Clear Sky Science · it
Definizione della sicurezza operativa nei sistemi di intelligenza artificiale clinica
Perché l'IA sicura in medicina è importante
Gli ospedali stanno adottando rapidamente l'intelligenza artificiale per leggere le scansioni e segnalare le malattie, ma c'è una domanda a cui i normali punteggi di accuratezza non possono rispondere: quando è davvero sicuro lasciare che la macchina prenda la decisione? Questo articolo introduce un metodo pratico per decidere quando i medici possono fare affidamento con fiducia su un sistema di IA, quando dovrebbero ignorarlo e quando devono esaminare più da vicino il caso personalmente. L'obiettivo non è semplicemente costruire algoritmi più intelligenti, ma integrarli nell'assistenza quotidiana in modo che proteggano i pazienti, riducano i test non necessari e alleggeriscano il carico sui clinici anziché aumentarlo.
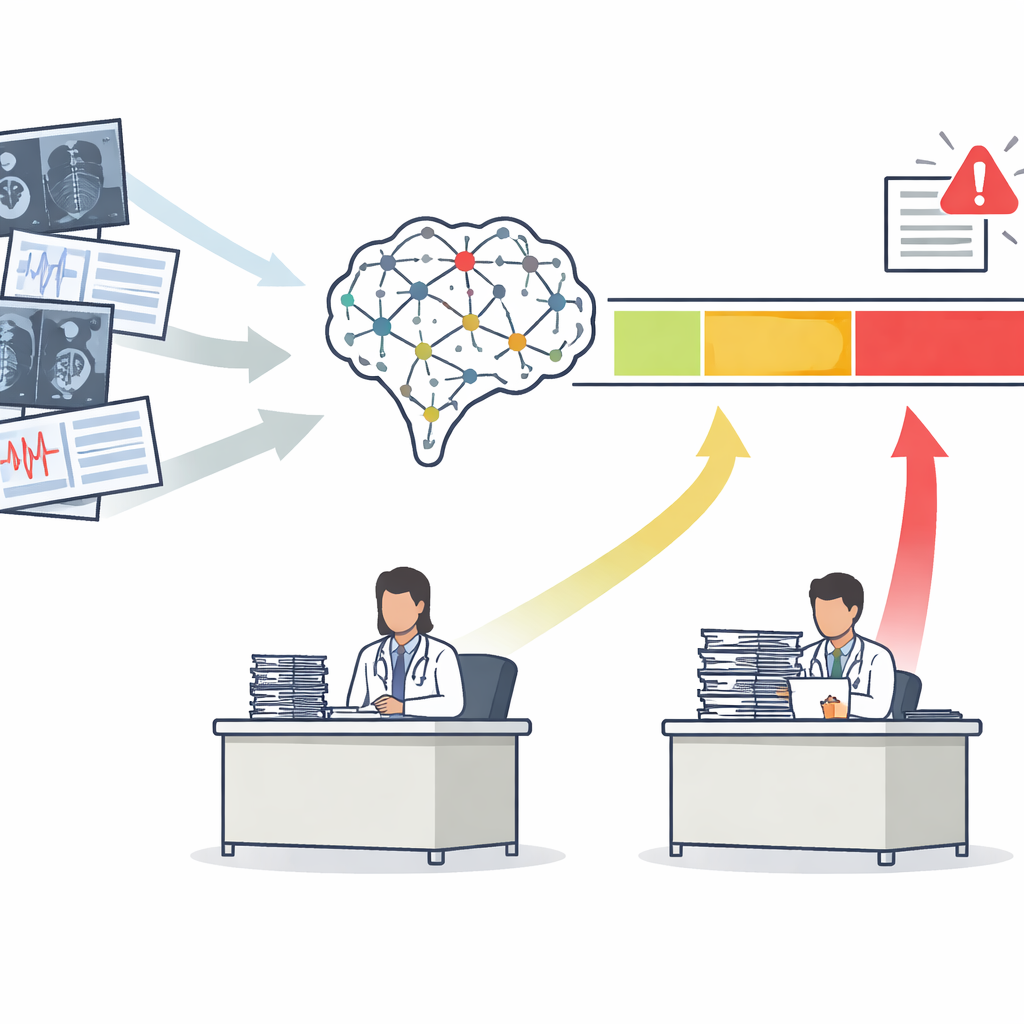
Da un unico punteggio a tre chiare zone d'azione
La maggior parte degli strumenti di IA medica produce un singolo punteggio di rischio, per esempio la probabilità che una mammografia evidenzi un tumore. Tradizionalmente, gli sviluppatori giudicano questi strumenti con una curva che riassume quanto bene distinguono, in media, pazienti malati da sani. Gli autori sostengono che questo non sia sufficiente. Propongono il framework Safety-Aware ROC (SA-ROC), che parte dagli stessi punteggi di rischio ma li rimappa in tre regioni pratiche. Una zona di "rule-in" ad alto punteggio contiene i pazienti i cui risultati sono sufficientemente affidabili da richiedere un'azione, come un follow-up urgente. Una zona di "rule-out" a basso punteggio contiene i pazienti i cui risultati sono sufficientemente affidabili da poter essere de-priorizzati in sicurezza. Tra di loro si trova una "zona grigia" di incertezza, dove l'IA non è abbastanza attendibile e un esperto umano deve riesaminare il caso.
