Clear Sky Science · it
Correggere gli errori aritmetici di moltiplicazione-accumulazione in processing-in-memory con LDPC
Perché è importante correggere gli errori matematici in memoria
I moderni chip per l’intelligenza artificiale estraggono maggiore velocità ed efficienza dall’hardware eseguendo i calcoli direttamente nella memoria, anziché trasferire continuamente i dati avanti e indietro verso processori separati. Questo approccio di “processing-in-memory” risparmia energia ma introduce un problema serio: piccole imperfezioni elettriche possono capovolgere bit memorizzati o distorcere segnali analogici, degradando silenziosamente l’accuratezza di compiti come il riconoscimento delle immagini. L’articolo descrive un nuovo modo per rilevare e correggere automaticamente questi errori al volo, aiutando l’hardware AI futuro a rimanere sia veloce sia affidabile.
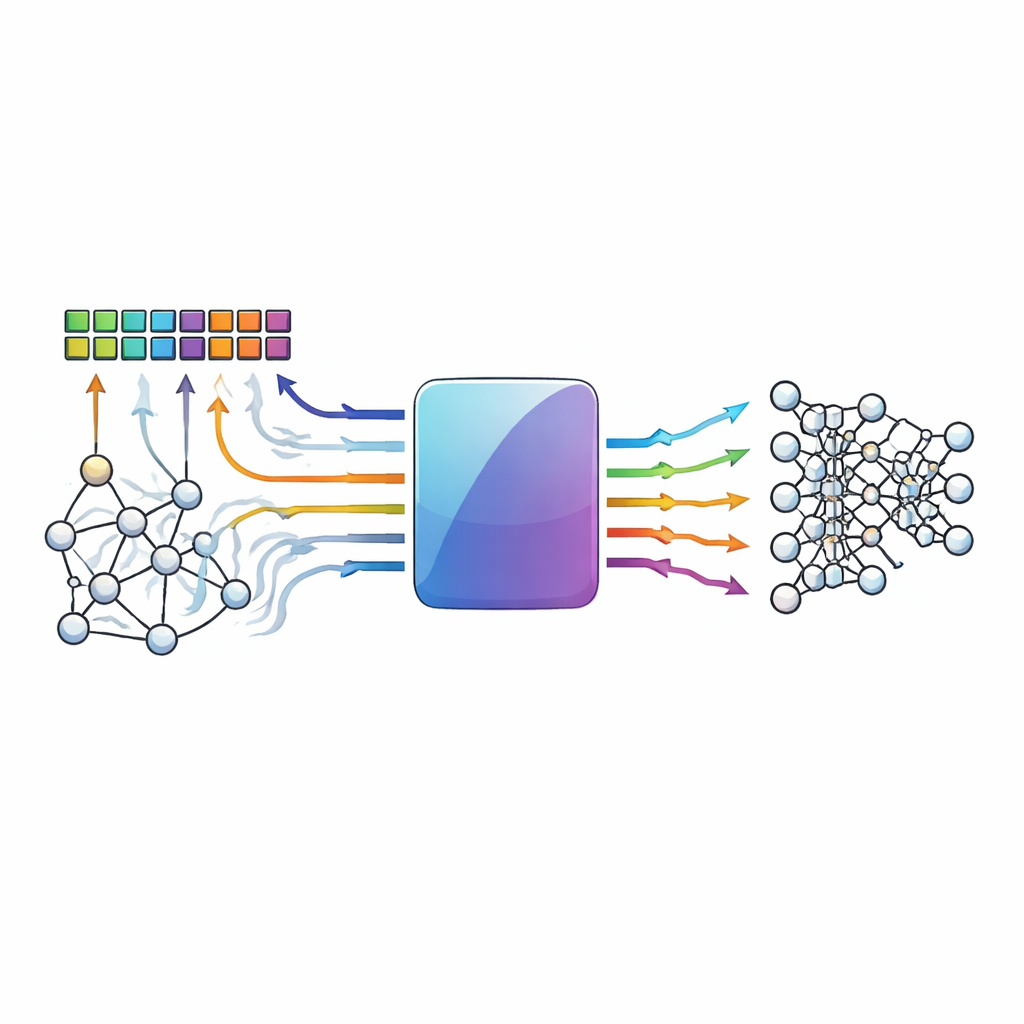
Calcolare dove risiedono i dati
I computer convenzionali sono rallentati dalla necessità di spostare i dati tra memoria e processore. I progetti di processing-in-memory evitano questo collo di bottiglia eseguendo operazioni di moltiplicazione e accumulo — il fulcro delle reti neurali — all’interno di dense matrici di celle di memoria. Dispositivi emergenti come la resistive RAM e altri elementi memristivi sono particolarmente attraenti perché possono memorizzare molti valori ed eseguire aritmetica in stile analogico in modo molto efficiente. Tuttavia, la stessa natura analogica e la variabilità dei dispositivi che li rendono potenti li rendono anche rumorosi: fluttuazioni termiche, discrepanze tra dispositivi e cadute di tensione possono spostare i valori memorizzati o i risultati calcolati lontano da dove dovrebbero essere.
