe, ma fallisce con abiti fluttuanti, cappotti drappeggiati, capelli o borse, che non seguono una forma semplice e standard. Un altro ostacolo è costituito dai dati: ci sono milioni di foto di moda sul web, ma quasi nessuna grande raccolta di capi 3D misurati con precisione per l’addestramento. Infine, una singola foto nasconde informazioni importanti. Un cappotto vicino alla fotocamera può sembrare identico a uno più grande posto più lontano, e illuminazione e motivi del tessuto possono confondere l’algoritmo di apprendimento. Queste ambiguità rendono difficile per una rete neurale “indovinare” la corretta struttura 3D.
Insegnare all’IA a separare causa ed effetto
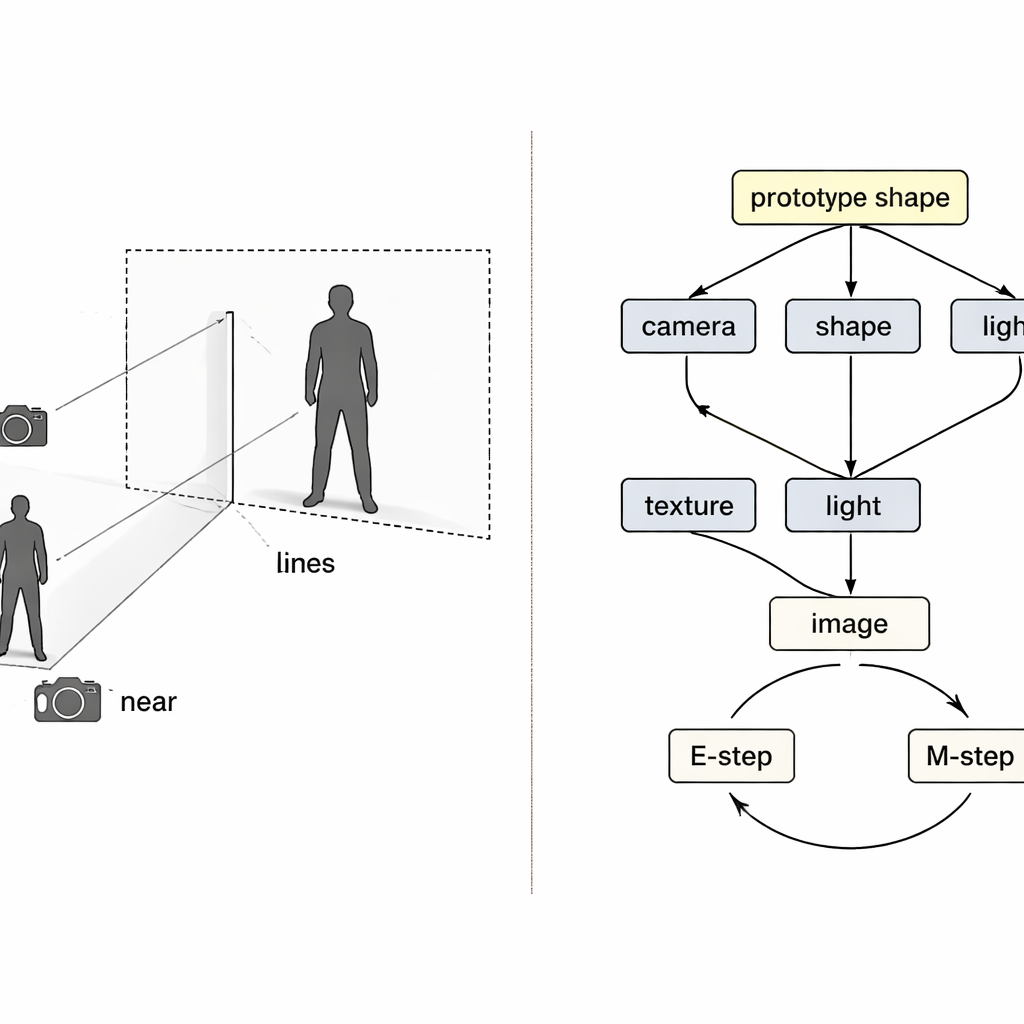
Invece di trattare il problema come una mappatura scatola nera da pixel a 3D, gli autori prendono in prestito idee dal ragionamento causale—la matematica di causa ed effetto. Considerano l’immagine finale come il risultato di quattro cause nascoste: la posizione della fotocamera, la forma dell’indumento, la sua texture (colori e motivi) e l’illuminazione. Una speciale “mappa causale strutturale” descrive come questi fattori si combinano per produrre l’immagine osservata. Guidato da questa mappa, il sistema usa quattro encoder neurali separati, ciascuno responsabile di un fattore. Insieme a un renderer 3D ispirato alla fisica, essi formano un ciclo: immagine e maschera del primo piano entrano, ne esce una mesh 3D colorata, che poi viene proiettata di nuovo in un’immagine confrontabile con l’originale.
