Clear Sky Science · it
Un trasformatore debolmente supervisionato per la diagnosi di malattie rare e il sottofenotipaggio dagli EHR con casi di studio polmonari
Perché trovare le malattie rare più rapidamente conta
Per le famiglie che convivono con malattie rare, ottenere un nome per ciò che non va può richiedere anni. I sintomi sono spesso vaghi, i medici possono vedere solo pochi casi simili nella vita e i test esistenti non danno sempre risposte chiare. Questo studio esplora un nuovo approccio che sfrutta le tracce digitali lasciate nelle cartelle cliniche elettroniche per individuare prima due condizioni polmonari difficili da diagnosticare e per classificare i pazienti in gruppi che potrebbero affrontare futuri molto diversi.
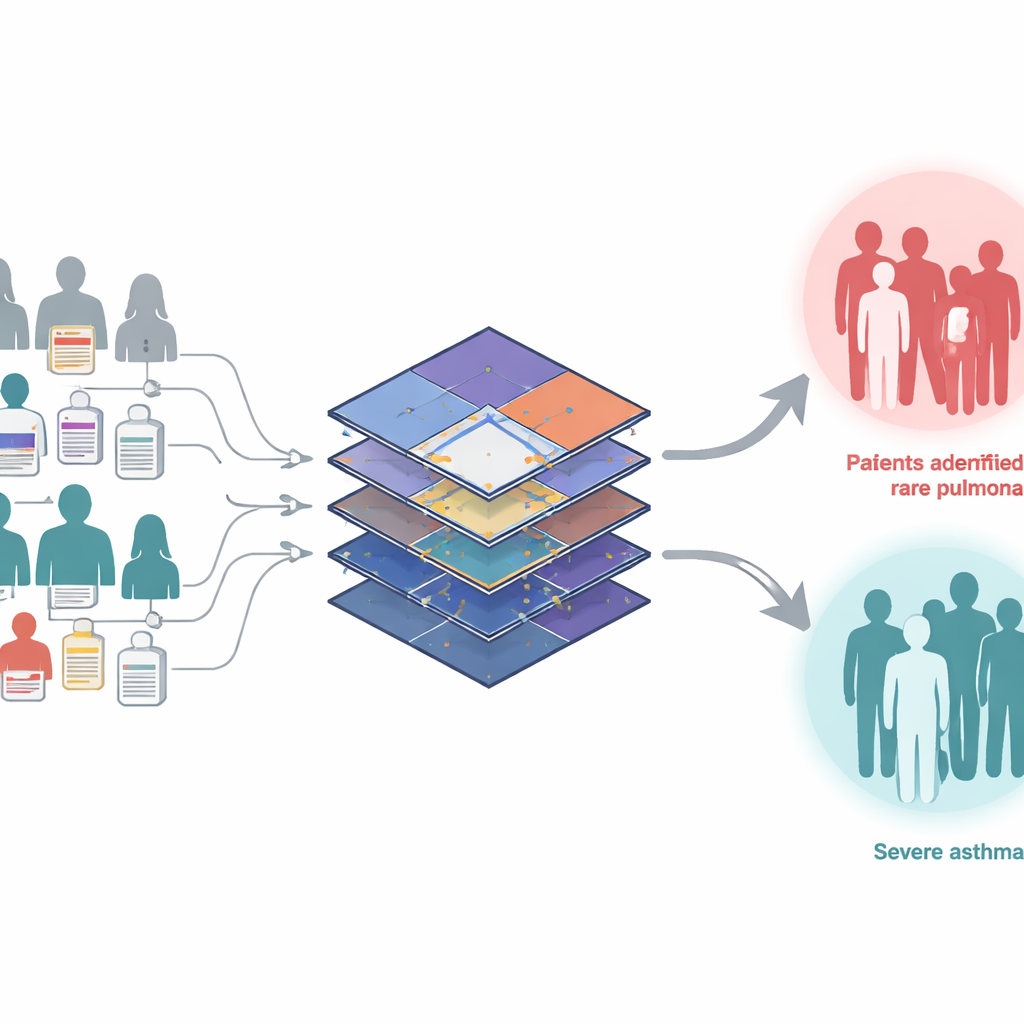
La lunga strada verso una diagnosi rara
Le malattie rare sono rare singolarmente, ma insieme colpiscono centinaia di milioni di persone nel mondo. Molte esordiscono nell’infanzia e possono mettere a rischio la vita se non vengono riconosciute. L’articolo si concentra sulle malattie polmonari rare, dove lamentele comuni come respiro corto o sibili possono essere facilmente scambiate per asma o altri problemi diffusi. Di conseguenza, i bambini con condizioni come l’ipertensione polmonare o forme gravi di asma possono visitare molti specialisti e aspettare anni prima di ricevere la diagnosi corretta, perdendo tempo prezioso in cui un trattamento precoce potrebbe modificare l’evoluzione della malattia.