Lasciare che i clinici fissino l'asticella della sicurezza
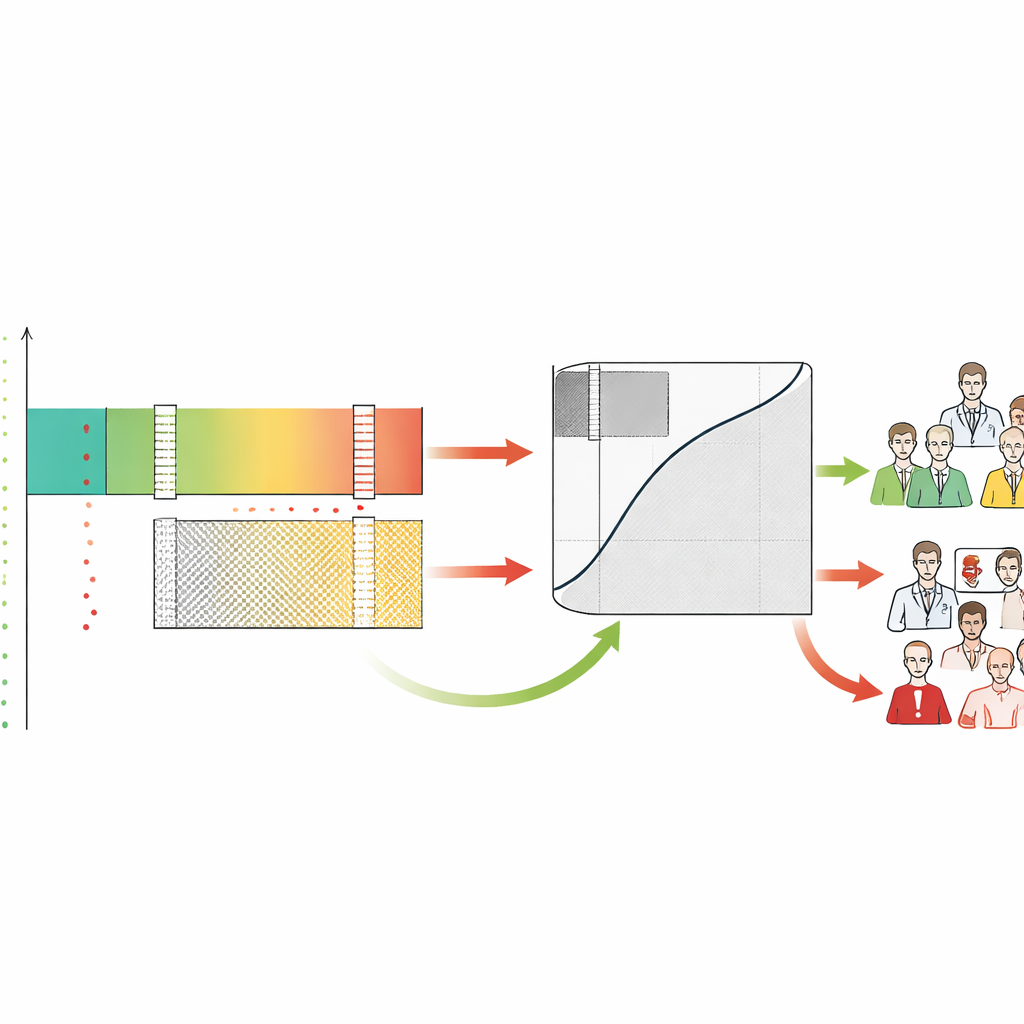
Fondamentalmente, SA-ROC consente a clinici e istituzioni di definire in anticipo i propri obiettivi di sicurezza. Scelgono quanto essere sicuri prima di intervenire su un risultato positivo (la probabilità minima accettabile che un reperto segnalato sia effettivamente anomalo) e quanto essere sicuri prima di allentare la vigilanza su un risultato negativo (la probabilità minima accettabile che un caso classificato come pulito sia veramente normale). Dati questi obiettivi, il framework analizza i punteggi del modello per trovare i confini esatti che li soddisfano. I punteggi sopra il confine superiore formano la zona sicura di rule-in, i punteggi sotto il confine inferiore formano la zona sicura di rule-out e tutto ciò che sta in mezzo diventa la zona grigia. Il framework poi quantifica quanti pazienti ricadono in ciascuna regione e quanto carico di lavoro incerto — casi rinviati agli esseri umani — l'IA lascia irrisolto.
