Clear Sky Science · it
Regolazione visiva guidata dall’anatomia per la comprensione cross-modale del cancro al seno
Screening più intelligenti per un tumore comune
Il cancro al seno è una delle principali cause di morte per tumore nelle donne e i medici si affidano sempre più a programmi informatici per interpretare immagini mediche complesse. Ma mammografie, ecografie e risonanze magnetiche mostrano il seno in modi molto diversi, rendendo difficile per i sistemi di intelligenza artificiale mantenere affidabilità tra apparecchiature e ospedali diversi. Questo studio presenta un nuovo approccio di IA che «pensa» all’anatomia sottostante del seno invece di limitarsi ai pattern di luminosità in ogni immagine, portando a una rilevazione delle aree sospette più accurata e più coerente.
Perché le diverse scansioni confondono i computer
Mammografia, ecografia e risonanza magnetica utilizzano fisiche differenti per osservare l’interno del seno. Un cancro che appare come una macchia brillante in un’ecografia potrebbe mostrarsi come un’ombra sottile in una mammografia o come una chiazza luminosa in una risonanza. Molti sistemi di IA moderni, inclusi potenti vision transformer e modelli vision–language, imparano principalmente dall’aspetto generale dell’immagine. Spesso perdono dettagli minimi ma importanti, come microcalcificazioni o margini irregolari, e le loro prestazioni possono calare bruscamente quando vengono trasferiti da un tipo di scanner o da un ospedale a un altro. Questo divario tra condizioni di addestramento e cliniche reali ha limitato la fiducia che i medici possono riporre in tali strumenti.
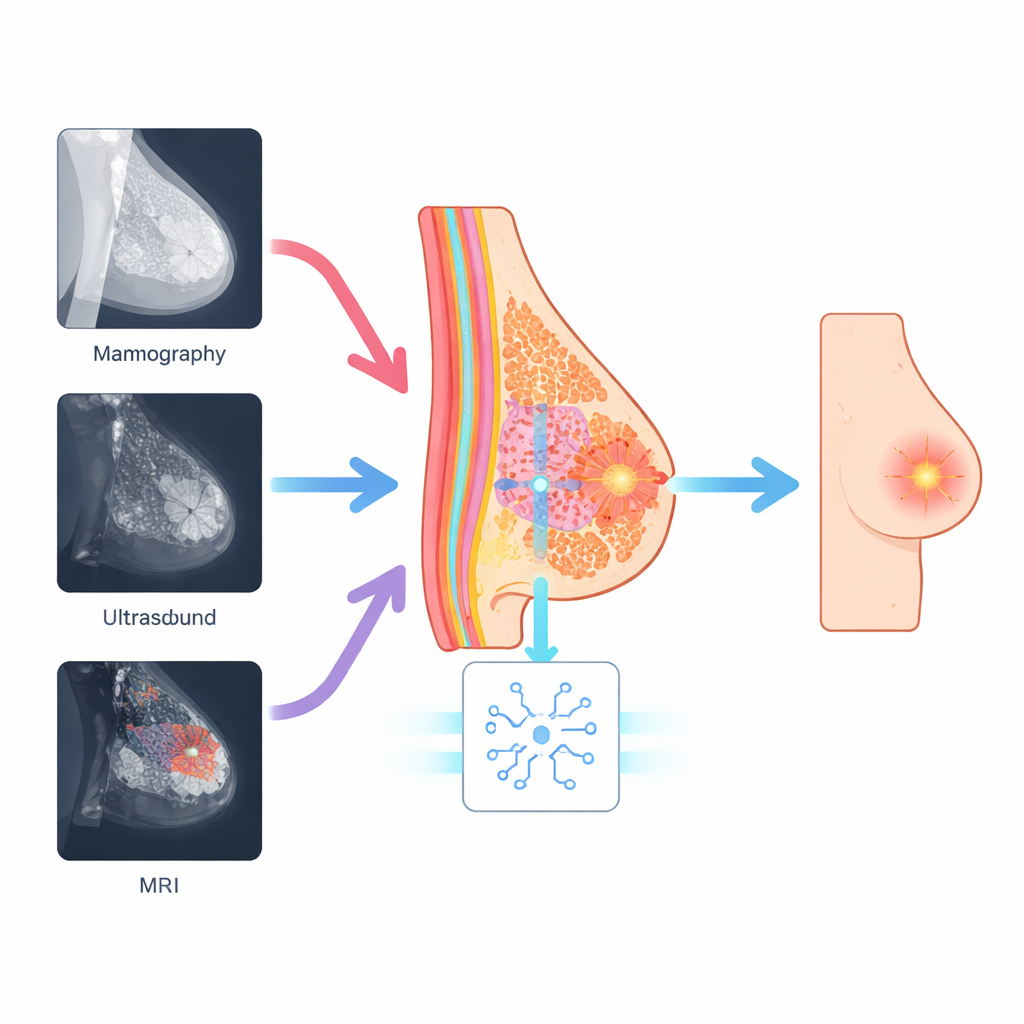
Usare il seno stesso come guida