Trasformare cartelle cliniche disordinate in indizi
Gli ospedali moderni archiviano enormi quantità di informazioni nelle cartelle cliniche elettroniche, dai codici di diagnosi e dalle prescrizioni agli esami di laboratorio e alle note dei medici. Nascosti in questi dati ci sono schemi che possono suggerire una malattia rara molto prima che venga formalmente identificata. Ma c’è un problema: solo una piccola frazione di pazienti è stata accuratamente revisionata da esperti, quindi le etichette di alta qualità che indicano chi ha realmente una malattia sono scarse. La maggior parte dei record contiene solo segnali approssimativi e “rumorosi” — codici che possono riflettere pratiche di fatturazione, ipotesi provvisorie o etichette obsolete. I modelli informatici tradizionali faticano in questo contesto perché sono pensati per apprendere da grandi raccolte di esempi puliti e affidabili.
Un nuovo modo di apprendere da dati imperfetti
Gli autori introducono WEST, un «trasformatore debolmente supervisionato» progettato per apprendere da questa combinazione di poche etichette accurate e molte incerte. Il sistema parte da due gruppi di pazienti del Boston Children’s Hospital che potrebbero avere ipertensione polmonare o asma grave, identificati tramite codici di screening ampi. All’interno di ciascun gruppo, un piccolo sottoinsieme è stato confermato da specialisti, mentre il resto riceve punteggi probabilistici da strumenti precedenti basati su regole. WEST utilizza un trasformatore — un’architettura avanzata per trovare schemi originariamente sviluppata per il linguaggio — per trasformare l’intera storia clinica di ogni bambino in un ritratto numerico compatto. Crucialmente, non tratta le etichette approssimative come verità fisse: dopo ogni ciclo di addestramento, il modello aggiorna le proprie stime di chi è più probabilmente malato e reinserisce quelle probabilità affinate nel ciclo successivo, ripulendo gradualmente il segnale.
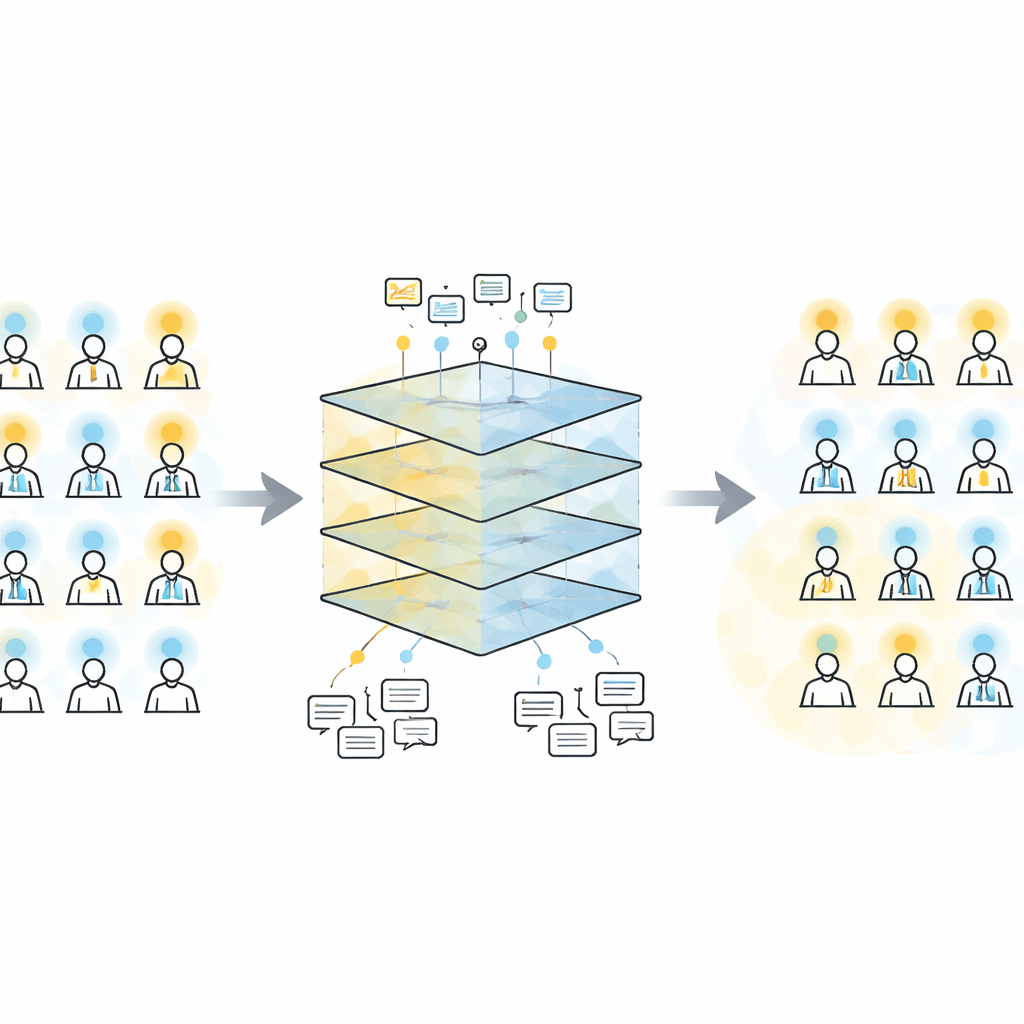
Cosa ha scoperto il modello nelle malattie polmonari