Rivelare differenze nascoste tra IA simili
Gli autori dimostrano che due sistemi di IA con punteggi di accuratezza tradizionali quasi identici possono comportarsi in modo molto diverso se osservati attraverso questa lente della sicurezza. Nelle simulazioni, modelli con la stessa performance complessiva hanno prodotto dimensioni molto diverse delle zone di rule-in, rule-out e grigia a seconda di come erano distribuiti i loro punteggi. Uno potrebbe eccellere nel confermare la malattia con sicurezza, mentre un altro potrebbe eccellere nel liberare in sicurezza un gran numero di pazienti a basso rischio. In uno studio di caso reale su due strumenti approvati dalla U.S. Food and Drug Administration per lo screening del tumore al seno, il sistema con il punteggio di accuratezza standard più alto era in realtà peggiore per lo screening ad alta confidenza. All'impostazione di sicurezza più rigorosa — che non permetteva tumori mancati nel gruppo a basso rischio — il sistema considerato più debole ha rimosso in sicurezza quasi il doppio delle donne dalla coda dei radiologi. SA-ROC mette così in luce una sorta di "inversione di performance" che le metriche convenzionali nascondono.
Comprendere la tensione uomo–IA e il carico di lavoro
Etichettando ogni caso come rule-in, rule-out o grigio, il framework rivela anche come si comportano i medici in queste zone. Gli autori hanno riscontrato che i radiologi spesso richiamano casi che l'IA giudicava sicuramentee a basso rischio, generando molti falsi allarmi proprio nella regione in cui la macchina era più affidabile. Al contrario, sia gli esseri umani sia l'IA faticavano nella zona grigia, confermandola come l'area che richiede realmente attenzione esperta. SA-ROC cattura la dimensione di questa zona grigia in un unico numero, che rappresenta il costo dell'indecisione. Una zona grigia piccola significa più automazione sicura e meno carico di lavoro umano; una zona grigia ampia significa che molti casi richiedono ancora una revisione manuale accurata e che il sistema potrebbe aumentare il burnout invece di alleviarlo.
Trasformare le regole di sicurezza nella pratica quotidiana
Oltre alla misurazione, il framework è progettato come uno strumento di governance che trasforma le politiche in comportamenti concreti dell'IA. Gli ospedali possono usarlo in due modi. Primo, possono specificare direttamente requisiti di sicurezza o limiti sul numero di casi che sono disposti a inviare alla zona grigia e lasciare che il framework calcoli le soglie corrispondenti. Secondo, possono assegnare valori e penalità a diversi esiti — rilevare un cancro, mancarne uno, ordinare un test non necessario o deferire alla revisione umana — e far cercare al framework la politica che massimizza il beneficio complessivo. Queste strategie possono essere tarate per obiettivi molto diversi, come programmi di screening di massa, invii a specialisti o coorti di ricerca, tutte usando lo stesso modello di base.
Cosa significa questo per pazienti e clinici
In termini semplici, questo lavoro offre un modo per dire non solo "questa IA è accurata", ma "ecco esattamente quando e come può essere fidata in clinica". Suddividendo gli output dell'IA in regioni sicure, non sicure e incerte legate a promesse di sicurezza esplicite, SA-ROC aiuta i sistemi sanitari a decidere quando le macchine possono agire autonomamente e quando gli esseri umani devono rimanere saldamente al controllo. Sottolinea che i punteggi di accuratezza tradizionali possono essere fuorvianti e che la vera sicurezza dipende da come un modello si comporta negli estremi dove gli errori hanno il costo più alto. Se ampiamente adottato e convalidato in ambiti reali più estesi, questo framework potrebbe favorire un'automazione più affidabile, ridurre falsi allarmi e test non necessari e trasformare i casi più difficili per l'IA — la zona grigia — in una fonte focalizzata di apprendimento e miglioramento sia per gli algoritmi sia per la medicina stessa.
Citazione: Kim, YT., Kim, H., Bahl, M. et al. Defining operational safety in clinical artificial intelligence systems. npj Digit. Med. 9, 281 (2026). https://doi.org/10.1038/s41746-026-02450-7
Parole chiave: intelligenza artificiale clinica, sicurezza operativa, imaging medico, supporto alle decisioni, stratificazione del rischio