Clear Sky Science · it
I grandi modelli linguistici migliorano la trasferibilità delle previsioni basate su cartelle cliniche elettroniche tra paesi e sistemi di codifica
Perché è importante condividere meglio i dati medici
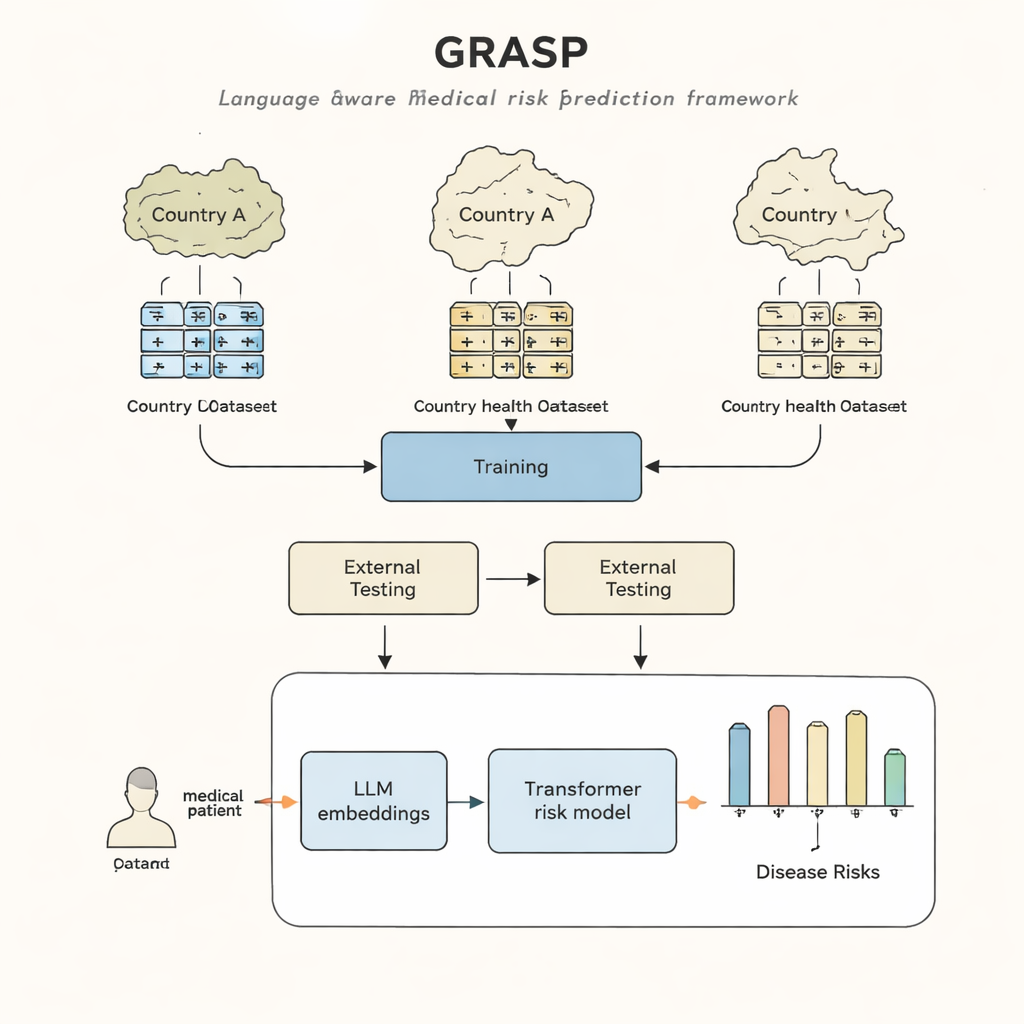
Ospedali e ambulatori in tutto il mondo dispongono di una miniera d’oro di informazioni: le cartelle cliniche elettroniche che registrano diagnosi, trattamenti e esiti per anni. In teoria, questi dati potrebbero aiutare i medici a individuare precocemente chi ha un alto rischio di malattie gravi, molto prima che compaiano i sintomi. Nella pratica, però, i modelli informatici faticano oggi a “viaggiare” da un paese o sistema sanitario all’altro perché ogni contesto registra i dati sanitari in modo diverso. Questo studio presenta un nuovo approccio, chiamato GRASP, che sfrutta i progressi dell’intelligenza artificiale per colmare queste lacune in modo che un modello addestrato in un sistema sanitario possa funzionare in modo affidabile anche in altri.
