Clear Sky Science · it
Una valutazione dell’incertezza estimativa nei grandi modelli linguistici
Perché le parole sfumate sul rischio contano davvero
Quando un medico dice che un trattamento è “probabile” che funzioni, o un meteorologo avverte che c’è “poca possibilità” di un uragano, ci affidiamo a queste parole sfumate per prendere decisioni concrete. Oggi i grandi modelli linguistici (LLM), come i chatbot online, cominciano a usare lo stesso vocabolario. Questo studio pone una domanda semplice ma cruciale: quando un’IA dice “probabilmente”, intende la stessa cosa che intendiamo noi — e può trasformare in modo affidabile numeri grezzi in parole di incertezza quotidiane?
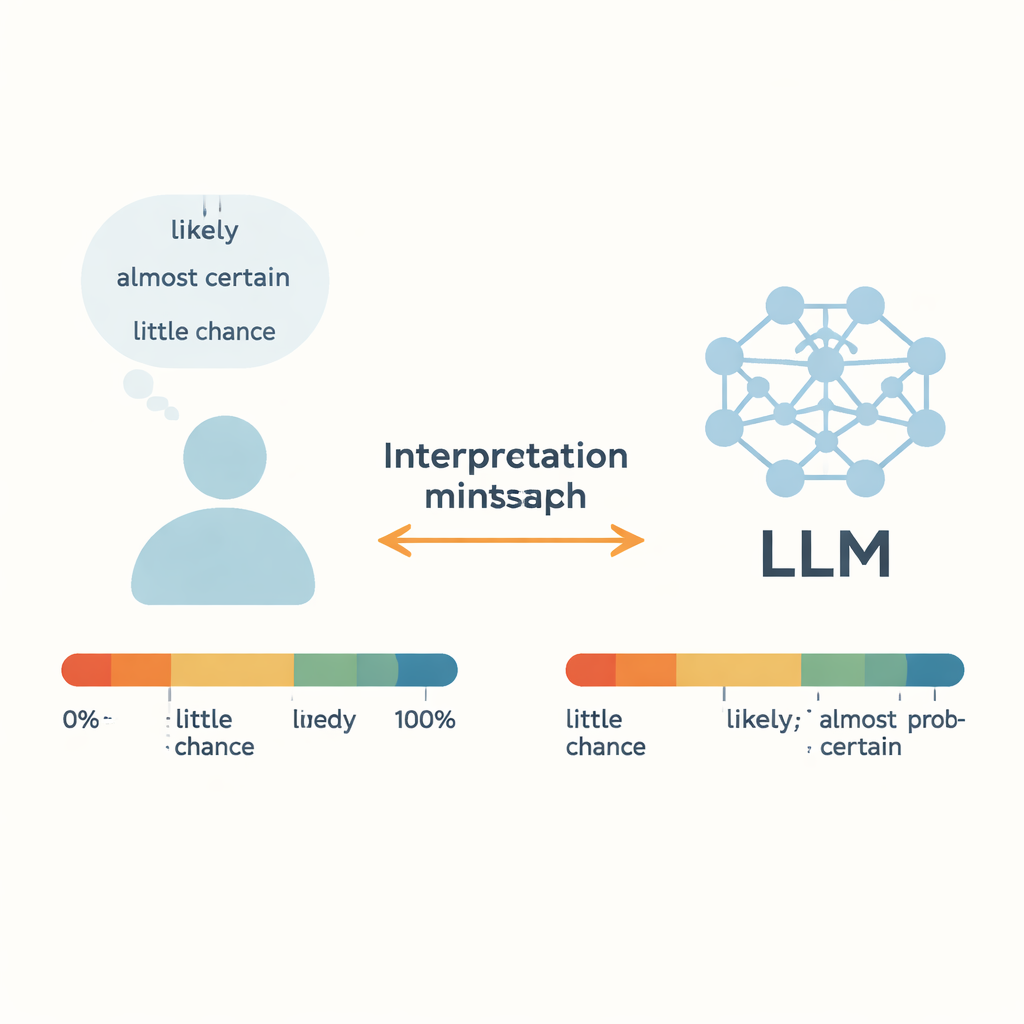
Mettere sotto il microscopio l’incertezza di tutti i giorni
Gli autori si concentrano sulle “parole di probabilità estimativa” (WEP) — termini come “quasi certo”, “probabile” e “poca possibilità” che le persone usano invece di percentuali esatte. Lavori precedenti, risalenti agli analisti dell’intelligence negli anni Sessanta, hanno cercato di collegare queste parole a probabilità numeriche sondando le persone. Questo studio confronta quei giudizi umani con l’output di cinque LLM moderni, tra cui GPT-3.5, GPT-4, i modelli Llama di Meta e un sistema cinese chiamato ERNIE-4.0. Per 17 parole di incertezza comuni, a ciascun modello sono stati forniti brevi prompt in forma narrativa in inglese o cinese e chiesto di rispondere con una probabilità numerica tra 0 e 100 percento. Ripetendo questo in molti contesti, gli autori hanno costruito distribuzioni di probabilità complete per ogni parola e ogni modello, quindi le hanno confrontate con i dati dei sondaggi umani.
