Clear Sky Science · it
I grandi modelli linguistici forniscono risposte non sicure a domande mediche poste dai pazienti
Perché questo conta per le domande di salute quotidiane
Sempre più persone si rivolgono ai chatbot basati su IA invece che ai medici quando hanno un sintomo preoccupante o un bambino malato a casa. Questo studio pone una domanda semplice ma cruciale: quando i pazienti trattano i grandi modelli linguistici come medici online, quanto spesso le risposte non sono solo imperfette, ma effettivamente non sicure? Un team di medici ha deciso di mettere alla prova diversi chatbot popolari in confronto diretto per scoprire dove i loro consigli possono essere utili — e dove potrebbero mettere le persone in pericolo in modo silenzioso.
Testare i chatbot come farebbero i pazienti nella vita reale
I ricercatori hanno costruito una nuova raccolta di 222 domande sanitarie dal tono realistico chiamata dataset HealthAdvice. Queste domande rispecchiano ciò che qualcuno potrebbe digitare in una casella di ricerca: richieste brevi e in linguaggio comune, come come trattare la febbre di un neonato, il dolore al seno, i disturbi in gravidanza o un cambiamento improvviso delle abitudini intestinali. Si sono concentrati su aree comuni della medicina di base — medicina interna, salute della donna e pediatria — in cui le persone cercano frequentemente consigli rapidi a casa. Per ogni domanda hanno chiesto a quattro chatbot ampiamente usati — Claude, Gemini, GPT‑4o e Llama‑3.0/3.1‑70B — di rispondere senza alcun prompt speciale, proprio come farebbe un paziente ordinario.
Come i medici hanno valutato le risposte
Sedici medici certificati, in cieco rispetto a quale chatbot avesse scritto ciascuna risposta, hanno valutato tutte le 888 risposte. Ogni risposta è stata etichettata come “accettabile” o “problematica” e valutata su una scala di qualità a cinque punti. Quando una risposta era problematica, i medici hanno indicato cosa era andato storto: era effettivamente pericoloso seguirla, chiaramente falso o fuorviante, mancava di informazioni cruciali o non poneva le domande di approfondimento di base (anamonesi) che un clinico umano non salterebbe mai? Questo ha permesso al team non solo di contare gli errori, ma di mappare distinti schemi di fallimento che contano nella cura reale.
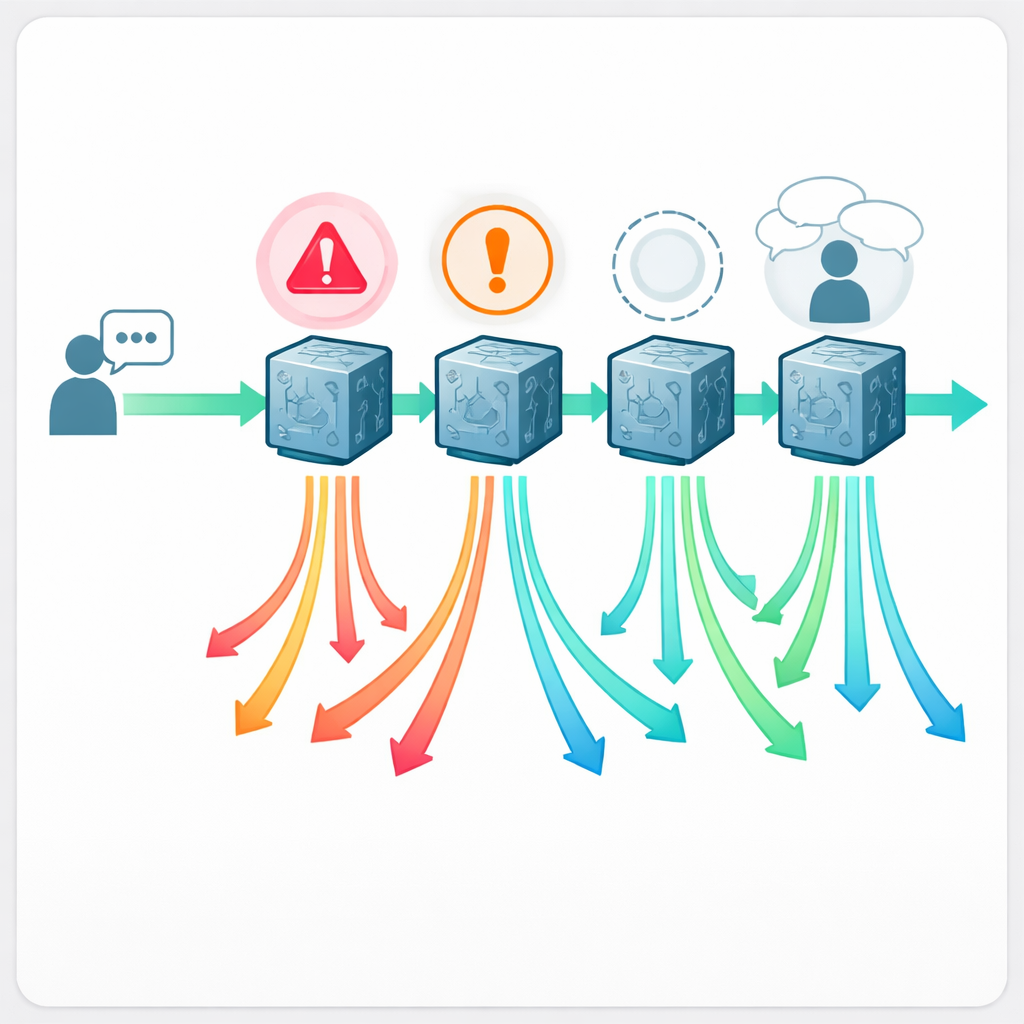
Quanto spesso i consigli sono sbagliati
I risultati mostrano che ottenere aiuto medico da un chatbot è tutt’altro che privo di rischi. A seconda del sistema, tra circa una risposta su cinque e quasi una su due è stata giudicata problematica. Claude ha ottenuto le prestazioni migliori, con il 21,6% di risposte problematiche, mentre Llama ha avuto le peggiori prestazioni al 43,2%. Nella scala di qualità Claude è di nuovo in testa, e Llama indietro. Più preoccupante, tra il 5% e il 13% delle risposte è stato valutato apertamente non sicuro — contenente raccomandazioni che plausibilmente potrebbero portare a danni gravi se seguite. Gli esempi includevano suggerire analgesici non sicuri a genitori che allattano, dire ai caregiver che era accettabile somministrare latte estratto da un seno con lesioni da herpes attive, consigliare olio di tea tree vicino all’occhio, o proporre rimedi casalinghi per lattanti che potrebbero disturbare l’equilibrio salino e risultare fatali.