Ospedali diversi, linguaggi diversi
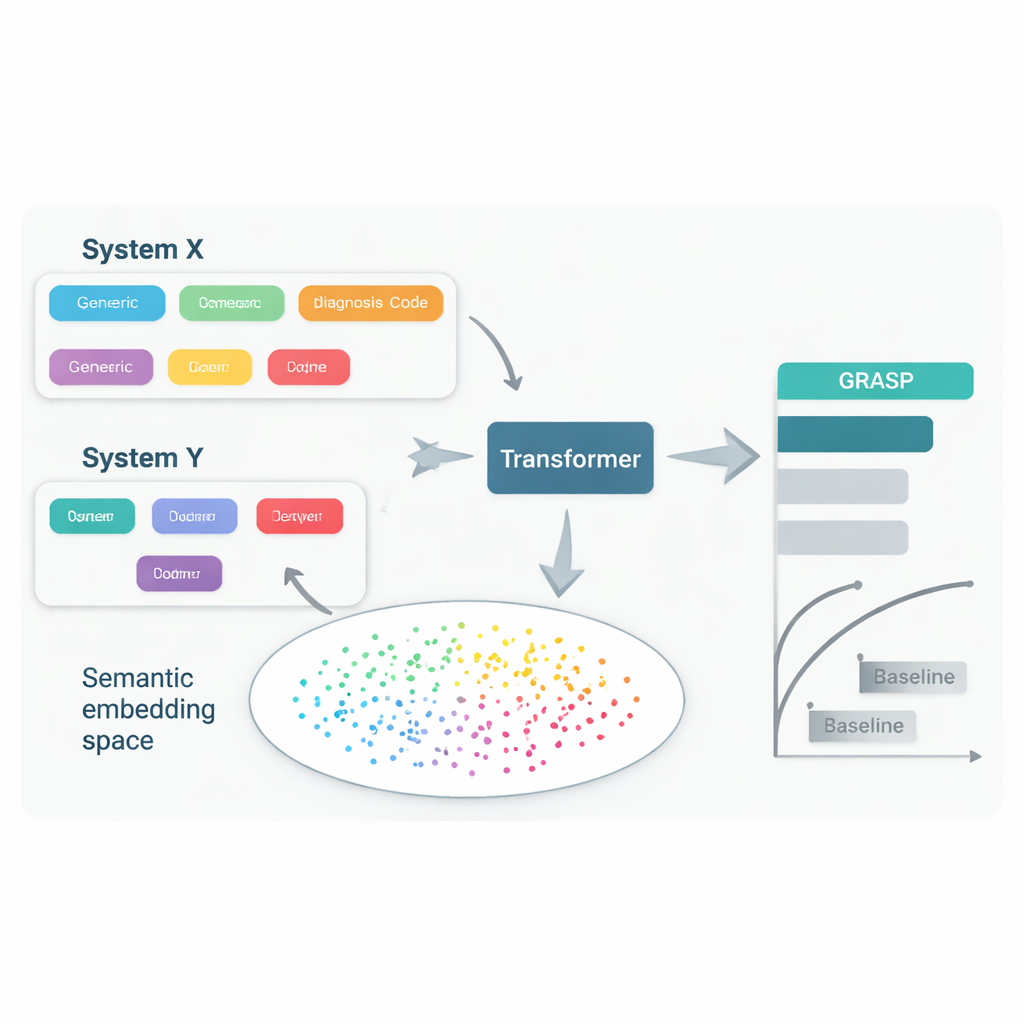
Anche quando i medici curano la stessa malattia, spesso usano diversi sistemi di codifica e abitudini locali per registrarla nella cartella clinica. Un ospedale può memorizzare “altissima glicemia” sotto un codice, un altro usare un codice diverso per “iperglicemia” e un terzo adottare un sistema ancora differente. Gli sforzi per uniformare tutto a uno standard comune—come grandi schemi di codifica internazionali—sono utili ma lenti, costosi e lasciano comunque differenze rilevanti. Di conseguenza, un modello che predice la malattia dalle cartelle di un paese può perdere accuratezza quando applicato altrove, limitando chi può beneficiare di questi strumenti.
