Clear Sky Science · it
Un modello di deep learning che integra dati strutturati e testo clinico per predire la recidiva di fibrillazione atriale
Perché questo è importante per le persone con battito irregolare
La fibrillazione atriale, un comune disturbo del ritmo cardiaco, spesso torna anche dopo che i pazienti sono stati sottoposti ad ablazione con catetere, una procedura invasiva volta a ripristinare un battito regolare. Molti pazienti e i loro medici si chiedono: chi è più a rischio di recidiva e chi può stare tranquillo? Questo studio mostra come l’intelligenza artificiale moderna possa esaminare sia i dati numerici sia le note dei medici nella cartella clinica per prevedere con maggiore precisione la probabilità che la fibrillazione atriale ricompaia, guidando potenzialmente il follow‑up e prevenendo procedure ripetute.
Un problema del ritmo cardiaco difficile e frequentemente recidivante
L’ablazione con catetere è ampiamente usata per trattare la fibrillazione atriale bruciando o congelando piccole aree all’interno del cuore che innescano o sostengono ritmi anomali. Tuttavia il 30–50% dei pazienti presenta un ritorno dei battiti irregolari entro un anno, a volte necessitando di un secondo intervento. I punteggi di rischio esistenti, basati per lo più su poche misure come le dimensioni delle cavità cardiache e il tipo di fibrillazione atriale, offrono solo un quadro parziale. Di solito ignorano ricchi dettagli su come è stata eseguita la procedura, su come appariva il cuore all’ecografia e sulle sfumature delle condizioni generali del paziente che rimangono sepolte nei referti testuali. Di conseguenza, i medici faticano ancora a identificare chi necessita davvero di monitoraggio più stretto o di trattamenti preventivi aggiuntivi.
Trasformare i dati ospedalieri di routine in uno strumento predittivo più intelligente
Ricercatori in Cina hanno raccolto informazioni da 2.508 pazienti sottoposti ad ablazione per fibrillazione atriale in cinque ospedali tra il 2015 e il 2024. Il paziente tipico aveva 65 anni e circa uno su cinque ha avuto una recidiva di ritmo anomalo durante un follow‑up mediano di quasi tre anni. Per ciascuna persona il team ha raccolto dati strutturati — come età, pressione arteriosa, risultati degli esami del sangue, dimensioni delle cavità cardiache e punteggi di rischio esistenti — oltre a testi non strutturati, inclusi i sommari del monitoraggio cardiaco di 24 ore, i referti ecocardiografici e le note dettagliate della procedura redatte dagli elettrofisiologi. Hanno poi costruito un modello di deep learning a doppio ramo: un ramo ha elaborato i dati numerici e categorici, mentre l’altro ha usato grandi modelli linguistici per trasformare i referti in testo libero in caratteristiche quantitative che potessero essere combinate con i numeri.
Come i modelli linguistici avanzati leggono le note dei medici
Il ramo testuale del sistema si basava su quattro moderni grandi modelli linguistici, originariamente addestrati su vaste collezioni di testi e poi adattati al linguaggio medico. Questi modelli sono stati messa a punto su referti ospedalieri de‑identificati in modo da comprendere meglio termini e schemi specialistici. Lo studio ha confrontato diversi modelli linguistici per vedere quali producevano caratteristiche testuali più predittive della recidiva. Il modello che si è distinto è stato MedGemma, specificamente ottimizzato per contenuti medici. Quando le sue caratteristiche testuali sono state fuse con il ramo dei dati strutturati, il modello risultante, denominato “MedGemma‑Fusion”, ha mostrato un’accuratezza notevole, con aree sotto la curva ROC superiori a 0,90 nelle fasi di addestramento, validazione e nei test indipendenti tra ospedali. Ciò significa che il modello riusciva a distinguere in modo affidabile i pazienti che sarebbero rimasti liberi da aritmia da quelli che non lo sarebbero stati.
Dare uno sguardo dentro la "scatola nera" dell’IA
Per capire cosa il modello stesse effettivamente utilizzando per fare le predizioni, i ricercatori hanno applicato strumenti di interpretabilità che stimano l’influenza di ciascun input. Nei dati strutturati, fattori clinici noti come la durata della fibrillazione atriale nel paziente, le dimensioni dell’atrio sinistro e se il ritmo fosse intermittente o persistente pesavano di più. Dal lato testuale, concetti chiave legati alle procedure di ablazione — come descrizioni delle vene polmonari e dei potenziali elettrici — sono emersi in cima, riflettendo passaggi centrali per il successo del trattamento. Anche termini relativi al movimento cardiaco nei referti ecografici hanno avuto importanza, coerente con l’idea che alterazioni nel movimento degli atri segnalino danni di lunga data. Al contrario, i sommari del monitoraggio cardiaco di 24 ore hanno contribuito relativamente poco, probabilmente perché molti pazienti con fibrillazione atriale intermittente mostrano ritmi normali durante finestre di monitoraggio brevi.
