Clear Sky Science · it
Generalizzazione della segmentazione automatica dei tumori in immagini istopatologiche a scansione integrale attraverso più tipi di cancro
Perché questo è importante per la cura del cancro
La diagnosi del cancro si basa ancora sull’esame attento, da parte di esperti, di vetrini di tessuto colorati al microscopio — un compito che richiede molto tempo, reso più difficile dall’aumento dei casi e dalla carenza di patologi. Questo studio pone una domanda semplice ma potente: può un singolo sistema di intelligenza artificiale individuare in modo affidabile le aree cancerose in immagini digitali del microscopio per molti tipi di tumore diversi, invece di costruire uno strumento separato per ogni cancro? Se sì, potrebbe alleggerire i carichi di lavoro, accelerare la diagnosi ed estendere analisi avanzate anche ai tumori rari per i quali i dati scarseggiano.
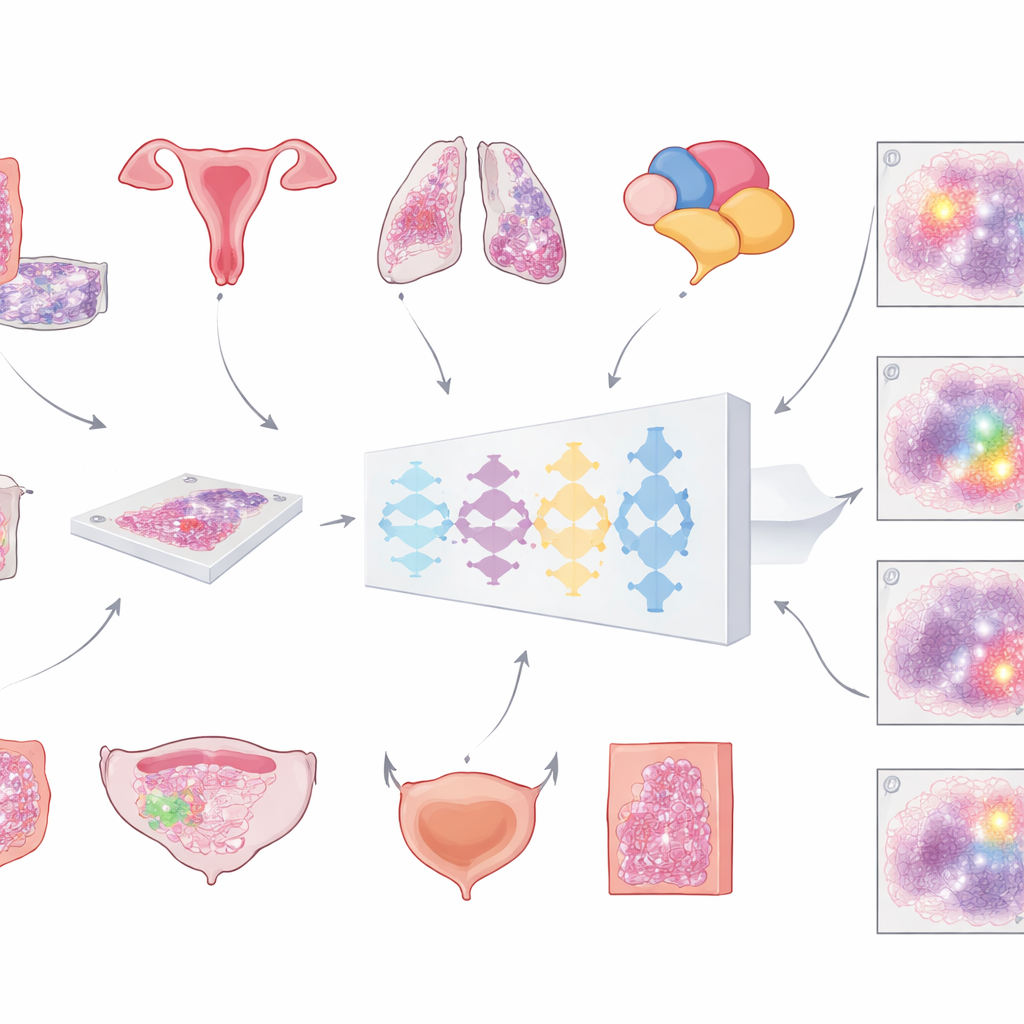
Dai vetrini di vetro agli assistenti digitali
Gli ospedali moderni stanno sempre più spesso digitalizzando i vetrini per creare enormi e dettagliate “immagini a scansione integrale” dei tumori. Il primo passo cruciale per qualsiasi analisi computerizzata è separare il tessuto tumorale da tutto il resto — cellule normali, grasso, vetro vuoto e artefatti. Finora, la maggior parte degli strumenti automatizzati è stata addestrata su un solo tipo di cancro, limitandone l’ambito di applicazione. Il gruppo dietro questo lavoro si è proposto di costruire un unico modello universale in grado di individuare le regioni tumorali in diversi tumori comuni su vetrini colorati con gli usuali coloranti ematossilina ed eosina. La loro visione era uno strumento generale che potesse integrarsi in molti flussi diagnostici senza doverlo riprogettare ogni volta.
