Clear Sky Science · it
Modelli di apprendimento automatico per la predizione delle interazioni tra farmaci: dalla scoperta computazionale all’applicazione clinica
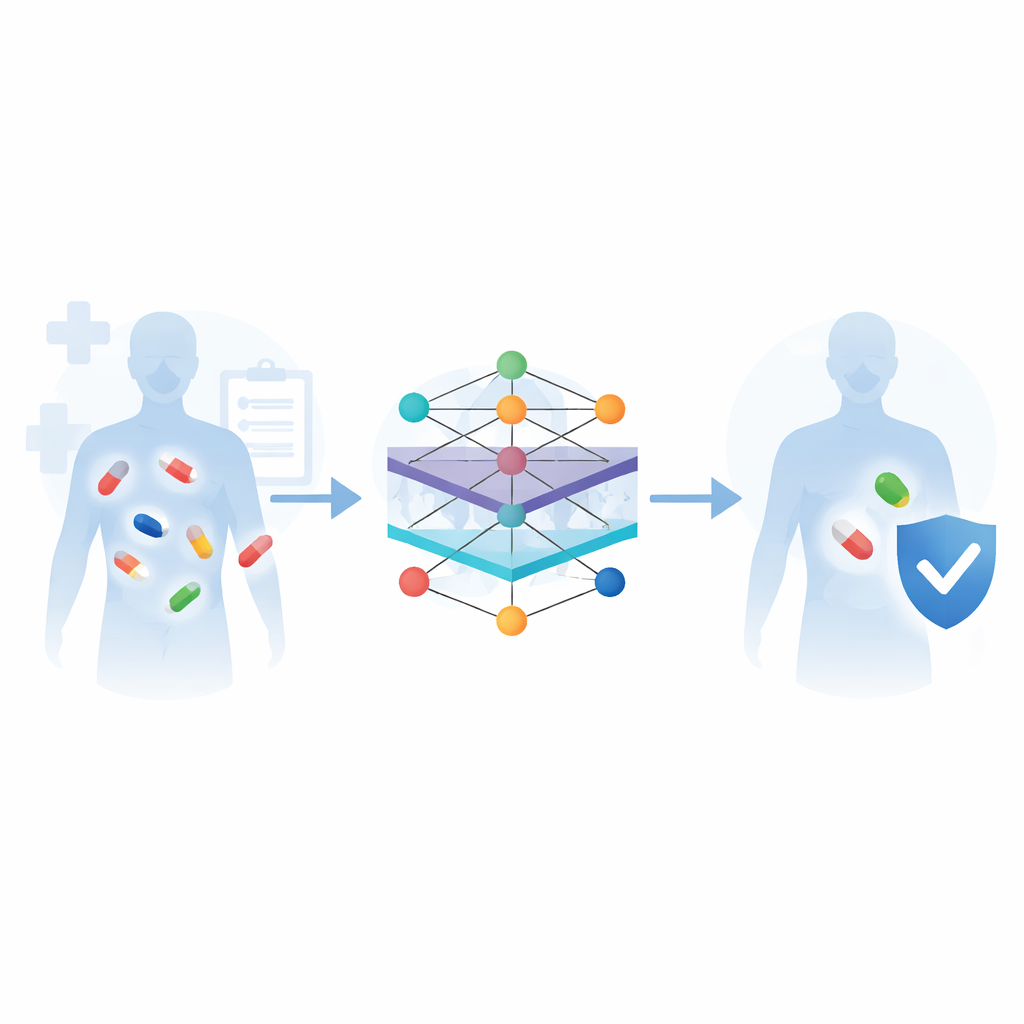
Perché combinare medicinali può essere rischioso
La medicina moderna spesso si basa sull’assunzione contemporanea di più farmaci—per il cancro, le malattie cardiovascolari, le infezioni o semplicemente per gestire le molte condizioni associate all’invecchiamento. Ma quando i farmaci si incontrano nell’organismo possono modificare gli effetti reciproci, a volte riducendo l’efficacia del trattamento o rendendolo pericoloso. Questa rassegna esamina come l’intelligenza artificiale, in particolare i moderni metodi di apprendimento automatico, venga impiegata per prevedere in anticipo queste interazioni tra farmaci, così che i medici possano scegliere combinazioni più sicure e personalizzare le terapie per i singoli pazienti.