Quando è stato testato su pazienti tenuti fuori dal training e validati da esperti, WEST è risultato più accurato di diverse alternative, incluse regole semplici basate sul conteggio dei codici, alberi a gradient boosting e trasformatori che o ignoravano le etichette rumorose o le accettavano così come erano. Ha richiesto sorprendentemente pochi casi di riferimento di alta qualità per ottenere buone prestazioni — circa 100 pazienti accuratamente revisionati sono stati sufficienti per eguagliare o superare altri approcci. Oltre a identificare chi probabilmente aveva ciascuna condizione, le rappresentazioni interne del modello hanno raggruppato naturalmente i bambini in cluster clinicamente significativi. Per l’ipertensione polmonare, WEST ha separato i pazienti in un gruppo a progressione lenta e uno a progressione rapida, che hanno mostrato andamenti di sopravvivenza chiaramente differenti a cinque anni. Per l’asma grave, ha diviso i pazienti in quelli con riacutizzazioni frequenti e pericolose e quelli con attacchi relativamente meno numerosi, rispecchiando differenze in ricoveri, episodi di ipossia e insufficienza respiratoria.
Come questo potrebbe cambiare l’assistenza ai pazienti
Per un non specialista, il messaggio chiave è che WEST impara a “vedere” schemi complessi di malattia nei dati ospedalieri di routine senza fare affidamento su enormi dataset perfettamente etichettati. Riciclando in modo intelligente segnali imperfetti e una piccola quantità di input di esperti, può segnalare i casi probabilmente affetti da malattie rare con maggiore accuratezza e rivelare sottogruppi nascosti che affrontano rischi diversi. A lungo termine, sistemi come WEST potrebbero contribuire a ridurre l’odissea diagnostica per i bambini con malattie polmonari rare, indirizzare i medici verso un rinvio specialistico più precoce e supportare piani di monitoraggio e trattamento più personalizzati in base a come è probabile che la malattia del paziente si evolva.
Citazione: Greco, K.F., Yang, Z., Li, M. et al. A weakly supervised transformer for rare disease diagnosis and subphenotyping from EHRs with pulmonary case studies. npj Digit. Med. 9, 211 (2026). https://doi.org/10.1038/s41746-026-02406-x
Parole chiave: diagnosi di malattie rare, cartelle cliniche elettroniche, apprendimento automatico in medicina, ipertensione polmonare, asma grave