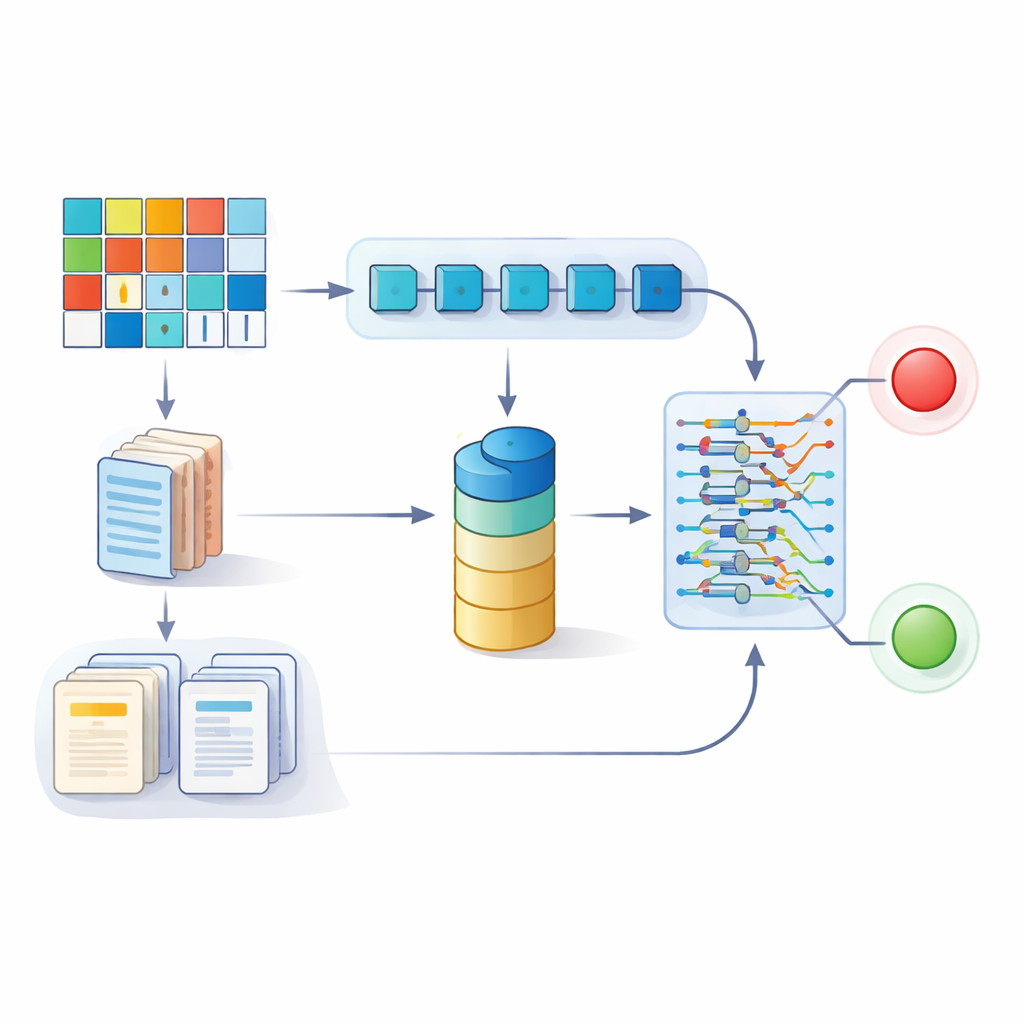
Dal modello di ricerca alle decisioni al letto del paziente
Oltre all’accuratezza pura, il team ha valutato quanto bene il loro strumento separasse le persone in gruppi ad alto e basso rischio tramite analisi di sopravvivenza. I pazienti classificati ad alto rischio da MedGemma‑Fusion mostravano tassi di recidiva chiaramente più elevati nel tempo. L’analisi della curva decisionale ha suggerito che, su molte soglie ragionevoli, utilizzare il modello per guidare le cure offrirebbe un beneficio netto maggiore rispetto all’affidarsi ai punteggi tradizionali o a singole misure. Tuttavia, gli autori sottolineano importanti avvertenze: lo studio è retrospettivo, le dimensioni del campione — pur ampie per un singolo progetto — sono modeste per il deep learning, e gli stili di refertazione variavano tra gli ospedali. Versioni future dei grandi modelli linguistici e test più estesi in altri sistemi sanitari saranno necessari prima che tali strumenti diventino di routine. Nonostante ciò, questo lavoro illustra come combinare i numeri di uso quotidiano nella cartella con la sfumatura nascosta nei referti narrativi possa affinare le predizioni e, in futuro, aiutare a personalizzare il follow‑up e l’intensità del trattamento per le persone con fibrillazione atriale.
Citazione: Jia, S., Yin, Y., Guan, Y. et al. A deep learning model integrating structured data and clinical text for predicting atrial fibrillation recurrence. npj Digit. Med. 9, 253 (2026). https://doi.org/10.1038/s41746-026-02436-5
Parole chiave: fibrillazione atriale, ablazione con catetere, deep learning, estrazione di testo clinico, predizione del rischio