Clear Sky Science · it
ADMM stocastico approssimato precondizionato per modelli profondi
Allenamento più intelligente per un'IA più intelligente
I moderni sistemi di intelligenza artificiale, dai chatbot ai generatori di immagini, si basano su reti neurali di grandi dimensioni che sono notoriamente difficili e costose da addestrare. Man mano che aziende e ricercatori distribuiscono i dati su molti dispositivi e server, i metodi di training standard odierni spesso rallentano, diventano instabili o semplicemente non riescono a gestire la complessità dei dati reali. Questo articolo presenta una nuova famiglia di algoritmi di addestramento, centrata su un metodo chiamato PISA, che promette apprendimento più veloce e affidabile per un ampio spettro di modelli profondi, facendo meno assunzioni matematiche sui dati.
Perché i metodi attuali incontrano difficoltà
La maggior parte dei modelli di deep learning viene addestrata con varianti della discesa del gradiente stocastica, un approccio che sposta ripetutamente i parametri del modello nella direzione che riduce l'errore. Nel corso degli anni molte migliorie—come Adam, RMSProp e altre—hanno cercato di rendere questi aggiornamenti più intelligenti adattando i passi o aggiungendo momento. Tuttavia, questi metodi di solito assumono che i dati di addestramento siano ben mescolati e statisticamente simili tra le macchine, e che alcune quantità matematiche rimangano limitate. In pratica, soprattutto in contesti come il federated learning in cui telefoni o dispositivi edge contengono dati molto diversi, queste assunzioni vengono spesso violate, causando convergenza lenta o prestazioni scadenti.
Un nuovo modo di coordinare molti apprendenti
Gli autori si basano su un diverso quadro di ottimizzazione noto come metodo delle direzioni alternate dei moltiplicatori (ADMM), efficace nello scomporre un problema grande in molti sottoproblemi risolvibili in parallelo. Il loro contributo principale, PISA (preconditioned inexact stochastic ADMM), mantiene i punti di forza di ADMM evitando i limiti tipici—come la necessità di calcolare gradienti completi su tutti i dati o di effettuare costose inversioni di matrici. Invece, PISA permette a ogni client o nodo di lavoro di aggiornare la propria copia del modello usando solo un mini-batch di dati, quindi coordina questi aggiornamenti tramite una variabile centrale. Matrici di "precondizionamento" progettate con cura rimodellano le direzioni di aggiornamento in modo che l'apprendimento proceda più fluentemente ed efficientemente. 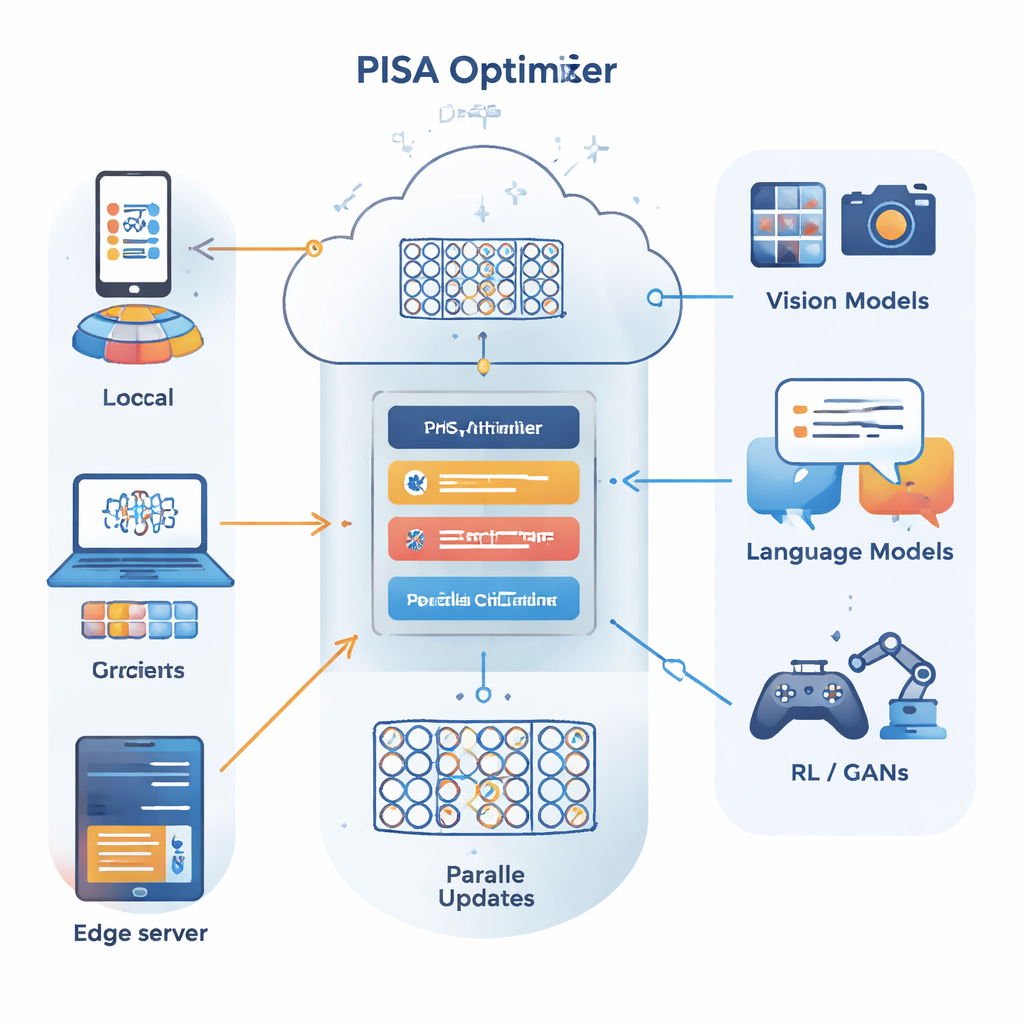
Garanzie più solide con assunzioni più blande
Una caratteristica distintiva di PISA è la sua base teorica. Gli autori dimostrano che il loro algoritmo converge sotto una singola assunzione relativamente blanda: che il gradiente della funzione di perdita sia Lipschitz continuo in una regione limitata, condizione soddisfatta da molte perdite standard delle reti neurali. A differenza della maggior parte dei metodi stocastici, PISA non richiede che i gradienti siano non distorti (unbiased), che abbiano varianza limitata o che provengano da dati perfettamente miscelati. Nonostante questo quadro rilassato, il metodo ottiene una velocità di convergenza lineare in termini di quanto rapidamente i valori della funzione e gli aggiornamenti dei parametri si stabilizzano, collocandosi tra gli algoritmi con migliori prestazioni nella tabella comparativa fornita. Questo rende PISA particolarmente interessante per distribuzioni di dati eterogenee e non uniformi, comuni nelle applicazioni reali.