Lasciare che l’IA legga il significato, non solo il codice
L’approccio GRASP parte da un’idea semplice: invece di trattare ogni codice medico come un numero identificativo privo di significato, lasciare che un grande modello linguistico legga la descrizione umana che lo accompagna, come “infezione acuta delle vie respiratorie superiori”, e trasformi quel significato in un “embedding” numerico. Questi embedding collocano concetti correlati vicino tra loro in uno spazio condiviso, anche se provengono da sistemi di codifica o paesi diversi. GRASP pre-calcola tali embedding per milioni di termini medici standard e li memorizza in una tabella di ricerca. La storia clinica di un paziente viene quindi rappresentata come una serie di questi vettori ricchi, che vengono passati a una rete transformer—un tipo di rete neurale adatto a gestire collezioni di input diversi—per stimare il rischio di 21 principali malattie oltre al rischio complessivo di morte.
Testare attraverso paesi e sistemi di registrazione
I ricercatori hanno addestrato GRASP usando i dati di quasi 400.000 partecipanti del UK Biobank, quindi l’hanno testato senza riaddestramento in due contesti molto diversi: il progetto FinnGen in Finlandia e una grande rete ospedaliera a New York City. GRASP ha eguagliato o superato alternative solide, tra cui un metodo popolare chiamato XGBoost e un transformer simile che non utilizzava embedding basati sul linguaggio. In Finlandia, GRASP ha ottenuto risultati particolarmente buoni, mostrando miglioramenti netti per condizioni come asma, malattia renale cronica e insufficienza cardiaca. Colpisce che, anche quando i dati ospedalieri statunitensi sono rimasti in un sistema di codifica diverso invece di essere convertiti in uno standard comune, GRASP abbia comunque fornito previsioni migliori rispetto alle sole informazioni demografiche, perché è stato in grado di allineare i codici comprendendo il testo delle loro descrizioni.
Ottenere di più con meno dati
Un altro vantaggio di GRASP è l’efficienza. Poiché il modello linguistico ha già appreso che molti concetti medici sono correlati, la rete di predizione non deve riscoprire queste connessioni da zero. Quando gli autori hanno addestrato GRASP su insiemi molto più piccoli di dati del Regno Unito—fino a soli 10.000 individui—ha comunque superato i modelli concorrenti addestrati sugli stessi campioni limitati, sia nel Regno Unito sia quando trasferito all’estero. I punteggi di rischio di GRASP erano inoltre più strettamente allineati con il rischio genetico ereditario delle persone per diverse malattie, suggerendo che cattura aspetti più profondi della suscettibilità alla malattia invece di limitarsi a memorizzare schemi di un singolo dataset.
Cosa significa per la cura futura
Per i non specialisti, il messaggio chiave è che GRASP mostra come l’IA moderna basata sul linguaggio possa aiutare diversi sistemi sanitari a “parlare la stessa lingua” senza costringerli in un unico schema di codifica rigido. Leggendo il significato dei termini medici, GRASP può offrire previsioni del rischio di malattia che si generalizzano meglio attraverso paesi e formati di registrazione, e può farlo con meno esempi di pazienti. Pur richiedendo ancora test accurati, ricalibrazione e verifiche di equità prima dell’uso nella pratica quotidiana, indica un futuro in cui potenti strumenti di valutazione del rischio sviluppati in un luogo possano essere condivisi in modo sicuro ed efficiente con ospedali e cliniche in tutto il mondo.
Citazione: Kirchler, M., Ferro, M., Lorenzini, V. et al. Large language models improve transferability of electronic health record-based predictions across countries and coding systems. npj Digit. Med. 9, 177 (2026). https://doi.org/10.1038/s41746-026-02363-5
Parole chiave: cartelle cliniche elettroniche, predizione del rischio di malattia, grandi modelli linguistici, condivisione dei dati medici, IA per la sanità