Addestrare un modello per riconoscere molti tumori
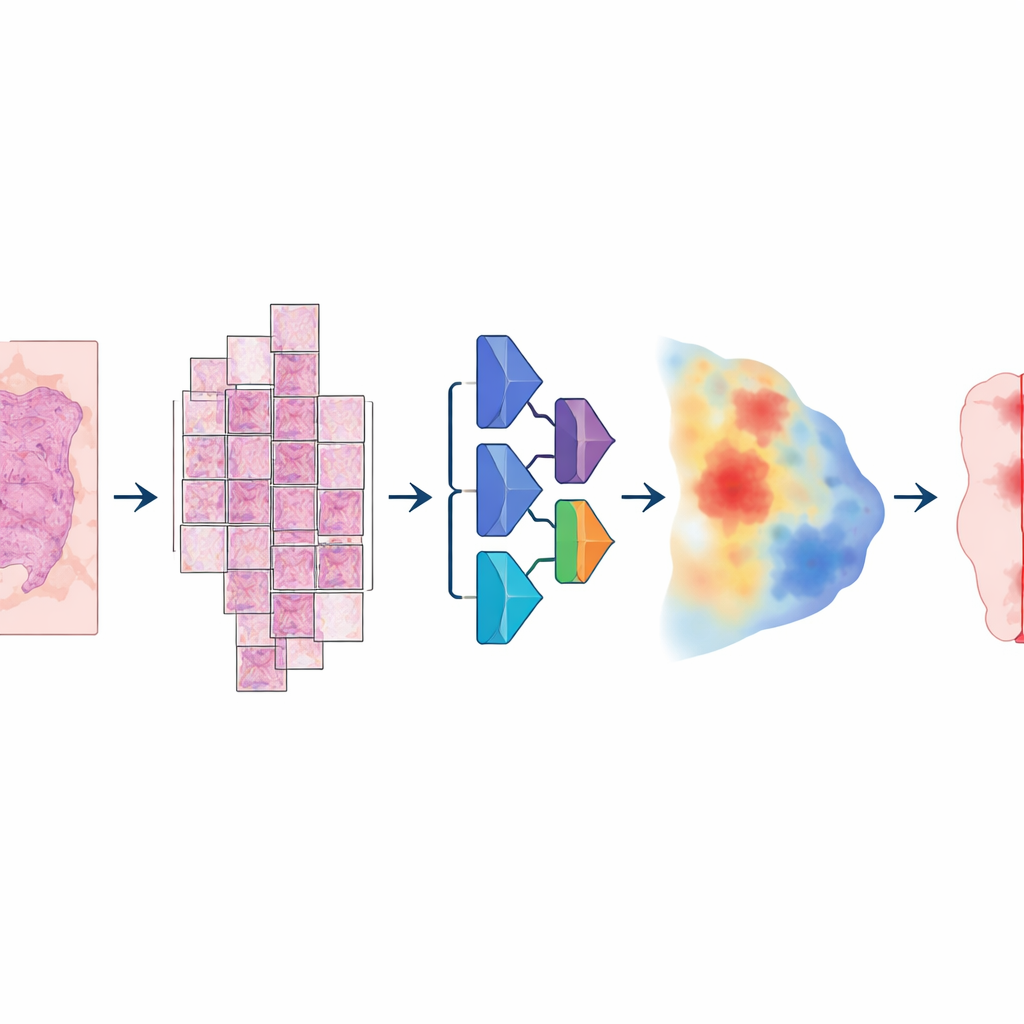
Per costruire questo modello i ricercatori hanno messo insieme una raccolta insolitamente ampia e varia di immagini digitali: più di 20.000 immagini a scansione integrale provenienti da oltre 4.000 pazienti con carcinoma colorettale, endometriale, polmonare e prostatico. Tutti i campioni derivavano da tessuto fissato in formalina e incluso in paraffina secondo protocolli standard e sono stati scansionati su due diversi scanner ad alta risoluzione. Un patologo ha delineato con cura le aree tumorali su ogni vetrino, fornendo la “verità di riferimento” da cui il computer avrebbe appreso. Il modello ha seguito una pipeline a più fasi: ogni immagine enorme è stata suddivisa in grandi tasselli sovrapposti, passata attraverso una rete neurale profonda che ha stimato, per ogni pixel, la probabilità di essere tumorale, e poi riassemblata in una mappa continua che è stata infine convertita in una maschera pulita tumore-versus-non-tumore.
