Clear Sky Science · it
Il ruolo dei grandi modelli linguistici nelle cure d’emergenza: uno studio completo di benchmarking
Perché questo è importante per chiunque possa recarsi al pronto soccorso
I reparti di emergenza sono più affollati che mai, con attese più lunghe e meno personale per prendersi cura di un numero crescente di pazienti gravemente malati. Questo studio pone una domanda che riguarda quasi tutti: i sistemi di IA moderni, noti come grandi modelli linguistici, possono aiutare in modo sicuro medici e infermieri a lavorare più velocemente e con maggiore efficacia nel pronto soccorso? Sottoponendo diversi sistemi di IA di punta a una serie di test medici e casi simulati in ambiente di emergenza, i ricercatori esplorano quanto questi strumenti siano vicini a diventare "co-piloti" affidabili nelle cure urgenti.
I pronto soccorso sotto forte pressione
Il documento inizia delineando una crisi crescente nelle cure d’emergenza, soprattutto negli Stati Uniti. L’invecchiamento della popolazione e l’aumento delle malattie croniche stanno facendo registrare numeri record di accessi al pronto soccorso, arrivati a circa 155 milioni solo nel 2022. Allo stesso tempo, gli ospedali affrontano gravi carenze di infermieri e medici, e il numero di posti letto pro capite è diminuito nel corso dei decenni. Un sistema sanitario frammentato rende più difficile coordinare le cure, aumentando il rischio di ritardi ed errori. In questo contesto, gli autori sostengono che sono necessari con urgenza nuovi strumenti per aiutare i clinici a triageare i pazienti, prendere decisioni rapide e documentare le cure senza aumentare il carico di lavoro.
Come i ricercatori hanno testato l'IA medica
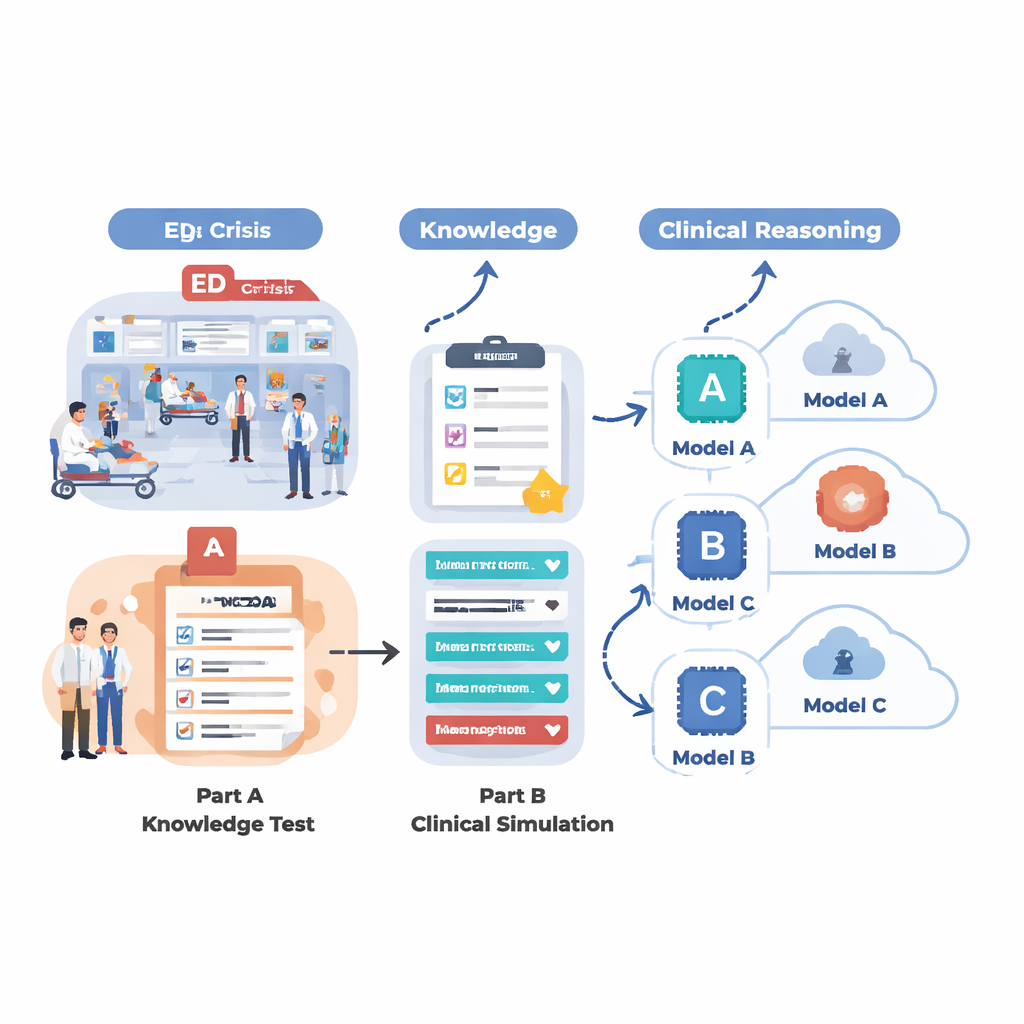
Per verificare cosa possono realmente fare oggi i sistemi di IA in un contesto simile al pronto soccorso, il team ha progettato una valutazione in due fasi. Prima, hanno testato 18 modelli linguistici diversi su un ampio insieme di quesiti a scelta multipla tratti da MedMCQA, un dataset in stile esame medico che copre 12 motivi comuni di accesso al PS come dolore toracico, dispnea, cefalea e dolore addominale. Questa fase ha misurato le conoscenze mediche di base: l’IA era in grado di scegliere la risposta corretta tra quattro opzioni su migliaia di domande? Secondo, hanno selezionato i cinque modelli migliori da quel primo turno e li hanno fatti lavorare su 12 casi realistici di emergenza, passo dopo passo, proprio come farebbe un medico. Per ogni caso l’IA doveva riassumere il paziente, assegnare un livello di urgenza per il triage, suggerire domande di approfondimento rilevanti, proporre interventi gestionali e elencare le diagnosi probabili man mano che venivano svelate nuove informazioni (segni vitali, storia clinica, reperti dell’esame, risultati di laboratorio e imaging).
