Clear Sky Science · it
Migliorare la previsione di kcat tramite un meccanismo di attenzione sensibile ai residui e rappresentazioni pre-allenate
Perché contano previsioni più rapide degli enzimi
Gli enzimi sono le piccole macchine che mantengono in funzione le cellule — e intere industrie. Accelerano le reazioni chimiche che alimentano il nostro metabolismo, producono farmaci e guidano processi produttivi più sostenibili. Un numero chiave che descrive la velocità di un enzima è il numero di turnover, o kcat. Misurare kcat in laboratorio è lento e costoso, quindi i ricercatori si rivolgono all’intelligenza artificiale per prevederlo a partire dalla sequenza e dalle informazioni sulla reazione. Questo lavoro presenta PMAK, un nuovo modello di IA che non solo predice kcat con maggiore accuratezza rispetto agli strumenti precedenti, ma aiuta anche a individuare quali parti di un enzima sono più importanti per la sua attività.
Dal lavoro di laboratorio alle previsioni intelligenti
Tradizionalmente, determinare kcat significa misurare con cura quanto rapidamente un enzima converte il substrato in prodotto in condizioni strettamente controllate, come temperatura e pH fissi. Farlo per migliaia di enzimi è impraticabile, il che limita la nostra capacità di modellare intere reti metaboliche o progettare nuovi biocatalizzatori. I primi metodi computazionali hanno cercato di colmare questa lacuna, ma molti si basavano su caratteristiche costruite a mano o su una visione semplificata dell’enzima e di un singolo substrato. Spesso funzionavano bene solo quando i nuovi enzimi erano molto simili a quelli già presenti nei dati di addestramento, mentre faticavano con enzimi davvero nuovi, reazioni inedite o mutanti ingegnerizzati.
Insegnare ai computer il “linguaggio” di enzimi e reazioni
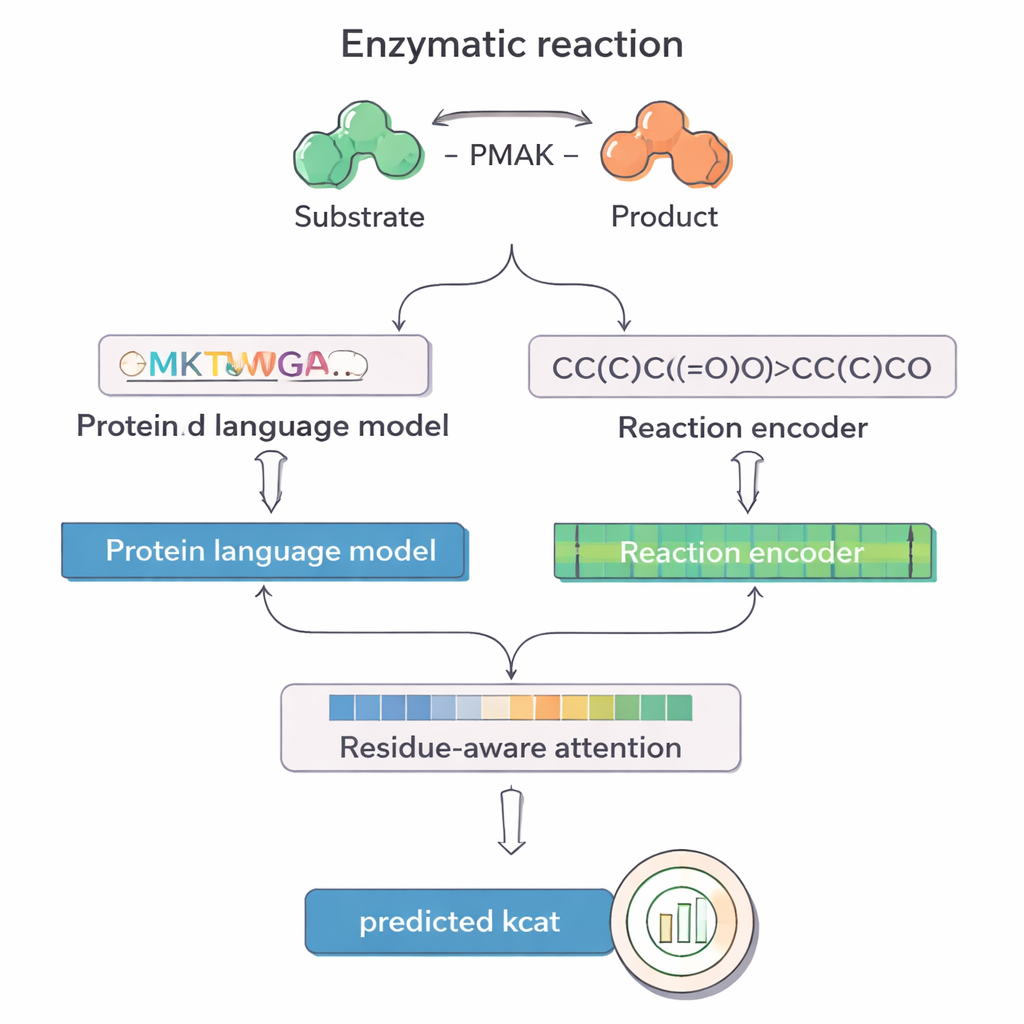
