Clear Sky Science · it
Modello di base video self-supervised su larga scala per la chirurgia intelligente
Un aiuto più intelligente in sala operatoria
I chirurghi moderni fanno sempre più affidamento su telecamere e computer per orientare il proprio lavoro, ma l’intelligenza artificiale odierna fatica ancora a comprendere pienamente ciò che accade durante un’operazione. Questo articolo presenta un nuovo metodo per addestrare l’IA su migliaia di video chirurgici in modo che possa seguire meglio le fasi di una procedura, riconoscere strumenti e tessuti e valutare quanto l’intervento stia procedendo in modo sicuro e competente. Sul lungo periodo, questo tipo di tecnologia potrebbe supportare i chirurghi in tempo reale, migliorare la formazione e contribuire a rendere la chirurgia più sicura per i pazienti.
Perché è difficile insegnare la chirurgia alle macchine
Insegnare ai computer a comprendere la chirurgia non è semplice come fornire qualche immagine etichettata. Ogni procedura comporta telecamere in movimento, punti di vista che cambiano, fumo, sangue e mani e strumenti che si sovrappongono continuamente. A ciò si aggiungono migliaia di tipi diversi di interventi, molti dei quali rari. Etichettare con cura i video fotogramma per fotogramma richiede tempo di esperti, risorsa scarsa, e diventa rapidamente troppo costoso. I sistemi di IA precedenti hanno cercato di alleggerire questo onere con stratagemmi che apprendono da immagini non etichettate, ma per lo più consideravano fotogrammi isolati e solo in seguito hanno tentato di aggiungere una dimensione temporale. Di conseguenza, spesso hanno perso la narrazione in divenire di un’operazione: cosa è successo prima, cosa sta succedendo ora e cosa è probabile che accada dopo.
Apprendere direttamente dai filmati chirurgici
Gli autori sostengono che un’IA destinata ad assistere in chirurgia debba essere addestrata su video piuttosto che su immagini isolate. Per farlo, hanno assemblato una delle più grandi raccolte di video endoscopici a oggi disponibili: 3.650 registrazioni per un totale di 3,55 milioni di fotogrammi, tratte da dataset di ricerca pubblici e da un’ampia raccolta di filmati chirurgici online. Questi video coprono più di 20 tipi di procedure e oltre 10 regioni anatomiche, dalla colecistectomia alla chirurgia epatica e agli interventi ginecologici. Questa varietà consente all’IA di osservare molteplici varianti reali di una procedura, inclusi diversi ospedali, strumenti e stili di ripresa.
Un nuovo progetto di apprendimento focalizzato sui video
Sfruttando questo scrigno di dati, il team ha progettato SurgVISTA, un “modello di base” specificamente tarato per i video chirurgici. Invece di cercare di etichettare ogni fotogramma, SurgVISTA apprende riempiendo ciò che manca. Durante l’addestramento, parti di ogni clip video vengono nascoste e il modello deve ricostruire le regioni mancanti. Questo lo costringe a prestare attenzione a come tessuti, strumenti e movimenti cambiano nel tempo. Allo stesso tempo, un secondo ramo del sistema viene addestrato ad allinearsi ai segnali visivi dettagliati catturati da un robusto modello esperto basato su immagini che già conosce molto sulle scene chirurgiche. Questa combinazione aiuta SurgVISTA a cogliere sia i dettagli fini all’interno di ogni fotogramma sia il flusso più ampio dell’intera operazione, il tutto in un’unica rete unificata.