Dove umani e IA parlano la stessa lingua
Per le espressioni più estreme — come “quasi certo” all’estremo alto e “quasi nessuna possibilità” all’estremo basso — LLM e umani corrispondono sorprendentemente bene. Sia le persone sia i modelli tendono a raggruppare queste frasi in intervalli ristretti di probabilità alte o basse, suggerendo che questi termini forti hanno significati relativamente stabili attraverso i contesti. Lo stesso vale per “più o meno pareggio”, che la maggior parte degli umani e dei modelli interpreta come una probabilità intorno al 50–50. I test statistici mostrano poche differenze significative tra le distribuzioni umane e quelle dei modelli per queste parole particolari, implicando che gli LLM possono catturare i casi netti di quasi-certezza o quasi-impossibilità con una precisione simile a quella umana.
Dove i significati si allontanano silenziosamente
Le parole ambigue, di mezzo, raccontano una storia diversa. Per espressioni come “probabile”, “probabile”, “dubitamo” e “poca possibilità”, le interpretazioni numeriche dei modelli differiscono significativamente dai giudizi umani. GPT-4, pur essendo complessivamente più capace di GPT-3.5, mostra spesso scarti maggiori. Gli autori suggeriscono che ciò può dipendere dal fatto che tali parole mescolano due elementi: un senso di probabilità e l’atteggiamento o la posizione del parlante. Nelle conversazioni reali, “probabile” può suonare prudente o sicuro a seconda del tono e del contesto, e “dubitamo” può esprimere scetticismo più che una probabilità precisa. Addestrati su enormi quantità di testo di generi misti presi da Internet, gli LLM possono mediamente inglobare usi contrastanti, smussando queste sottigliezze. Il risultato è una discreta discrepanza: umani e IA possono vedere la stessa frase e attribuire silenziosamente numeri diversi alla stessa parola.
Genere, lingua ed echi culturali
I ricercatori hanno anche testato come il linguaggio riferito al genere e lingue diverse plasmano queste parole di probabilità. Quando i prompt facevano riferimento a “lui” o “lei” invece di soggetti neutri, GPT-3.5 e GPT-4 spesso producevano stime di probabilità meno variabili, più “bloccate”, talvolta collassando in un singolo valore. Questo suggerisce che i modelli potrebbero aver assorbito schemi rigidi da stereotipi nei dati di addestramento, anche se le medie complessive per prompt maschili e femminili risultavano simili. Confrontando prompt in inglese e cinese, i modelli GPT mostravano spostamenti evidenti nell’interpretazione delle stesse parole di incertezza. ERNIE-4.0, addestrato principalmente su testi cinesi, si è avvicinato maggiormente ai parlanti cinesi su molti termini ma ha comunque sovra- o sottostimato certe espressioni. Questi risultati evidenziano che il modo in cui un’IA parla di incertezza dipende non solo dalla parola scelta, ma anche dalla lingua e dai modelli culturali incorporati nel suo addestramento.