PMAK sfrutta i recenti progressi nei “modelli linguistici” originariamente sviluppati per il testo, ma riaddestrati su vaste raccolte di sequenze proteiche e reazioni chimiche. Un modello, chiamato ProT5, trasforma la sequenza amminoacidica di un enzima in una ricca rappresentazione numerica che cattura pattern appresi da milioni di proteine. Un altro modello, RXNFP, fa lo stesso per reazioni intere scritte come stringhe SMILES, che codificano tutti i reagenti e i prodotti. PMAK immette queste due rappresentazioni apprese in una rete neurale che allinea le loro dimensioni e permette al modello di considerare insieme l’enzima e il contesto completo della reazione, invece di trattarli separatamente.
Evidenziare i blocchi costitutivi più importanti
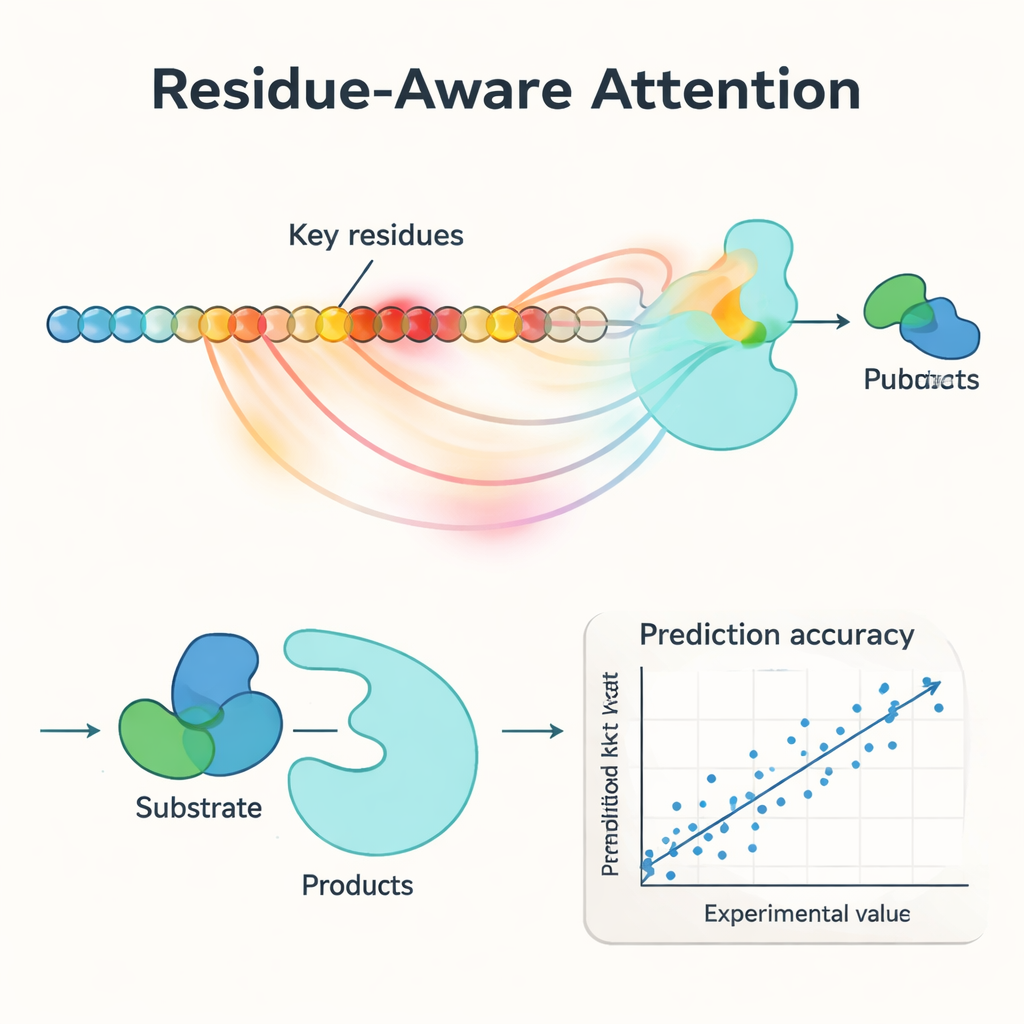
Un’innovazione centrale in PMAK è un meccanismo di “attenzione sensibile ai residui”. Invece di trattare ogni amminoacido di un enzima come ugualmente importante, il modello impara ad assegnare pesi più alti a residui specifici che contano maggiormente per la reazione in questione. Questi punteggi di attenzione agiscono come un proiettore sulla sequenza: quando i ricercatori li hanno confrontati con siti attivi e di legame noti derivati da strutture proteiche, hanno osservato che PMAK evidenziava in modo coerente residui funzionali molto più spesso di quanto ci si aspetterebbe per caso. Il modello ha funzionato bene anche quando i siti attivi venivano definiti in modo più ampio, includendo residui vicini nello spazio 3D, suggerendo che cattura segnali strutturali e chimici sottili rilevanti per la catalisi.
Buone prestazioni su enzimi nuovi, reazioni nuove e mutanti