Quando piccole anomalie si accumulano
In queste matrici in-memory molte righe di celle vengono attivate insieme e i loro contributi vengono sommati lungo fili condivisi. Man mano che partecipano più righe, le imperfezioni individuali si sommano, creando schemi di errore frequenti e complessi. Invece di un singolo bit errato, i progettisti osservano spesso errori multipli raggruppati nella stessa colonna di una matrice o diffusi su più colonne in modo che vanifichi i trucchi tradizionali di correzione degli errori. I codici standard solitamente assumono schemi di errore semplici e lunghezze di parola ridotte; possono non rilevare glitch multi-bit o non avere voci nelle loro tabelle di lookup per combinazioni rare ma dannose. Di conseguenza, l’accuratezza dei modelli per reti neurali profonde può calare bruscamente quando l’hardware sottostante diventa anche solo moderatamente inaffidabile.
Un nuovo tipo di rete di sicurezza digitale
Gli autori introducono un codice LDPC a bassa densità non binario (NB-LDPC) specificamente adattato all’hardware di processing-in-memory. Piuttosto che lavorare solo con zeri e uni, lo schema opera su piccoli gruppi di bit trattati come simboli in una struttura matematica chiamata campo finito costruito su un numero primo (qui, tre). Questo permette allo stesso codice di proteggere sia l’archiviazione binaria ordinaria sia le codifiche multivalore o differenziali comunemente usate negli acceleratori analogici. Il sistema aggiunge un numero modesto di simboli extra — simboli di controllo — a ciascun blocco di dati. Durante sia le normali letture di memoria sia le operazioni di moltiplicazione-accumulazione in memoria, l’hardware calcola i risultati per i dati e per i simboli di controllo insieme, così il rilevamento degli errori è naturalmente intrecciato nel calcolo.
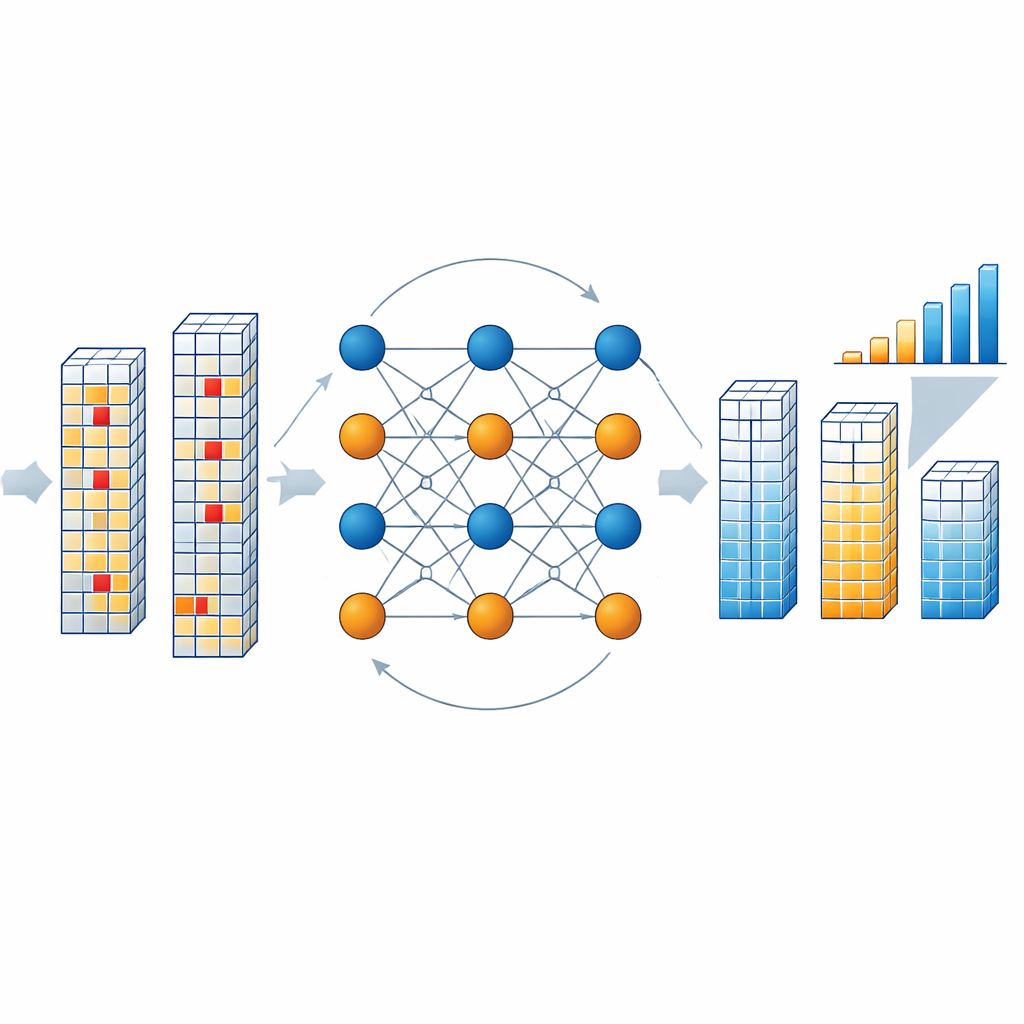
Come funziona il motore di correzione all’interno del chip
Quando il chip legge un blocco di risultati, un decoder dedicato verifica se i simboli combinati di dati e controllo rispettano le relazioni di parità definite dal codice. Se le rispettano, il blocco è considerato pulito. In caso contrario, il decoder avvia un processo iterativo in cui astrazioni di “nodi variabili” che rappresentano ciascun simbolo e “nodi di controllo” che rappresentano le condizioni di parità scambiano messaggi di probabilità. Questi messaggi stimano quanto è probabile che ogni simbolo assuma ciascuno dei valori consentiti, sulla base degli output osservati e del tasso di errore per inversione di bit previsto nella memoria. Gli