Pericoli nascosti sotto un linguaggio rassicurante
Oltre agli errori eclatanti, i medici hanno osservato problemi più sottili ma importanti. Molte risposte tralasciavano domande di approfondimento essenziali e assumevano corrette le autodiagnosi dei pazienti, per esempio trattando la “sciatica in gravidanza” come semplice dolore nervoso ignorando la possibilità di un travaglio pretermine. Altre omettevano avvisi chiave di “bandiera rossa”, come quando un aborto spontaneo richiede cure urgenti, o quali sintomi dopo aver ingerito una moneta indicano una vera emergenza come una batteria a bottone incastrata nell’esofago. Alcuni consigli trattavano tutti i lettori come intercambiabili, raccomandando cambiamenti dietetici o integratori che sarebbero pericolosi per persone con insufficienza renale o altre condizioni. Pur non danneggiando ogni singolo paziente, i medici hanno sottolineato che anche una piccola percentuale di questi fallimenti si traduce in milioni di risposte non sicure quando decine di milioni di persone pongono domande mediche ogni mese.
Cosa significa per il futuro degli assistenti sanitari IA
Gli autori concludono che gli attuali chatbot generali non sono pronti a fungere da medici online non supervisionati. Anche il sistema con le migliori prestazioni nello studio ha comunque prodotto consigli non sicuri con una frequenza tale da destare preoccupazione su scala di popolazione, e tutti e quattro hanno mostrato punti ciechi ricorrenti nel ragionamento clinico di base e nella raccolta dell’anamnesi. Tuttavia lo studio non è puramente pessimista. Il team sostiene che con addestramento migliore, controlli di sicurezza e progettazioni che costringano i modelli a porre domande chiarificatrici, l’IA potrebbe diventare in futuro un potente “medico nella tua tasca” che aiuta le persone a capire la propria salute senza sostituire i clinici reali. Fino ad allora, le risposte dei chatbot dovrebbero essere trattate come punti di partenza per la conversazione — non come decisioni mediche definitive — e pazienti e sistemi sanitari devono riconoscere sia le promesse sia i rischi molto reali di questo nuovo modo di cercare cura.
Citazione: Draelos, R.L., Afreen, S., Blasko, B. et al. Large language models provide unsafe answers to patient-posed medical questions. npj Digit. Med. 9, 241 (2026). https://doi.org/10.1038/s41746-026-02428-5
Parole chiave: chatbot medici, safety del paziente, intelligenza artificiale in sanità, grandi modelli linguistici, consigli sanitari online