Dal tentativo e errore alla sicurezza guidata dai dati
Tradizionalmente, combinazioni farmacologiche preoccupanti sono state scoperte nel modo più difficile—durante sperimentazioni cliniche in fase avanzata o dopo che un farmaco è già sul mercato e i pazienti sono stati danneggiati. I test di laboratorio su cellule, animali e volontari restano lo standard di riferimento, ma sono lenti, costosi e impossibili da applicare all’enorme numero di coppie di farmaci potenziali. Gli autori sostengono che la predizione computazionale offre una via d’uscita da questo collo di bottiglia. Imparando da vaste collezioni digitali di informazioni sui farmaci—come strutture chimiche, bersagli nell’organismo, effetti avversi noti e segnalazioni reali di reazioni avverse—i sistemi di apprendimento automatico possono segnalare coppie a rischio molto prima che raggiungano un gran numero di pazienti.
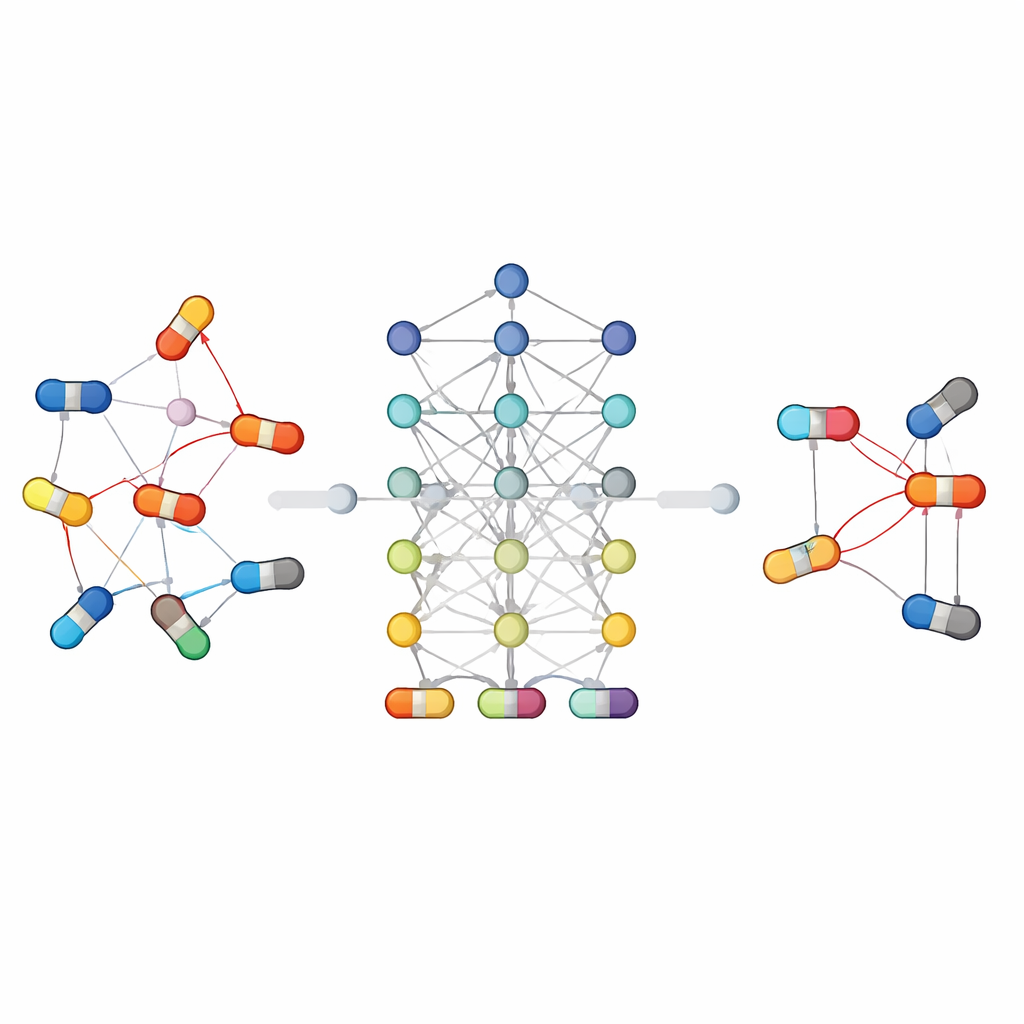
Come le macchine apprendono da molti tipi di dati sui farmaci
La rassegna spiega un flusso di lavoro comune per questi sistemi di predizione. Innanzitutto si raccolgono informazioni da principali banche dati biomediche: librerie chimiche che descrivono l’aspetto di ogni molecola, mappe di vie metaboliche che mostrano come i farmaci sono processati nell’organismo e elenchi curati di interazioni ed effetti collaterali noti. Successivamente gli algoritmi convertono queste informazioni grezze in pattern numerici comprensibili ai computer—ad esempio misurando quanto due farmaci siano simili o rappresentando ciascun farmaco come un nodo in una rete collegato ai suoi bersagli, alle vie e alle reazioni passate. Diversi modelli di apprendimento automatico vengono quindi addestrati a riconoscere quali coppie di farmaci tendono a causare problemi, e le loro prestazioni sono verificate su set di dati di riferimento usando misure standard di accuratezza.