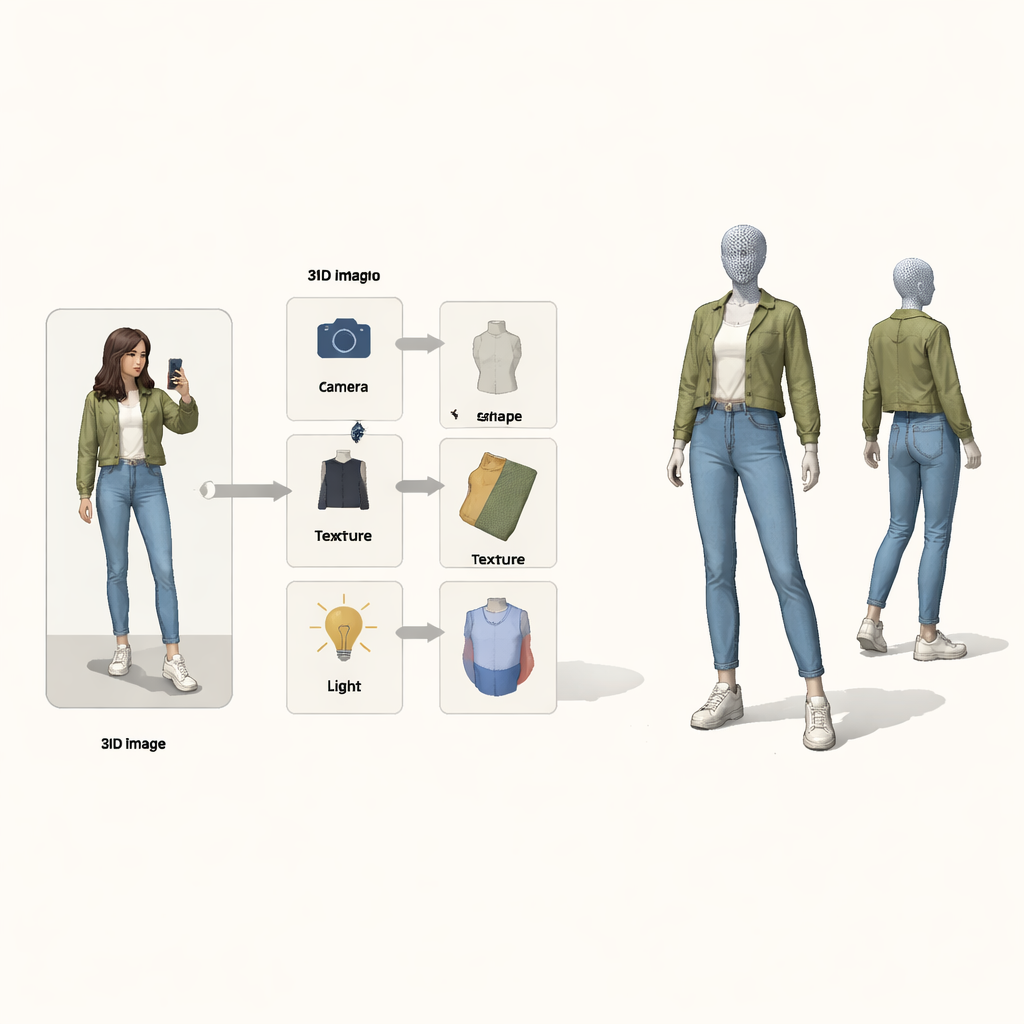
Un ciclo di apprendimento che sistema una cosa alla volta
Anche con encoder separati, l’addestramento può andare storto. Se la ricostruzione è imperfetta, non è chiaro quale encoder sia responsabile, e l’apprendimento tende ad aggiustarli tutti insieme. Gli autori trattano questo come un classico problema di “collider” nella causalità, dove cause diverse possono compensare erroneamente l’una per l’altra. La loro soluzione è intrecciare due loop di expectation–maximization nell’addestramento. Nel primo loop, tre encoder vengono temporaneamente bloccati mentre il quarto viene aggiornato da solo, in modo che gli errori siano chiaramente attribuiti e quel componente impari un ruolo più pulito. Nel secondo loop, una forma 3D “prototipo” condivisa—inizialmente una semplice sfera—viene aggiornata lentamente per diventare la forma media umana o di un uccello nei dati. Gli esempi individuali imparano solo piccole deviazioni da questo prototipo, mentre il modulo fotocamera si assume la piena responsabilità di quanto grande o vicino appare l’oggetto, affrontando direttamente la confusione dimensione-verso-distanza.
Dalle foto di moda agli uccelli, e oltre
Per testare il loro approccio, i ricercatori si addestrano su due grandi dataset di moda contenenti foto di strada ordinarie e su una raccolta standard di immagini di uccelli. È importante notare che usano solo maschere di primo piano 2D, non mesh 3D di verità a terra. Sull’abbigliamento umano, il loro sistema supera i metodi basati su template corporei popolari nel riprodurre il vero contorno dei capi e gestisce elementi non rigidi come capelli e borse in modo più fedele. Sugli uccelli raggiunge o supera la qualità dei metodi di ricostruzione 3D da singola immagine di punta, producendo punti di vista nuovi più realistici. I modelli 3D sono abbastanza flessibili da supportare applicazioni creative, come scambiare texture di abiti tra persone o generare dati sintetici di addestramento per migliorare sistemi di re-identificazione delle persone usati nella ricerca sulla sorveglianza.
Cosa significa per i mondi digitali di tutti i giorni
Per i non specialisti, il messaggio chiave è che avatar 3D convincenti e strumenti di prova virtuale non richiedono più scanner 3D costosi o template rigidi. Modellando esplicitamente causa ed effetto—separando fotocamera, forma, texture e luce e ancorandoli a un prototipo condiviso—gli autori dimostrano come un sistema possa “spiegare” una singola foto come una scena 3D. Sebbene il metodo fatichi ancora con viste mai viste prima, come la schiena di una persona fotografata solo di fronte, segna un passo significativo verso Specchi magici 3D pratici che funzionano sulle immagini disordinate e reali che scattiamo realmente.
Citazione: Zheng, Z., Zhu, J., Ji, W. et al. 3D Magic Mirror: clothing reconstruction from a single image via a causal perspective. npj Artif. Intell. 2, 29 (2026). https://doi.org/10.1038/s44387-026-00082-6
Parole chiave: prova virtuale, ricostruzione 3D, apprendimento causale, computer vision, AI per la moda