autori semplificano questo ragionamento matematico pesante usando approssimazioni basate sulla distanza di Manhattan, che riducono notevolmente il costo hardware mantenendo elevata la performance. Dopo alcuni round — tipicamente tre — il decoder converge sulla versione corretta più plausibile del vettore di risultati, senza mai dover rileggere la memoria o interrompere il flusso di calcolo.
Prova su silicio e impatto sull’accuratezza AI
Per testare l’idea nella pratica, il team ha costruito un chip prototipo in un processo a 40 nanometri che combina una matrice di resistive RAM, convertitori analogico-digitali leggeri e il nuovo decoder NB-LDPC. Con una configurazione che protegge 256 simboli informativi usando 32 simboli di controllo, il decoder raggiunge un elevato tasso di codice (circa 0,8), una migliore efficienza energetica misurata di circa 88 terabit di dati corretti al secondo per watt e solo un moderato overhead di area che può essere ulteriormente ridotto condividendo un decoder tra più macro di memoria. Simulazioni su molte dimensioni di codice mostrano che proteggendo 1024 simboli di dati con 128 simboli di controllo, lo schema può migliorare il tasso di errore dei bit di quasi 60 volte. Applicato a un modello di classificazione immagini ResNet-34 in esecuzione su hardware processing-in-memory, la correzione recupera oltre 20 punti percentuali di accuratezza persi in condizioni di errore difficili.
Cosa significa per i chip AI del futuro
In termini semplici, il lavoro fornisce all’hardware di processing-in-memory un robusto “controllore ortografico” per la sua matematica, uno che comprende insiemi di simboli più ricchi e schemi di errore complessi senza rallentare il flusso di dati. Unificando la protezione sia per i dati memorizzati sia per i calcoli eseguiti al volo, e dimostrando una implementazione efficiente su silicio, lo studio mostra che gli acceleratori in-memory ad alta densità e a basso consumo non devono sacrificare l’affidabilità. Questo tipo di correzione degli errori su misura potrebbe diventare un ingrediente chiave per rendere i futuri acceleratori neuromorfici e AI sia parsimoniosi in energia sia sufficientemente affidabili per applicazioni reali, dai dispositivi mobili ai data center su larga scala.
Citazione: Shi, D., Fu, Y., Zhu, Y. et al. Correcting processing-in-memory multiply-accumulate arithmetic errors with LDPC. npj Unconv. Comput. 3, 14 (2026). https://doi.org/10.1038/s44335-026-00061-9
Parole chiave: processing-in-memory, correzione degli errori, codici LDPC, resistive RAM, hardware per reti neurali