Clear Sky Science · it
Confronto tra apprendimento automatico decentralizzato e modelli clinici IA con alternative locali e centralizzate: una revisione sistematica
Perché condividere conoscenze mediche senza condividere i dati è importante
La medicina moderna si affida sempre più all’intelligenza artificiale per individuare le malattie precocemente, scegliere il trattamento corretto e prevedere chi è a maggior rischio. Tuttavia, i migliori strumenti di IA richiedono grandi quantità di dati dei pazienti, e gli ospedali non possono semplicemente unire i loro archivi a causa di norme sulla privacy e preoccupazioni etiche. Questo articolo esamina oltre un decennio di ricerche sull’“apprendimento decentralizzato” — modi per fare in modo che gli ospedali addestrino l’IA insieme senza condividere mai i dati grezzi dei pazienti — e pone una domanda pratica: quanto rendono davvero questi metodi che preservano la privacy rispetto agli approcci tradizionali?
Nuove modalità per apprendere dai pazienti proteggendo la privacy
Nell’apprendimento centralizzato tradizionale, gli ospedali copiano tutti i loro dati in un unico grande database e addestrano lì un singolo modello. Nell’apprendimento locale, ciascuna istituzione costruisce il proprio modello sui propri dati, senza collaborazione. L’apprendimento decentralizzato offre una via di mezzo. Nel federated learning, per esempio, ogni ospedale addestra un modello in locale e poi vengono condivisi solo i parametri del modello (come le “manopole” di una rete neurale) per essere combinati in un modello condiviso; i dossier dei pazienti non lasciano mai la struttura. Lo swarm learning elimina il coordinatore centrale e permette alle istituzioni di scambiarsi direttamente gli aggiornamenti del modello. Altri approcci decentralizzati combinano le previsioni di più modelli locali o suddividono il modello fra i siti. Questi metodi sono stati testati su problemi che vanno dalla rilevazione del cancro e la diagnosi di COVID‑19 fino alle malattie cardiache, al diabete, ai disturbi cerebrali e alle condizioni psichiatriche.
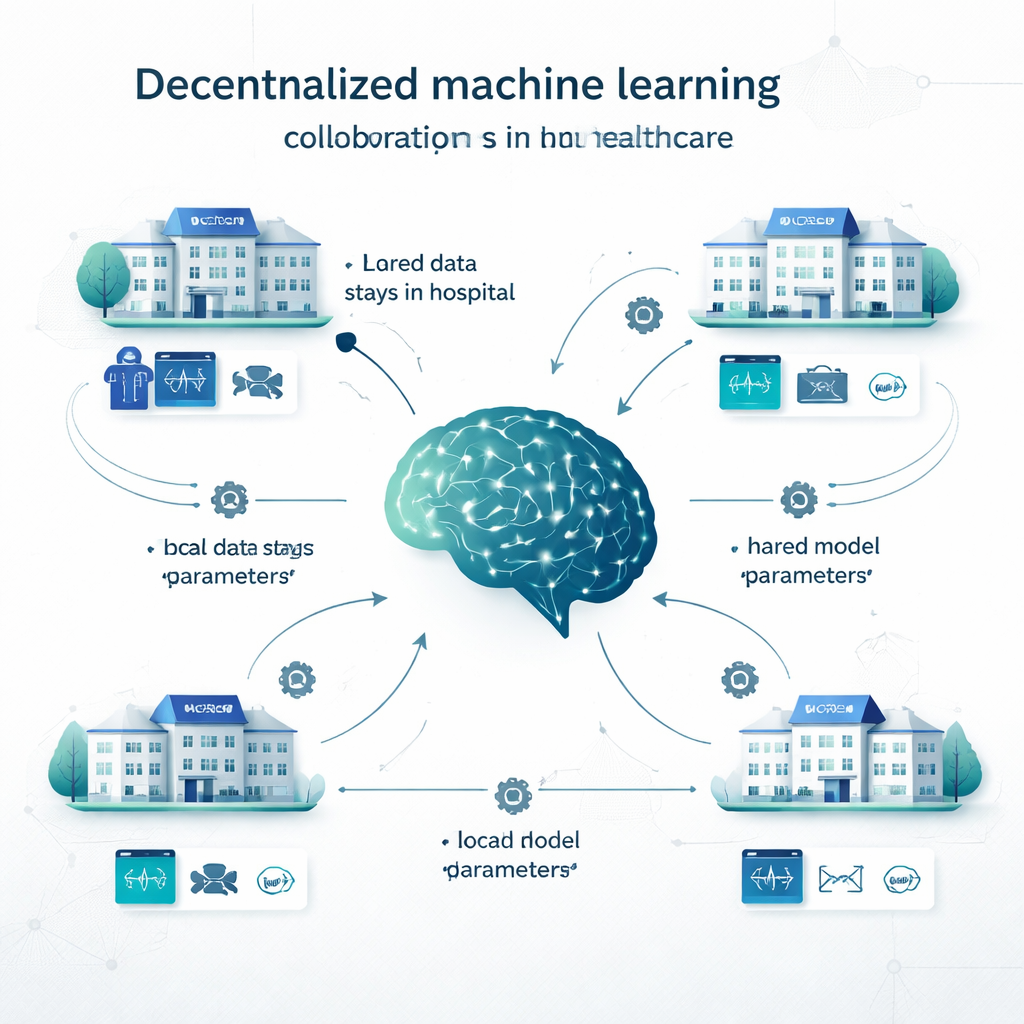
Cosa hanno esaminato i ricercatori
