Clear Sky Science · it
Predire e interpretare le risposte ai farmaci specifiche per tipo cellulare nel regime dei dati scarsi usando priori induttivi
Perché questa ricerca conta per le medicine future
Quando un nuovo farmaco viene testato, una delle maggiori incognite è quanto diversamente influenzerà i molti tipi di cellule del nostro organismo. Un composto che aiuta un tipo cellulare può avere scarso effetto su un altro o perfino arrecare danno. Generare sperimentalmente queste informazioni per migliaia di farmaci e innumerevoli tipi cellulari è troppo lento e costoso. Questo lavoro presenta un approccio computazionale, chiamato PrePR-CT, che apprende a prevedere come tipi cellulari individuali rispondono ai farmaci, anche quando sono disponibili solo dati limitati. Lo studio indica strade più rapide, meno costose e più precise per esplorare in silico potenziali medicinali prima di impegnarsi in costosi esperimenti di laboratorio e studi clinici.
Osservare l’interno delle cellule invece che solo i farmaci
I tradizionali screening farmacologici spesso trattano le cellule come se fossero tutte uguali e si concentrano principalmente sulle medie globali. In realtà, cellule immunitarie, epatociti e cellule tumorali possono reagire in modo molto diverso allo stesso composto. Gli autori sostengono che per prevedere queste differenze un modello deve comprendere il cablaggio interno di ciascun tipo cellulare: quali geni tendono ad essere attivi insieme e come tali schemi definiscono l’identità della cellula. Costruiscono "mappe" del tipo cellulare esaminando quali geni nelle cellule non perturbate (controllo) aumentano e diminuiscono in concerto. Ogni mappa è rappresentata come una rete, dove i nodi rappresentano geni e i collegamenti riflettono forte co-attività. Queste reti fungono da conoscenza a priori su come un dato tipo cellulare è organizzato prima che venga aggiunto qualsiasi farmaco.
Un motore di apprendimento consapevole della rete
PrePR-CT combina tre ingredienti: la rete di attività genica di un tipo cellulare, l'espressione genica di base di quel tipo cellulare e una descrizione compatta della struttura chimica del farmaco. Il modello utilizza una classe di reti neurali progettate per grafi per digerire la rete genica della cellula ed estrarre un riassunto che cattura i suoi schemi caratteristici. In parallelo, trasforma ogni farmaco in un’impronta numerica derivata dalla sua struttura molecolare. Questi elementi vengono alimentati in un modulo di predizione a valle che apprende, a partire dagli esperimenti disponibili, come un dato farmaco sposterà la distribuzione dell’attività genica in quel tipo cellulare. Piuttosto che produrre un singolo numero per gene, il metodo stima sia la variazione media sia quanto sia variabile la risposta tra cellule individuali, caratteristica cruciale per comprendere effetti sottili e marcati allo stesso modo.
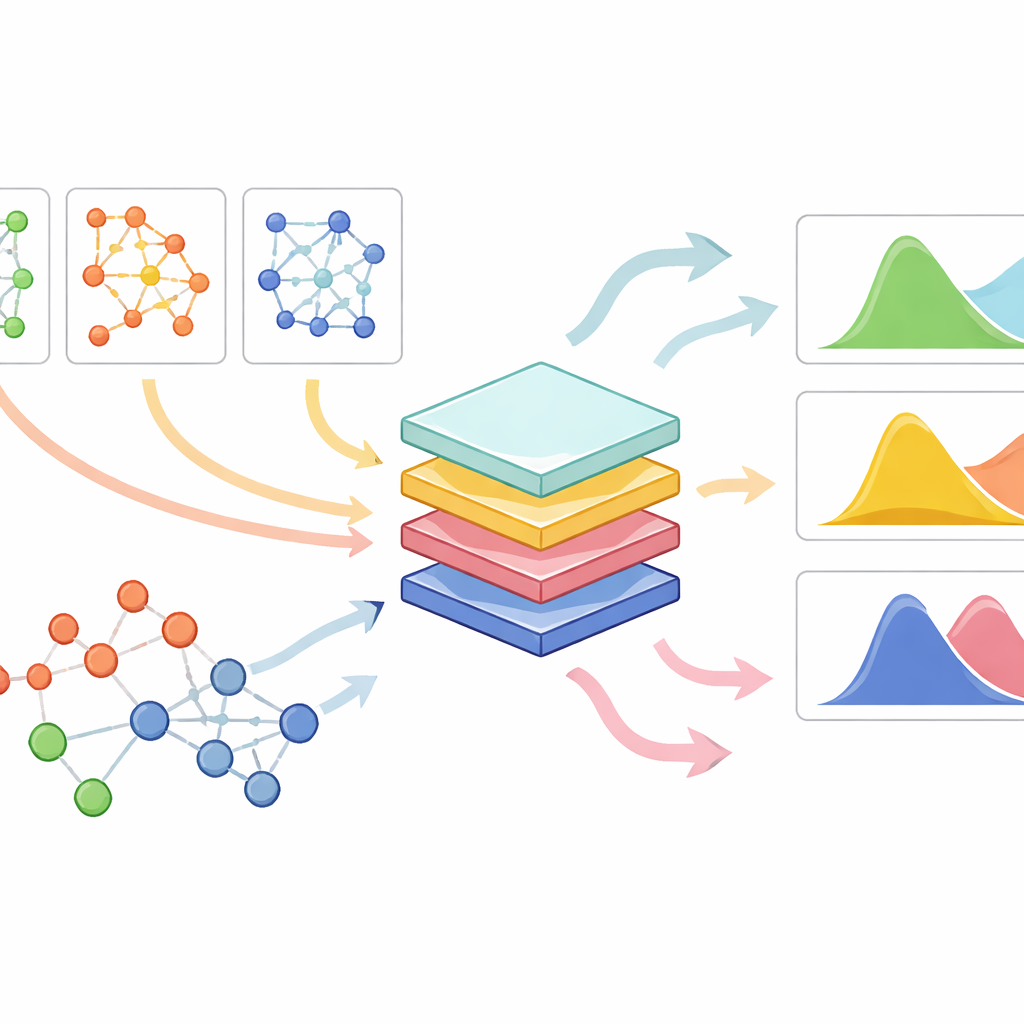
Funzionare su molti tipi cellulari, farmaci e insiemi di dati piccoli
