Clear Sky Science · it
Infrastruttura open‑source basata sull’intelligenza artificiale per accelerare la scoperta di materiali e la produzione avanzata
Perché materiali più intelligenti contano nella vita quotidiana
Dalle batterie dei telefoni che durano più a lungo agli imballaggi alimentari compostabili e a fonti di energia più pulite, molte delle innovazioni di domani dipendono dall’invenzione di materiali migliori. Questo articolo spiega come l’intelligenza artificiale (IA), il software open‑source e i laboratori automatizzati stanno ridefinendo il modo in cui scopriamo e produciamo questi materiali. Invece di affidarsi al lento metodo del tentativo ed errore in laboratorio, i ricercatori stanno costruendo infrastrutture condivise guidate dall’IA in grado di esplorare enormi spazi di progetto, ridurre gli sprechi e tenere sotto controllo gli impatti ambientali.
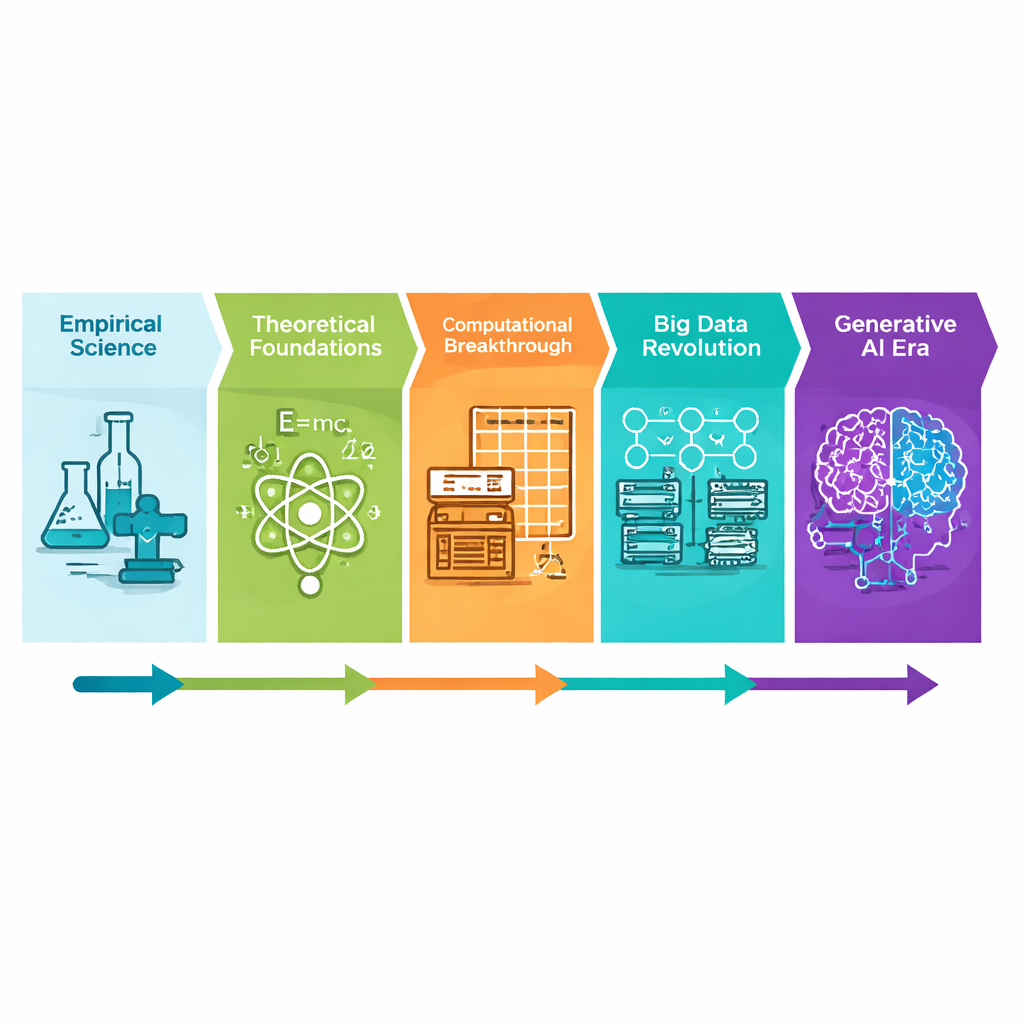
Dal tentativo e errore alle macchine che imparano
Per gran parte della storia, i nuovi materiali sono emersi tramite pazienti sperimentazioni: mescolare ingredienti, riscaldare o raffreddare e osservare cosa succede. Nel ventesimo secolo, la fisica e la chimica hanno fornito agli scienziati equazioni per prevederne il comportamento e, più tardi, potenti computer hanno permesso di simulare i materiali atomo per atomo. Negli ultimi due decenni, masse di dati sperimentali e di simulazione hanno permesso ai modelli di machine‑learning di individuare schemi e prevedere proprietà più rapidamente di quanto possa fare una persona. Oggi, una nuova ondata di IA “generativa” non si limita a prevedere come si comportano materiali noti; propone ricette del tutto nuove che potrebbero essere più resistenti, più leggere, più economiche o più ecologiche di qualsiasi cosa realizzata finora.