Gli autori hanno cercato sistematicamente in 11 principali banche dati e hanno selezionato 165.010 studi pubblicati tra il 2012 e marzo 2024. Dopo aver rimosso i duplicati e gli studi che non riguardavano decisioni cliniche reali, sono rimasti 160 articoli. Complessivamente, questi lavori riportavano 710 modelli decentralizzati e 8.149 confronti diretti delle prestazioni rispetto a modelli centralizzati o locali. La maggior parte degli studi si è concentrata sulla diagnosi, ma ce ne sono stati molti anche sulla segmentazione di immagini (per esempio per delineare i tumori), sulla previsione di esiti futuri come sopravvivenza o complicanze, e su compiti combinati. I tipi di dati coperti includevano quasi tutte le principali fonti usate in medicina: cartelle cliniche elettroniche, TC e risonanze, radiografie, vetrini di patologia digitale, segnali cardiaci e cerebrali e persino dati genetici.
Come si confrontano i modelli che preservano la privacy con l’IA centralizzata
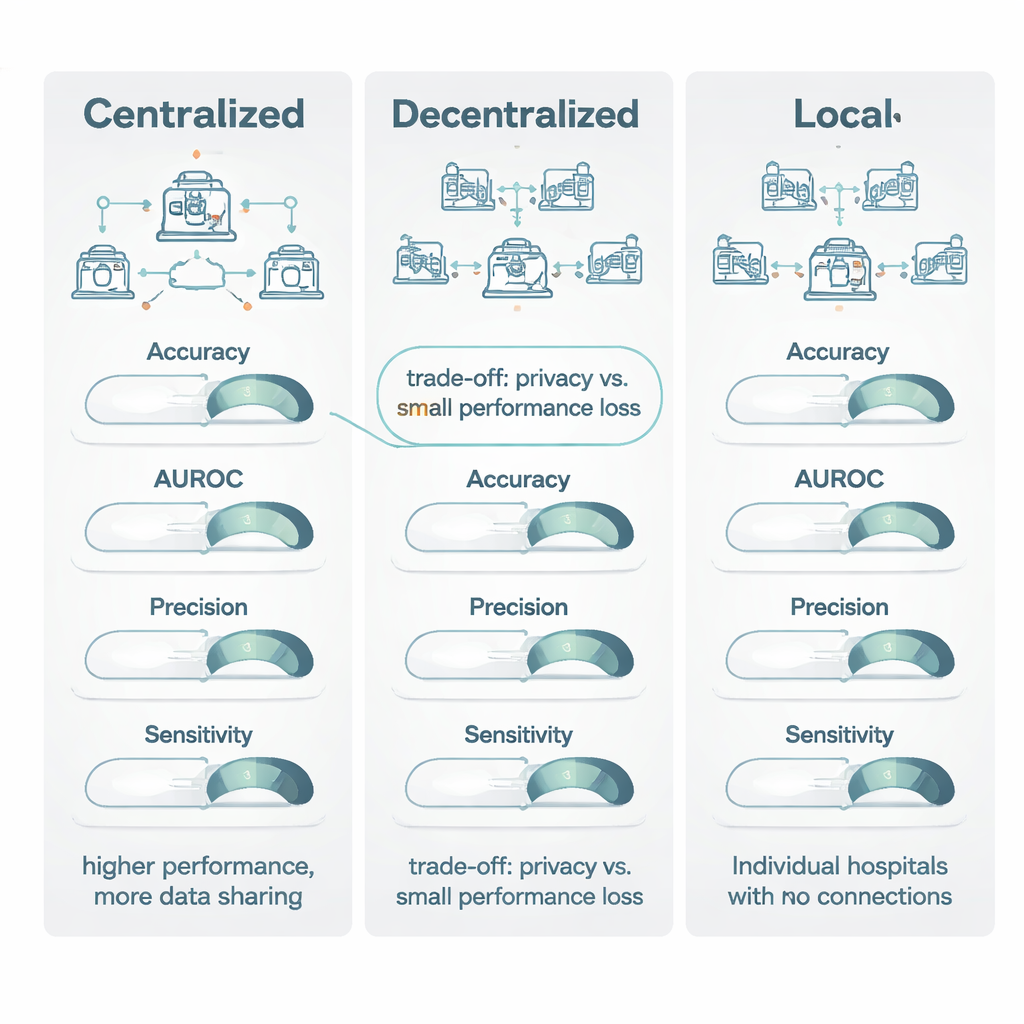
Quando i modelli decentralizzati sono stati confrontati con quelli centralizzati addestrati su dati aggregati, l’apprendimento centralizzato è risultato di solito leggermente in vantaggio. Ha performato particolarmente bene su misure “a soglia” come l’accuratezza e un comune indice per le immagini chiamato coefficiente Dice, vincendo circa tre quarti delle volte e con un margine sufficiente a essere considerato un vantaggio da moderato a ampio. Tuttavia, per misure di tipo ordinamento — come l’area sotto la curva ROC (AUROC), che cattura quanto bene un modello classifica i pazienti da rischio basso ad alto — i modelli decentralizzati e centralizzati erano molto più vicini, con solo un piccolo vantaggio per l’addestramento centralizzato. È importante notare che, quando entrambi i modelli raggiungevano quella che gli autori chiamano performance “clinicamente valide” (un punteggio di almeno 0,80), il guadagno tipico del modello centralizzato era modesto: spesso inferiore a 1–1,5 punti percentuali. In molte situazioni questo equivaleva a “eccellente contro accettabile”, non a “utilizzabile contro inutile”.
Perché l’apprendimento decentralizzato è meglio che andare da soli