Gli autori hanno testato rigorosamente PMAK su un set di dati curato di oltre 4.000 valori di kcat che coprono quasi 3.000 enzimi e 2.800 reazioni. In condizioni di “warm-start” — dove enzimi e reazioni simili compaiono sia nei set di addestramento sia nei test — PMAK ha eguagliato o superato i migliori modelli esistenti. Ancora più impressionante, nei test “cold-start” in cui l’enzima o la reazione nel set di test non era mai stata vista prima, PMAK ha sovraperformato una serie di metodi di punta. È rimasto utile anche per enzimi con bassa similarità di sequenza rispetto ai dati di addestramento e per reazioni che differivano notevolmente da quelle apprese. PMAK ha inoltre migliorato le previsioni in applicazioni realistiche, come stimare come le cellule allocano le limitate risorse proteiche e prevedere gli effetti delle mutazioni in dataset di ingegneria enzimatica.
Cosa significa per la biologia e la biotecnologia
Per i non specialisti, PMAK può essere visto come un assistente intelligente che impara da enormi “biblioteche” di proteine e reazioni per indovinare quanto velocemente un dato enzima lavorerà in una particolare reazione — e per spiegare quali amminoacidi guidano quel comportamento. Combinando maggiore accuratezza con intuizioni a livello di residuo, questo approccio può aiutare i ricercatori a progettare enzimi migliori, costruire modelli metabolici più affidabili ed esplorare come le mutazioni influenzano la funzione senza eseguire ogni esperimento in laboratorio. Man mano che modelli simili si estenderanno ad altri caratteri cinetici, potrebbero diventare strumenti chiave per progettare processi industriali più puliti, ottimizzare microrganismi per produzioni sostenibili e approfondire la comprensione di come le macchine molecolari della vita raggiungano la loro straordinaria velocità.
Citazione: Cai, Y., Ge, F., Zhang, C. et al. Enhancing kcat prediction through residue-aware attention mechanism and pre-trained representations. Commun Biol 9, 273 (2026). https://doi.org/10.1038/s42003-026-09551-9
Parole chiave: cinetica degli enzimi, apprendimento profondo, predizione di kcat, ingegneria delle proteine, modellizzazione metabolica