I ricercatori sostengono che, sebbene le immagini appaiano diverse, la biologia reale del seno non cambia tra le scansioni. Ogni immagine contiene comunque tessuto ghiandolare, grasso e strutture duttali organizzate in uno schema riconoscibile. Il loro metodo, chiamato Anatomy-Guided Visual Prompt Tuning (A-VPT), incorpora questa mappa anatomica di base direttamente nel modello di IA. Invece di aggiornare milioni di pesi interni, il sistema aggiunge un piccolo insieme di segnali extra, o «prompt», che indicano alla rete quali regioni tissutali sta osservando. Questi prompt sono generati da mappe anatomiche grossolane o da indizi tissutali appresi e vengono poi iniettati strato dopo strato in un transformer pre-addestrato e congelato. In pratica, il modello viene continuamente ricordato di dove si trovano dotti, ghiandole e grasso, così da valutare le aree sospette nel giusto contesto.
Insegnare a un sistema a parlare molti linguaggi di imaging
Per rendere il modello operativo su diversi tipi di imaging, il team ha progettato uno schema di addestramento che costringe l’IA a trattare tessuti simili nello stesso modo, indipendentemente da come sono stati acquisiti. Allineano le impronte interne delle regioni adipose, ghiandolari e duttali prese da mammografia, ecografia e risonanza, avvicinandole in uno spazio condiviso. Dove sono disponibili referti testuali, il sistema collega anche questi pattern tissutali a brevi frasi descrittive, legando le caratteristiche visive al linguaggio medico. Durante l’elaborazione, moduli di interazione specializzati permettono ai prompt anatomici e alle caratteristiche dell’immagine di scambiarsi informazioni in entrambe le direzioni, con uno stadio di gating che controlla quanto fortemente l’anatomia influenzi ogni strato. Questa combinazione aiuta il modello a concentrarsi sulle strutture rilevanti mantenendo stabilità ed efficienza.
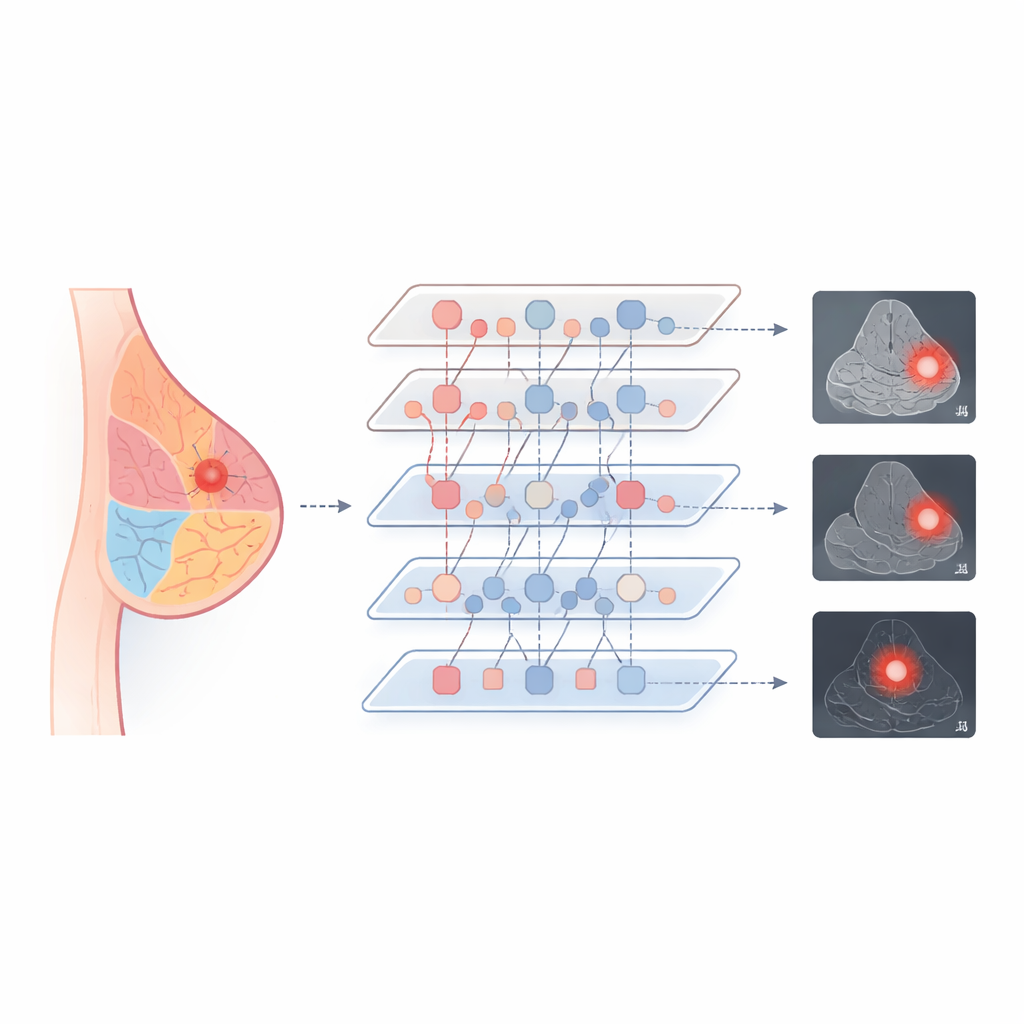
Migliore accuratezza con un tocco più leggero