Il segnale più forte nella revisione è emerso confrontando i modelli decentralizzati con quelli puramente locali. Su tutte le principali metriche — accuratezza, AUROC, F1, sensibilità, specificità e soprattutto precisione — i metodi decentralizzati hanno quasi sempre ottenuto risultati migliori, spesso con ampi margini. Nei confronti diretti, l’apprendimento decentralizzato ha superato i modelli locali in oltre l’80% dei confronti per misure chiave come accuratezza, precisione e AUROC. In molti casi, i modelli locali non riuscivano a raggiungere la soglia di 0,80 per l’utilità clinica, mentre il corrispondente modello decentralizzato la superava comodamente, migliorando la sensibilità anche di 27 punti percentuali. Gli autori attribuiscono questo vantaggio all’esperienza più ampia che acquisiscono i modelli multi‑sito: vedendo i pattern provenienti da molti ospedali, sono meno ingannati da peculiarità locali degli scanner o delle anagrafiche e più sensibili a caratteristiche della malattia che si generalizzano realmente.
Bilanciare prestazioni, privacy e uso pratico
La revisione conclude che l’apprendimento centralizzato rimane lo standard d’oro quando le regole sulla privacy e la logistica consentono di combinare i dati e quando ogni frazione di punto percentuale nelle prestazioni è importante, come nel caso di malattie molto rare. Tuttavia, l’apprendimento decentralizzato offre un’alternativa potente e clinicamente accettabile nelle situazioni in cui la condivisione dei dati è limitata da leggi come il GDPR e l’AI Act dell’UE, o da politiche istituzionali. Rispetto al mantenere i modelli interamente locali, gli approcci decentralizzati forniscono grandi miglioramenti sia in accuratezza che in affidabilità mantenendo i dati all’interno delle mura ospedaliere. Gli autori sostengono che i lavori futuri dovrebbero riportare in modo più chiaro le tecniche di privacy e i costi computazionali, così che i sistemi sanitari possano fare scelte informate su quando lievi compromessi di performance valgono i sostanziali benefici in termini di privacy e collaborazione.
Citazione: Diniz, J.M., Vasconcelos, H., Rb-Silva, R. et al. Comparing decentralized machine learning and AI clinical models to local and centralized alternatives: a systematic review. npj Digit. Med. 9, 174 (2026). https://doi.org/10.1038/s41746-025-02329-z
Parole chiave: federated learning, IA per la sanità, privacy dei dati medici, apprendimento automatico decentralizzato, modelli predittivi clinici