Clear Sky Science · it
Disvelare i meccanismi molecolari causali del diabete di tipo 2 nelle popolazioni globali e nei tessuti rilevanti per la malattia
Perché comprendere le radici del diabete è importante
Il diabete di tipo 2 colpisce centinaia di milioni di persone nel mondo, eppure sappiamo sorprendentemente poco su quali interruttori molecolari nel corpo causino realmente la malattia e quali la accompagnino soltanto. Questo studio esplora in profondità il nostro DNA e diversi organi per identificare quali geni e proteine spingono effettivamente la glicemia verso il diabete e quali invece esercitano un effetto protettivo. Incluendo persone di origini diverse e esaminando più tessuti chiave, i ricercatori ci avvicinano a strategie di prevenzione e terapie più precise, efficaci per molte popolazioni e non solo per quelle di discendenza europea.
Osservare il mondo e l’interno del corpo
Il gruppo ha iniziato con dati genetici di oltre 2,5 milioni di persone raccolti dall’Iniziativa Genomica Globale sul Diabete di Tipo 2. Invece di limitarsi a chiedere quali varianti del DNA siano associate al diabete, hanno posto una domanda più potente: quali varianti modificano l’attività di specifici geni o proteine nel corpo e tali cambiamenti a loro volta alterano il rischio di diabete? Per farlo hanno usato un approccio statistico chiamato randomizzazione mendeliana, che tratta le differenze genetiche naturali come una sorta di sperimentazione randomizzata incorporata. Hanno analizzato oltre 20.000 misure di attività genica e più di 1.600 proteine plasmatiche in persone di quattro gruppi ancestrali — europeo, africano, americano con ascendenze miste e dell’Asia orientale — e hanno poi ripetuto le analisi in sette tessuti centrali per il controllo della glicemia, tra cui pancreas, isole produttrici di insulina, fegato, muscolo e diversi depositi adiposi.
Trovare leve molecolari che aumentano o riducono il rischio
Tracciando questi percorsi genetici, i ricercatori hanno identificato 335 geni e 46 proteine plasmatiche i cui livelli predetti geneticamente hanno un impatto causale sul rischio di diabete di tipo 2, e hanno confermato molti di questi risultati in coorti indipendenti. Alcune delle leve molecolari identificate erano già sospettate, come MTNR1B, un gene coinvolto nel rilascio di insulina dalle cellule delle isole pancreatiche, e BAK1, che influenza la morte cellulare in pancreas e tessuto adiposo. Altri sono risultati attori nuovi o meno noti, tra cui CPXM1, una proteina legata allo sviluppo del tessuto adiposo e alla resistenza all’insulina, e HIBCH, un gene coinvolto nella funzione mitocondriale. Complessivamente, hanno catalogato 923 geni e 46 proteine con evidenze che modificare la loro attività in almeno un tessuto può alterare le probabilità di sviluppare il diabete.
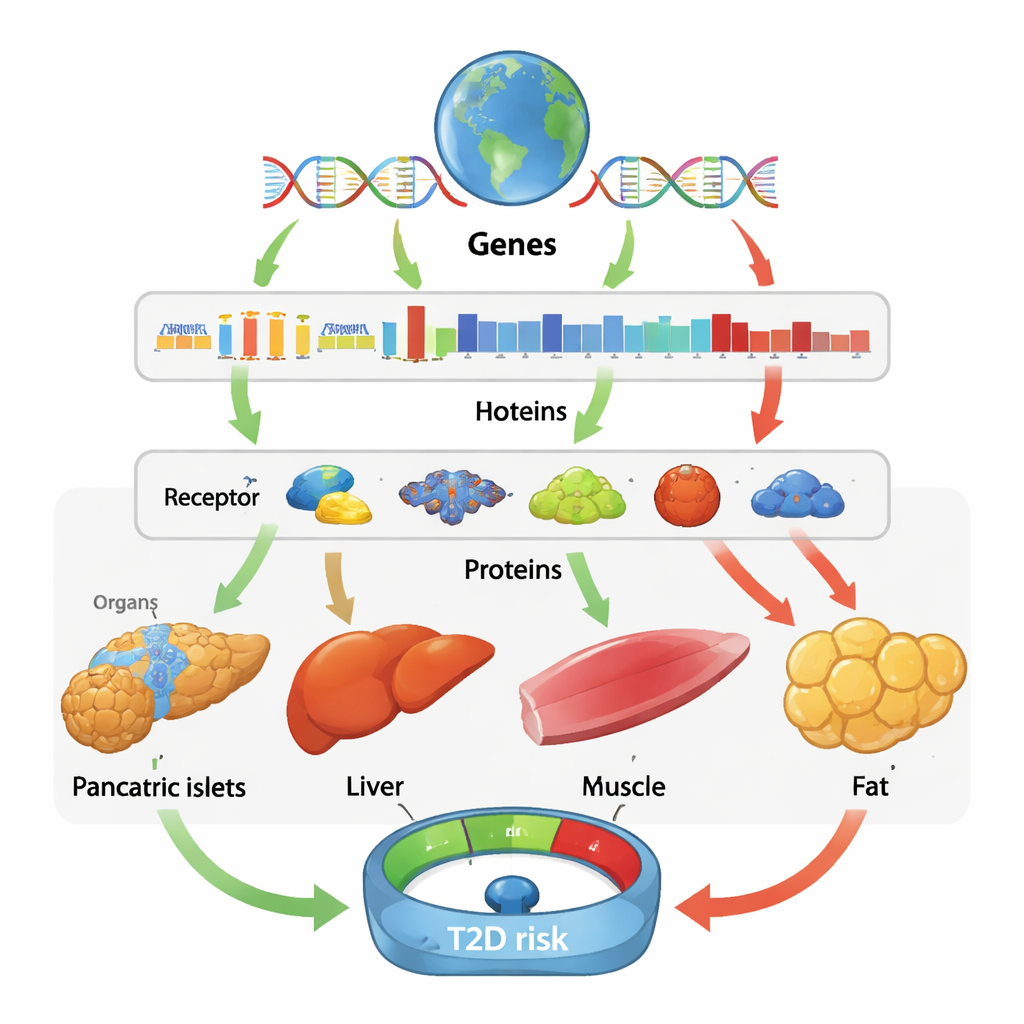
Stessi geni, storie diverse tra tessuti e popolazioni