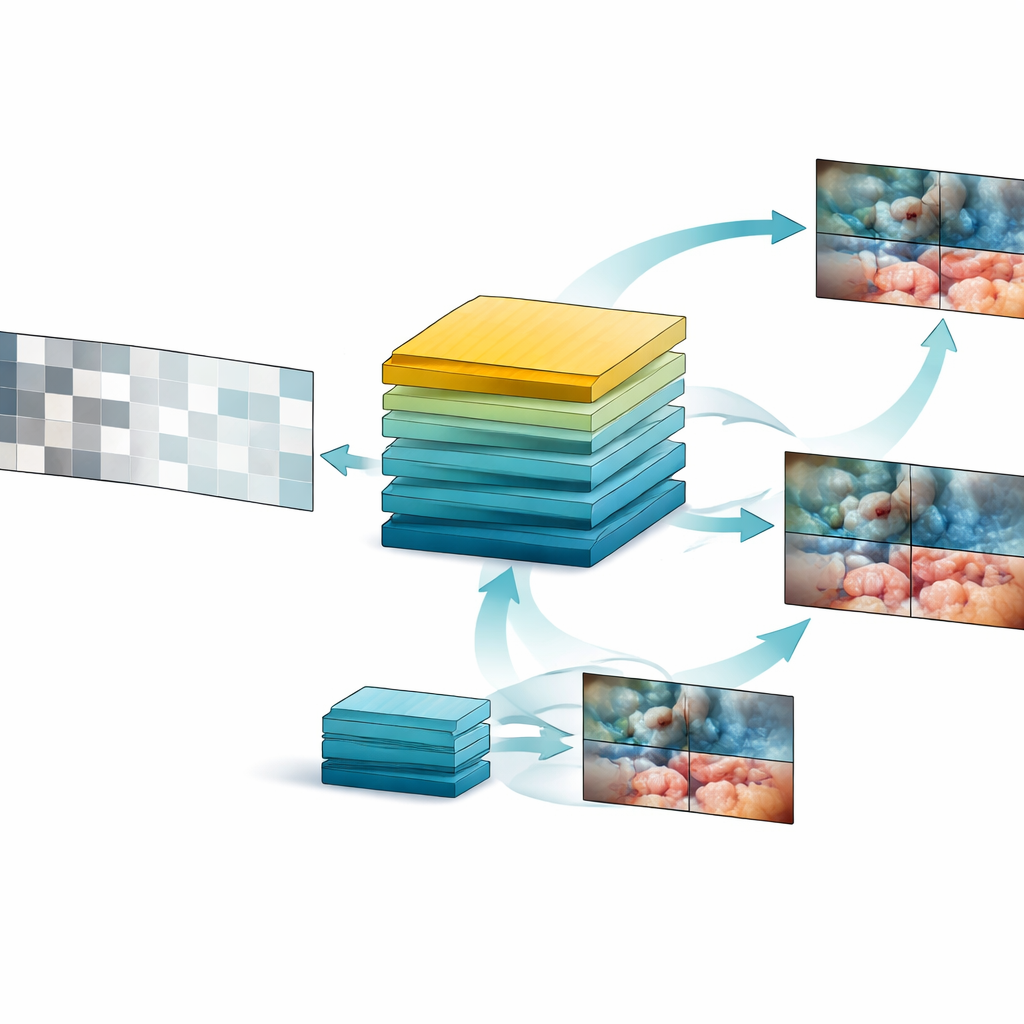
Mettere il modello alla prova
Per verificare se questo approccio offre davvero vantaggi, gli autori hanno testato SurgVISTA su 13 dataset diversi riguardanti sei tipi di chirurgia e quattro compiti pratici. Questi compiti includevano il riconoscimento della fase in corso di un’operazione, l’identificazione di azioni chirurgiche specifiche, la cattura della relazione tripartita tra strumento, azione e tessuto bersaglio e la valutazione di quanto i passaggi chiave siano stati eseguiti in sicurezza. Su tutta la linea, SurgVISTA ha superato i modelli leader addestrati su video generici, così come i migliori sistemi esistenti focalizzati sulla chirurgia basati principalmente su immagini statiche. Ha mostrato prestazioni solide anche su procedure mai viste durante l’addestramento, dimostrando che i pattern appresi non erano legati a un singolo organo, set di strumenti o ospedale.
Perché contano più dati video e più ricchezza
Lo studio ha anche esplorato come le prestazioni cambiano all’aumentare dei dati di addestramento. Man mano che gli autori hanno incrementato dimensione e varietà del pool di video, i risultati di SurgVISTA sono migliorati quasi ovunque, anche su procedure che non comparivano affatto nel set di addestramento. Interessante notare che il modello ha beneficiato non solo di più esempi della stessa operazione, ma anche di tipi diversi di interventi: l’esposizione a differenti “storie” chirurgiche lo ha aiutato a individuare pattern visivi e di movimento generali trasferibili tra le specialità. Esperimenti aggiuntivi hanno mostrato che la guida supplementare fornita dal modello esperto basato su immagini ha ulteriormente affilato la capacità del modello di preservare dettagli anatomici fini, cruciale per distinguere, ad esempio, una struttura vitale dal tessuto circostante.
Cosa significa questo per la chirurgia futura
In termini semplici, questo lavoro mostra che un’IA addestrata su grandi quantità di video chirurgici reali, con attenzione a spazio e tempo, può costruire una comprensione molto più profonda di ciò che accade in sala operatoria. SurgVISTA non è ancora uno strumento che prende decisioni in autonomia, ma fornisce una solida spina dorsale a cui altre applicazioni possono collegarsi—che si tratti di monitorare il progresso chirurgico, segnalare momenti a rischio, supportare la formazione o confrontare tecniche tra ospedali. Gli autori osservano che sono ancora necessari dati più ampi e test clinici, ma i loro risultati suggeriscono che i modelli di base basati su video potrebbero diventare un ingrediente chiave nei futuri sistemi chirurgici intelligenti volti a rendere le procedure più sicure, più coerenti e meglio adattate a ciascun paziente.
Citazione: Yang, S., Zhou, F., Mayer, L. et al. Large-scale self-supervised video foundation model for intelligent surgery. npj Digit. Med. 9, 220 (2026). https://doi.org/10.1038/s41746-026-02403-0
Parole chiave: video chirurgico AI, apprendimento self-supervised, flusso operativo, chirurgia assistita da computer, modellazione spazio-temporale