Quali modelli conoscevano i fatti — e quali sapevano ragionare
Sulla semplice memorizzazione fattuale, diversi modelli hanno ottenuto risultati impressionanti. Un sistema specializzato chiamato LLaMA 4 Maverick ha raggiunto circa il 91 percento di accuratezza complessiva sulle domande mediche, seguito a breve distanza da LLaMA 3.1, GPT-4.5, GPT-5 e Claude 4. Questi modelli di punta sono stati costantemente forti nei diversi motivi di accesso, suggerendo che le IA d’avanguardia potrebbero avvicinarsi a un tetto nelle conoscenze mediche in stile manuale. I sistemi di fascia media rimanevano invece molto indietro, con alcuni punteggi intorno al 60 percento e difficoltà in aree chiave come la cura delle ferite e le problematiche respiratorie. Tuttavia, quando il compito è passato dal rispondere a domande isolate al ragionare su storie cliniche ricche e in evoluzione, le differenze sono diventate più nette. In queste simulazioni cliniche GPT-5 si è distinto chiaramente: ha prodotto i riassunti più accurati e completi, ha posto le domande di approfondimento più utili, ha raccomandato passi successivi sensati e sicuri e ha offerto gli elenchi di possibili diagnosi più approfonditi e ben ordinati.
Punti di forza, limiti e questioni di sicurezza
I clinici hanno valutato con cura l’output di ciascuna IA in termini di accuratezza, pertinenza e sicurezza. GPT-5 non solo ha ottenuto i punteggi più alti complessivamente; è stato anche l’unico modello la cui performance è rimasta stabile o è migliorata man mano che i casi diventavano più complessi, mantenendo al contempo allucinazioni ed errori gravi sotto circa il 2 percento. Altri modelli hanno mostrato pattern di debolezza distinti. Alcuni tendevano a non riconoscere diagnosi secondarie o davano priorità a problemi minori rispetto a quelli pericolosi. Altri diventavano eccessivamente cauti o vaghi, oppure si fissavano troppo rapidamente su una singola diagnosi. In generale, la maggior parte dei sistemi ha sottostimato la gravità dei pazienti nell’assegnare i livelli di triage, un bias conservativo che potrebbe ritardare cure urgenti se non corretto. I risultati sottolineano un punto chiave: conoscere i fatti medici non equivale a saperli integrare in modo affidabile in decisioni sicure e passo dopo passo quando le informazioni sono incomplete, disordinate e in continua evoluzione.

Cosa potrebbe significare per le visite future al pronto soccorso
Gli autori concludono che, sebbene diverse IA moderne ora si confrontino a vicenda sulle conoscenze mediche, GPT-5 in particolare mostra un nuovo livello di capacità di ragionamento che potrebbe renderlo utile come strumento di supporto decisionale nei reparti di emergenza. Ribadiscono che questi sistemi non sono pronti a sostituire i clinici né ad agire in autonomia. Il ruolo più promettente nel breve termine è invece quello di assistente supervisionato — aiutando gli infermieri del triage a stimare l’urgenza, redigendo riassunti dei pazienti, suggerendo domande o esami e verificando che siano state considerate diagnosi gravi. Lo studio sottolinea inoltre che sono necessarie ulteriori ricerche in contesti clinici reali, con stringenti controlli di sicurezza e regole chiare per l’uso. Per i pazienti, il messaggio è di cauto ottimismo: l’IA sta migliorando nel ragionare sui problemi medici, ma il suo impiego sicuro nel pronto soccorso dipenderà da un’attenta progettazione, sorveglianza e dall’impegno a supportare — non a sostituire — il giudizio umano di medici e infermieri.
Citazione: Naderi, B., Liu, L., Ghandehari, A. et al. The role of large language models in emergency care: a comprehensive benchmarking study. npj Artif. Intell. 2, 24 (2026). https://doi.org/10.1038/s44387-026-00078-2
Parole chiave: medicina d'emergenza, grandi modelli linguistici, supporto decisionale clinico, triage, benchmarking dell'IA medica