Mettere il sistema alla prova
Elemento cruciale, il team non si è fermato alle prestazioni in fase di addestramento. Hanno testato lo stesso modello su più di 3.000 pazienti aggiuntivi in sei tipi di cancro — inclusi tumori mammari e della vescica che non erano mai stati usati durante l’addestramento — e su vetrini provenienti da più ospedali e scanner. L’accuratezza è stata valutata principalmente con un punteggio standard di sovrapposizione (la coefficiente di Dice), che raggiunge il 100% quando il contorno tumorale del computer corrisponde perfettamente a quello del patologo. Per campioni tumorali ampi e integri in carcinoma colorettale, endometriale, polmonare, prostatico e mammario, la sovrapposizione media ha superato l’80% e spesso il 90%. In grandi raccolte esterne provenienti da The Cancer Genome Atlas, tratte da molti laboratori e scanner nel mondo, le prestazioni sono rimaste nuovamente oltre l’80%, suggerendo che il modello si generalizza bene oltre l’istituzione di origine.
Dove fatica e come si confronta
La debolezza principale è emersa nei carcinomi della vescica in stadio precoce campionati con una procedura che produce piccoli pezzi di tessuto frammentati. In questi casi, il modello spesso non rilevava alcun tumore, specialmente quando l’area tumorale era molto piccola. Tuttavia, quando rilevava il tumore, la sovrapposizione con i contorni del patologo era elevata, e semplici aggiustamenti alle soglie finali miglioravano i risultati — suggerendo che la rete sottostante riconosceva il pattern, ma il post-processing era troppo severo. I ricercatori hanno anche costruito quattro modelli “specialisti”, ciascuno addestrato su un singolo tipo di cancro, e hanno scoperto che nessuno ha superato in modo significativo il modello generale nel proprio dominio. Al contrario, questi sistemi specialistici fallivano in gran parte quando applicati ad altri tipi di cancro, mentre il modello generale restava robusto. Rispetto a uno strumento di segmentazione medico più generico e diffuso che richiede suggerimenti da parte dell’utente, il nuovo modello generalmente si è comportato altrettanto bene o meglio rimanendo completamente automatico.
Cosa significa per pazienti e medici
Per i non esperti, il punto chiave è che un singolo sistema di IA ben progettato può evidenziare in modo affidabile il tessuto canceroso su vetrini digitali in diversi tipi principali di tumore, senza richiedere versioni personalizzate per ogni malattia o scanner. Non sostituisce il patologo, ma può pre-segnare le regioni probabilmente tumorali, supportare misurazioni coerenti e permettere agli specialisti di concentrarsi sui casi più complessi. La versione attuale manca ancora di alcuni tumori molto piccoli o in stadio precoce — in particolare campioni frammentati della vescica e verosimilmente altri tessuti simili a biopsie — quindi non è ancora adatta a rilevare le tracce più deboli di cancro. Tuttavia, lo studio dimostra che una segmentazione tumorale ampia e “pan-cancro” è fattibile in condizioni reali e può costituire un primo passo solido per futuri strumenti automatizzati che valutano il grado del cancro, prevedono la risposta al trattamento o guidano terapie di precisione.
Citazione: Skrede, OJ., Pradhan, M., Isaksen, M.X. et al. Generalisation of automatic tumour segmentation in histopathological whole-slide images across multiple cancer types. npj Precis. Onc. 10, 107 (2026). https://doi.org/10.1038/s41698-026-01311-6
Parole chiave: patologia digitale, apprendimento profondo, segmentazione del tumore, immagini a scansione integrale, modello pan-cancro