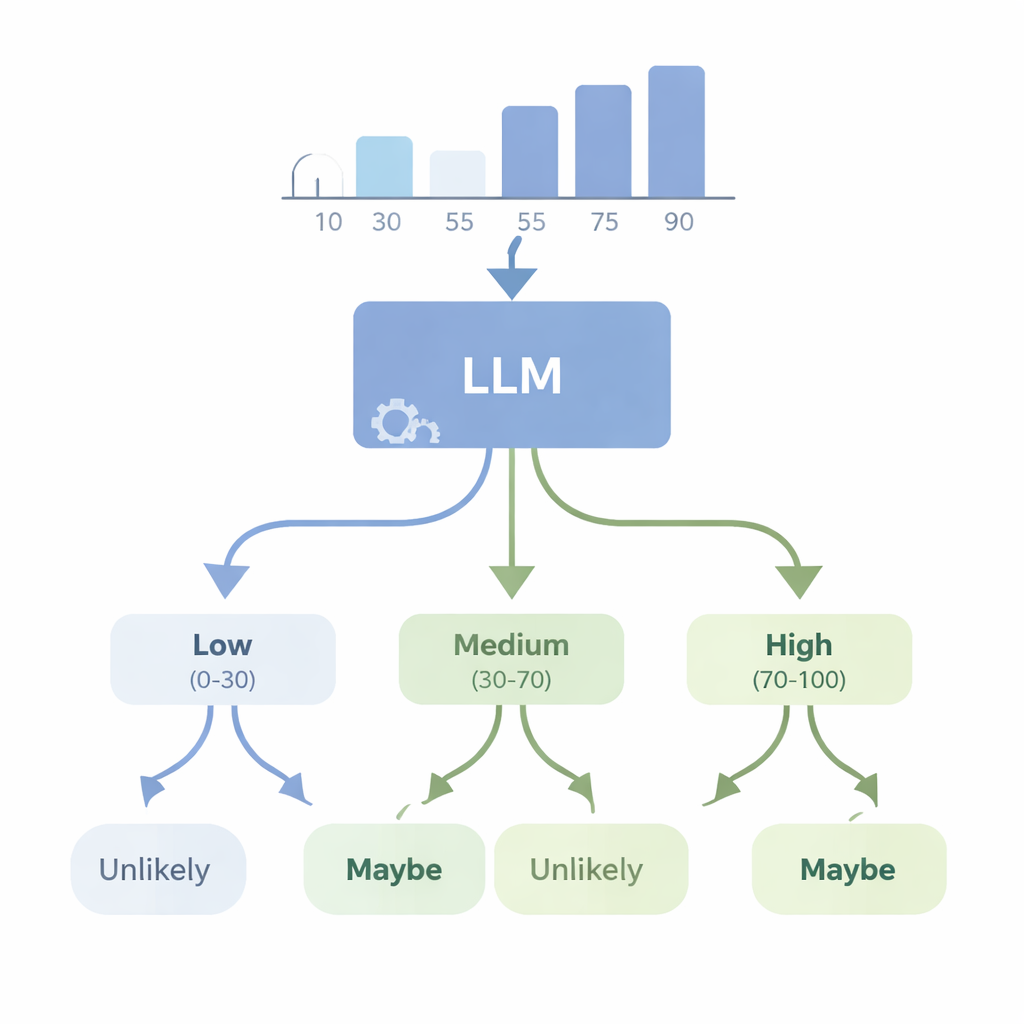
Le IA possono trasformare numeri in dubbi in linguaggio semplice?
In una seconda serie di esperimenti, gli autori hanno esaminato il problema inverso: un modello avanzato come GPT-4 può partire da dati numerici e scegliere una parola di incertezza appropriata? Hanno fornito al modello set di dati semplici — come elenchi di altezze o punteggi di test — e gli hanno chiesto di scegliere la WEP più adatta (per esempio “quasi certamente”, “probabile”, “forse”, “improbabile” o “quasi certamente no”) per enunciati su esiti futuri. Hanno poi valutato GPT-4 con quattro nuove misure di “coerenza” che verificano se le scelte lessicali hanno senso logico quando le probabilità aumentano o diminuiscono, quando vengono descritte eventi complementari e quando i numeri sottostanti cambiano in modo controllato. GPT-4 ha fatto molto meglio del caso e spesso ha seguito approssimativamente i cambiamenti di probabilità, ma è rimasto lontano dalla coerenza perfetta. In alcuni test ha risposto quasi allo stesso modo attraverso diversi livelli di confidenza, suggerendo che talvolta tratta queste parole come etichette ampie piuttosto che come una scala finemente sintonizzata collegata ai dati reali.
Cosa significa per decisioni nel mondo reale
Per i lettori, il messaggio è cautelativo ma non allarmista. Gli LLM possono già imitare le nostre espressioni più forti di certezza e impossibilità, e spesso possono riassumere i dati in affermazioni ragionevoli come “probabile” o “improbabile”. Ma questo studio mostra che per molte parole di incertezza di uso quotidiano la loro calibrazione interna non corrisponde pienamente all’intuizione umana, e la loro mappatura da numeri a lingua può essere incoerente. In ambiti come la medicina, le politiche pubbliche o la comunicazione scientifica — dove piccoli spostamenti nel modo in cui formuliamo il rischio o la fiducia possono avere importanza — un “probabilmente” del modello potrebbe non essere lo stesso che intendi tu. Gli autori sostengono che per usare questi sistemi in sicurezza dobbiamo trattare le parole di incertezza come un codice condiviso che va ancora accuratamente allineato, testato e forse supportato da riferimenti numerici espliciti, invece di presumere che umano e macchina significhino la stessa cosa per impostazione predefinita.
Citazione: Tang, Z., Shen, K. & Kejriwal, M. An evaluation of estimative uncertainty in large language models. npj Complex 3, 8 (2026). https://doi.org/10.1038/s44260-026-00070-6
Parole chiave: incertezza linguistica, grandi modelli linguistici, parole di probabilità, comunicazione umano-AI, interpretazione del rischio