Diverse famiglie di algoritmi affrontano il problema a modo loro
Poiché le interazioni farmacologiche sono complesse, nessun tipo di modello è il migliore per tutte le situazioni. Alcuni approcci si basano su classificatori tradizionali che lavorano con caratteristiche costruite a mano, mentre altri apprendono direttamente dalla struttura delle molecole o dalla rete di connessioni tra farmaci ed entità biologiche. I metodi basati su grafi e il deep learning sono stati particolarmente efficaci: trattano i farmaci e le loro relazioni come una rete, permettendo all’algoritmo di “ragionare” su catene di connessioni che potrebbero essere invisibili a modelli più semplici. Altre strategie condividono informazioni tra compiti correlati, come prevedere sia se due farmaci interagiscono sia quale tipo di effetto producono, cosa utile quando i dati scarseggiano. L’articolo mette inoltre in luce nuove direzioni come i grandi modelli linguistici che leggono testi scientifici e note cliniche, e modelli generativi che esplorano possibili schemi di interazione in dataset molto ampi e sparsi.
Collegare le predizioni computazionali ai pazienti reali
Oltre ai metodi, l’articolo sottolinea come questi strumenti possano supportare la cura nel mondo reale. Gli autori discutono come modelli addestrati su banche dati curate e cartelle cliniche possano avvisare i clinici di combinazioni pericolose al letto del paziente, aiutare a progettare regimi multi-farmaco più sicuri in oncologia, cardiologia e malattie infettive, e dare priorità alle interazioni predette che meritano test di laboratorio. Esaminano anche esempi clinici classici—come antibiotici che alterano i livelli di farmaci ipocolesterolemizzanti, analgesici che inibiscono reciprocamente gli effetti o spremute di frutta che inaspettatamente aumentano le concentrazioni di un farmaco—to mostrare le molte vie attraverso cui nascono le interazioni. I sistemi di apprendimento automatico che catturano questi schemi possono quindi funzionare come dispositivi di allerta precoce, soprattutto nei pazienti anziani che assumono molti farmaci.
Sfide sulla strada verso un’IA affidabile per i farmaci
Nonostante un’accuratezza impressionante sui set di test, gli autori sottolineano che i modelli attuali affrontano ancora ostacoli importanti prima di poter essere ampiamente affidati nelle cliniche. Molti sono “scatole nere” che offrono scarsa comprensione del perché una specifica coppia sia giudicata rischiosa, rendendo difficile per i medici valutare o spiegare la raccomandazione. I modelli possono inciampare quando i dati sono rumorosi o sbilanciati—per esempio quando le interazioni dannose sono rare rispetto alle coppie sicure. Integrare informazioni tra chimica, genetica, cartelle cliniche elettroniche e letteratura pubblicata è tecnicamente difficile, e i quadri normativi richiedono prove solide prima che tali strumenti possano influenzare la prescrizione. Gli autori sostengono che il lavoro futuro debba concentrarsi su modelli più interpretabili, una migliore gestione di dati distorti e incompleti, e sistemi che possano apprendere continuamente dalla nuova esperienza clinica rispettando al contempo le regole di privacy e sicurezza.
Cosa significa questo per il trattamento quotidiano
In termini pratici, questa rassegna mostra che l’intelligenza artificiale sta diventando un potente alleato per mantenere sicure le combinazioni farmacologiche. Setacciando montagne di dati digitali ben oltre ciò che qualsiasi esperto umano potrebbe gestire, i modelli di apprendimento automatico possono mettere in evidenza coppie pericolose, suggerire alternative più sicure e supportare prescrizioni più personalizzate. Questi strumenti non sostituiranno il giudizio clinico o i test di laboratorio accurati, ma possono contribuire a garantire che la crescente complessità della terapia moderna non si traduca in un costo per la sicurezza del paziente.
Citazione: Lu, Y., Chen, J., Fan, N. et al. Machine learning models for drug-drug interaction prediction from computational discovery to clinical application. npj Digit. Med. 9, 198 (2026). https://doi.org/10.1038/s41746-026-02400-3
Parole chiave: interazioni tra farmaci, apprendimento automatico in medicina, reti neurali a grafo, farmacologia clinica, sicurezza dell’intelligenza artificiale