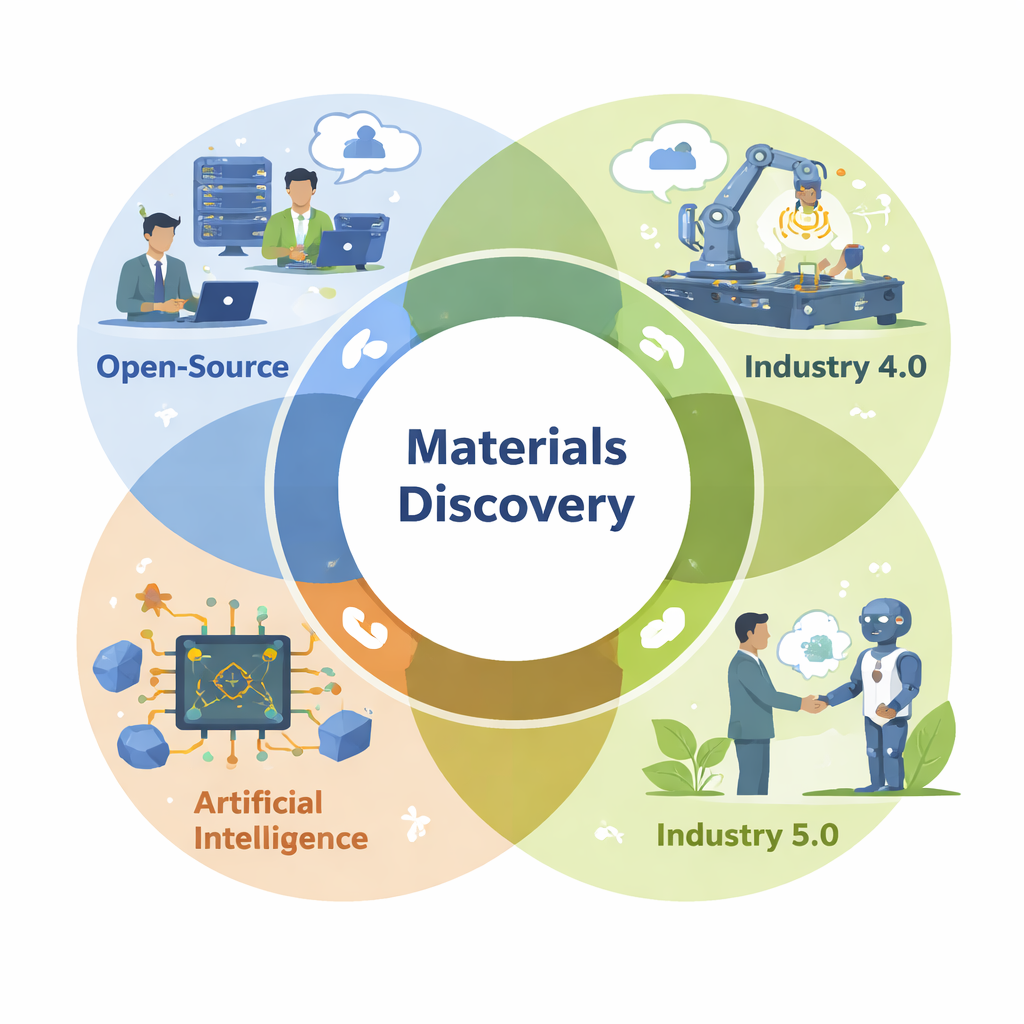
Perché strumenti aperti e dati condivisi fanno la differenza
La recensione sostiene che le piattaforme open‑source sono importanti quanto l’IA stessa. Database pubblici come il Materials Project e NOMAD contengono milioni di proprietà calcolate e misurate per metalli, polimeri, batterie e altro. Chiunque può scaricare questi dati per addestrare modelli o verificare risultati, accelerando i progressi e aumentando la fiducia. Librerie software open aiutano i ricercatori a pulire e combinare dati disomogenei, costruire simulazioni ed eseguire modelli di machine‑learning su basi di codice comuni. Questa infrastruttura condivisa abbassa la soglia di accesso per laboratori e aziende più piccoli, riduce sforzi duplicati e facilita la riproducibilità dei risultati—ingredienti chiave per una scienza affidabile.