Varianti pratiche per reti profonde reali
Per rendere il quadro praticabile su grandi reti neurali, gli autori introducono due varianti efficienti, SISA e NSISA. SISA utilizza informazioni sul secondo momento—essentialmente tracciando quanto siano stati grandi gli aggiornamenti passati in ciascuna direzione dei parametri—per formare precondizionatori diagonali semplici, simili alle idee dietro Adam e RMSProp ma integrati nella struttura ADMM. NSISA compie un passo ulteriore incorporando una tecnica nota come ortogonalizzazione di Newton–Schulz, ispirata dall'ottimizzatore Muon, per allineare meglio il momento con le direzioni utili nello spazio dei parametri. Entrambe le varianti mantengono le garanzie di convergenza di PISA pur mantenendo il carico computazionale abbastanza leggero da essere compatibile con GPU moderne e modelli di grandi dimensioni.
Prestazioni su visione, linguaggio e modelli generativi
Gli autori testano SISA e NSISA su un ampio ventaglio di compiti di deep learning. Negli esperimenti di federated learning con distribuzioni di etichette volutamente sbilanciate—un contesto difficile in cui ogni client vede solo un sottoinsieme di classi—SISA supera nettamente metodi popolari come FedAvg, FedProx, FedNova e Scaffold, raggiungendo accuratezze di test molto più alte su benchmark come MNIST e CIFAR-10. Per la classificazione di immagini standard con modelli come ResNet e DenseNet su CIFAR-10 e ImageNet, SISA eguaglia o supera ottimizzatori robusti come SGD con momentum, AdaBelief e AdamW. Nel fine-tuning di modelli linguistici GPT2 di dimensioni crescenti, NSISA ottiene una perdita di validazione più bassa in meno tempo di esecuzione rispetto a ottimizzatori specializzati come Shampoo, SOAP, Adam-mini e Muon, con il vantaggio che diventa più evidente per i modelli più grandi. Stabilizza anche l'addestramento delle reti antagoniste generative, raggiungendo punteggi di Fréchet Inception Distance più bassi, che misurano la qualità visiva e la diversità delle immagini generate. 
Cosa significa per l'IA di tutti i giorni
In termini pratici, questo lavoro mostra che è possibile addestrare modelli di IA potenti in modo più rapido e affidabile, anche quando i dati sono disordinati, sbilanciati o distribuiti su molti dispositivi. Ridisegnando il processo di ottimizzazione sottostante invece di limitarsi a regolare i tassi di apprendimento, PISA e le sue varianti offrono uno strumento unificato che funziona bene per visione, linguaggio, apprendimento per rinforzo e compiti generativi. Per gli utenti finali il vantaggio può tradursi in personalizzazione più intelligente sui telefoni, modelli linguistici e di immagini più capaci e uso più efficiente delle risorse computazionali nei grandi data center—tutto abilitato da un algoritmo di addestramento che si adatta meglio alle realtà dei sistemi di IA moderni.
Citazione: Zhou, S., Wang, O., Luo, Z. et al. Preconditioned inexact stochastic ADMM for deep models. Nat Mach Intell 8, 234–245 (2026). https://doi.org/10.1038/s42256-026-01182-3
Parole chiave: ottimizzazione deep learning, federated learning, ADMM stocastico, modelli di linguaggio di grandi dimensioni, dati eterogenei