Una lezione sorprendente è che l’effetto di un gene è spesso altamente tessuto-specifico. Per esempio, una maggiore attività di BAK1 nel pancreas e nelle isole sembra aumentare il rischio di diabete, probabilmente contribuendo alla perdita delle cellule produttrici di insulina, mentre livelli più elevati di BAK1 nel grasso e nel muscolo sembrano essere protettivi. HIBCH ha mostrato un pattern simile: in alcuni tessuti maggiore attività riduceva il rischio di diabete, mentre in altri lo aumentava. Questi risultati dimostrano che osservare solo il sangue può perdere biologie cruciali che avvengono all’interno degli organi, e che la stessa molecola può essere benefica in un tessuto ma dannosa in un altro. Al contrario, confrontando i risultati tra le ancestrie, è emersa una differenza relativamente modesta nelle dimensioni dell’effetto, suggerendo che molti meccanismi causali di base sono condivisi a livello globale, anche se alcuni segnali — come specifiche proteine protettive o di rischio in gruppi dell’Asia orientale o africani — sono stati rilevabili solo grazie ai dati non europei.
Collegare le scoperte nuove alla biologia nota del diabete
Per verificare se il loro approccio avesse senso biologico, gli autori hanno confrontato i geni causali con elenchi curati di geni legati al diabete provenienti da studi umani e esperimenti su topi. I geni con le evidenze pregresse più forti di coinvolgimento nel diabete erano molto più propensi a mostrare effetti causali nelle loro analisi rispetto a geni scelti a caso. Inoltre, i tessuti in cui questi effetti causali apparivano corrispondevano ai meccanismi di malattia noti: i geni collegati al fallimento delle cellule beta tendevano a essere più rilevanti nelle isole pancreatiche, mentre i geni associati alla sindrome metabolica mostravano i loro effetti più marcati nel grasso viscerale (grasso profondo addominale). Questo allineamento supporta l’idea che la pipeline statistica stia effettivamente individuando meccanismi e non solo correlazioni.
Cosa significa per trattamenti e prevenzione futuri
Per i non specialisti, la conclusione principale è che questo lavoro trasforma lunghe, impersonali liste di varianti del DNA in una mappa più chiara di geni specifici, proteine e organi che effettivamente guidano il diabete di tipo 2. Separando causa ed effetto e rivelando quando la stessa molecola svolge ruoli opposti in tessuti diversi, fornisce agli sviluppatori di farmaci bersagli più precisi e mette in guardia dove una terapia unica per tutti potrebbe ritorcersi contro. È importante che, includendo deliberatamente popolazioni diverse, lo studio contribuisca a garantire che eventuali futuri farmaci o punteggi di rischio derivati da queste intuizioni abbiano maggiori probabilità di funzionare in modo ampio e non solo per persone di discendenza europea.
Citazione: Bocher, O., Arruda, A.L., Yoshiji, S. et al. Unravelling the molecular mechanisms causal to type 2 diabetes across global populations and disease-relevant tissues. Nat Metab 8, 506–520 (2026). https://doi.org/10.1038/s42255-025-01444-1
Parole chiave: diabete di tipo 2, meccanismi genetici, genomica multi-ancestrale, espressione genica tessuto-specifica, inferenza causale