Laboratori autonomi, fabbriche intelligenti e dati affidabili
Un tema centrale del documento è l’ascesa di laboratori “autonomi” e di fabbriche intelligenti. In questi contesti, robot mescolano e testano campioni 24 ore su 24 mentre l’IA sceglie il prossimo esperimento in base ai risultati precedenti. I digital twin—copie virtuali di apparecchiature e processi—permettono ai ricercatori di esplorare ipotesi prima di intervenire sull’hardware reale. Per mantenere le previsioni fisicamente sensate, nuovi metodi combinano modelli guidati dai dati con leggi fondamentali della natura. Su scala industriale, cloud e edge computing lavorano insieme: grandi insiemi di dati vengono processati in data center remoti, mentre le decisioni rapide sono prese vicino alle macchine. Blockchain e strumenti simili possono tracciare l’origine dei dati, chi li ha modificati e come i materiali si muovono nelle catene di approvvigionamento, aiutando a proteggere la proprietà intellettuale e a verificare le dichiarazioni di sostenibilità.
Bilanciare velocità, pianeta e persone
Gli autori sottolineano inoltre che più veloce non è automaticamente meglio se avviene a scapito del pianeta. Addestrare grandi modelli di IA ed eseguire massicce simulazioni può consumare molta elettricità ed emettere gas serra significativi. L’articolo passa in rassegna strumenti che stimano l’uso energetico e l’impronta di carbonio dei carichi di lavoro IA e incoraggia valutazioni del ciclo di vita che includano sia l’hardware di calcolo sia i data center. Evidenzia pratiche emergenti come l’uso di chip più efficienti, la scelta di fonti di energia più pulite, il riuso prolungato dell’hardware e la progettazione di modelli “della dimensione giusta” piuttosto che semplicemente più grandi. Linee guida etiche e IA interpretabile vengono presentate come salvaguardie essenziali affinché i sistemi automatizzati restino trasparenti, equi e sotto supervisione umana.
Sguardo al futuro: una tabella di marcia condivisa per materiali migliori
In chiusura, l’articolo delinea una tabella di marcia per costruire infrastrutture end‑to‑end guidate dall’IA che servano sia l’innovazione sia la sostenibilità. Invoca dati facili da trovare e riutilizzare, modelli che spieghino il loro ragionamento e schemi di apprendimento federato che permettano alle istituzioni di collaborare senza esporre dati sensibili. Indica anche opportunità future, dai computer quantistici che potrebbero simulare materiali complessi con maggiore accuratezza al machine learning ispirato alla quantistica che affronta problemi di progettazione complessi. Per un lettore non specialista, il messaggio è chiaro: combinando dati aperti, algoritmi intelligenti e progettazione responsabile, possiamo accelerare notevolmente la scoperta di materiali più sicuri e sostenibili che miglioreranno silenziosamente i prodotti di uso quotidiano e contribuiranno ad affrontare sfide globali come il cambiamento climatico e la scarsità di risorse.
Citazione: Salas, M., Singh, A., Pignataro, C. et al. AI-powered open-source infrastructure for accelerating materials discovery and advanced manufacturing. Commun Mater 7, 65 (2026). https://doi.org/10.1038/s43246-026-01105-0
Parole chiave: scoperta dei materiali, intelligenza artificiale, piattaforme open‑source, laboratori autonomi, produzione sostenibile