Gli autori hanno testato A-VPT su tre ben note raccolte di immagini del seno che coprono tutte e tre le modalità. Rispetto alle reti profonde tradizionali e a diversi modi popolari di fine-tuning di grandi modelli, il loro metodo ha ottenuto i punteggi più alti sia nella classificazione delle lesioni come benigne o maligne sia nel delinearne i contorni. Ha performato particolarmente bene quando gli è stato chiesto di usare conoscenze da un tipo di scansione per interpretarne un’altra — per esempio, addestrando su mammografie e valutando poi su ecografie — dove i metodi più vecchi spesso fallivano. Notevolmente, A-VPT ha raggiunto questi risultati aggiornando meno del 2% dei parametri del modello, riducendo i requisiti computazionali e rendendo più semplice il suo dispiegamento negli ospedali. Le visualizzazioni di dove il modello «guardava» hanno mostrato che si concentrava su regioni ghiandolari e peri-tumorali realistiche, suggerendo che le sue decisioni corrispondono al ragionamento dei radiologi.
Cosa significa per pazienti e cliniche
In termini concreti, questo lavoro dimostra che insegnare ai sistemi di IA l’anatomia di base può renderli sia più intelligenti sia più interpretabili. Ancorando il proprio ragionamento alla struttura reale del seno, A-VPT è più abile nel riconoscere e delineare i tumori attraverso diverse modalità di imaging, con meno aggiustamenti e un comportamento più trasparente. Se validata ulteriormente, questa strategia potrebbe supportare uno screening e una diagnosi più coerenti in contesti diversi, dai grandi centri medici alle cliniche più piccole, e potrebbe essere estesa ad altri organi come polmone o fegato. In ultima analisi, un’IA consapevole dell’anatomia potrebbe diventare un partner chiave per una diagnosi del cancro più precoce e affidabile.
Citazione: Zhao, S., Meng, Q., He, Y. et al. Anatomy-guided visual prompt tuning for cross-modal breast cancer understanding. npj Digit. Med. 9, 240 (2026). https://doi.org/10.1038/s41746-026-02417-8
Parole chiave: imaging del cancro al seno, IA medica, vision transformer, apprendimento cross-modale, prompt guidati dall’anatomia