I ricercatori hanno testato PrePR-CT su un’ampia raccolta di dataset, incluse cellule del sangue umano esposte a segnali immunitari, più linee cellulari tumorali trattate con vari composti, cellule epatiche di topo esposte a un inquinante e screening farmacologici su larga scala da risorse pubbliche. In scenari impegnativi in cui un intero tipo cellulare veniva escluso durante l’addestramento, il modello riusciva comunque a predire come quel nuovo tipo cellulare avrebbe risposto a un farmaco già noto, spesso con accuratezza superiore ai modelli generativi precedenti. Allo stesso modo, quando veniva escluso un farmaco nuovo ma il tipo cellulare era familiare, il metodo anticipava correttamente il suo impatto usando solo la sua impronta chimica. È importante che il modello restasse efficace anche quando addestrato su un numero relativamente piccolo di cellule, un contesto in cui molti approcci di deep learning incontrano difficoltà.
Dal black box agli indizi sui meccanismi
Oltre alla mera predizione, gli autori hanno voluto sapere se il loro modello potesse offrire intuizioni su quali geni e vie siano alla base della risposta di una cellula. L’architettura basata su grafi include un meccanismo di attenzione che mette in evidenza i geni che il modello ritiene particolarmente influenti in ciascun tipo cellulare. Molti di questi geni a "alta attenzione" non erano i soliti sospetti segnalati dall’analisi standard di espressione differenziale, eppure si raggruppavano in vie correlate al sistema immunitario coerenti con la biologia dei farmaci testati. Quando i ricercatori hanno deliberatamente perturbato questi geni influenti nell’ingresso del modello, la qualità delle predizioni è calata, specialmente per i geni più reattivi, suggerendo che i punteggi di attenzione indicano attori meccanisticamente significativi più che rumore.
Cosa significa questo per progettare farmaci migliori
In termini semplici, questo lavoro mostra che fornire ai modelli di intelligenza artificiale una visione strutturata di come ogni tipo cellulare è cablato—la sua rete genica interna—migliora notevolmente la loro capacità di prevedere come i farmaci rimodelleranno quelle cellule, anche quando sono disponibili dati modesti. PrePR-CT non sostituisce gli esperimenti, ma può aiutare a restringere quali composti e tipi cellulari valga la pena testare e suggerire perché certe cellule reagiscono in un certo modo. Con la crescita dei dataset e l’integrazione di ulteriori caratteristiche cellulari, tali approcci potrebbero diventare strumenti chiave per adattare terapie a tessuti o tipi cellulari di pazienti specifici, riducendo tentativi ed errori in laboratorio e avvicinando medicine più precise alla realtà.
Citazione: Alsulami, R., Lehmann, R., Khan, S.A. et al. Predicting and interpreting cell-type-specific drug responses in the small-data regime using inductive priors. Nat Mach Intell 8, 461–473 (2026). https://doi.org/10.1038/s42256-026-01202-2
Parole chiave: predizione della risposta ai farmaci, trascrittomica a cellula singola, reti neurali a grafo, scoperta di farmaci, specificità per tipo cellulare