Clear Sky Science · it
IMFLKD: un meccanismo di incentivo per l’apprendimento federato decentralizzato basato sulla distillazione della conoscenza
Perché lo scambio può essere sicuro ed equo
L’intelligenza artificiale moderna si nutre di dati, tuttavia la maggior parte dei nostri dati risiede su telefoni personali, server ospedalieri o cloud aziendali che non possono essere semplicemente copiati e condivisi. L’apprendimento federato offre un modo per molti dispositivi di addestrare un modello condiviso senza esporre i dati grezzi, ma i sistemi attuali sono ancora vulnerabili a fughe di privacy, punti centrali di guasto e ricompense ingiuste per chi contribuisce di più. Questo articolo presenta un nuovo framework, IMFLKD, che combina tre idee potenti — blockchain, distillazione della conoscenza e valutazione della reputazione — per rendere questo tipo di apprendimento collettivo più privato, più robusto e più equo nel lungo periodo.
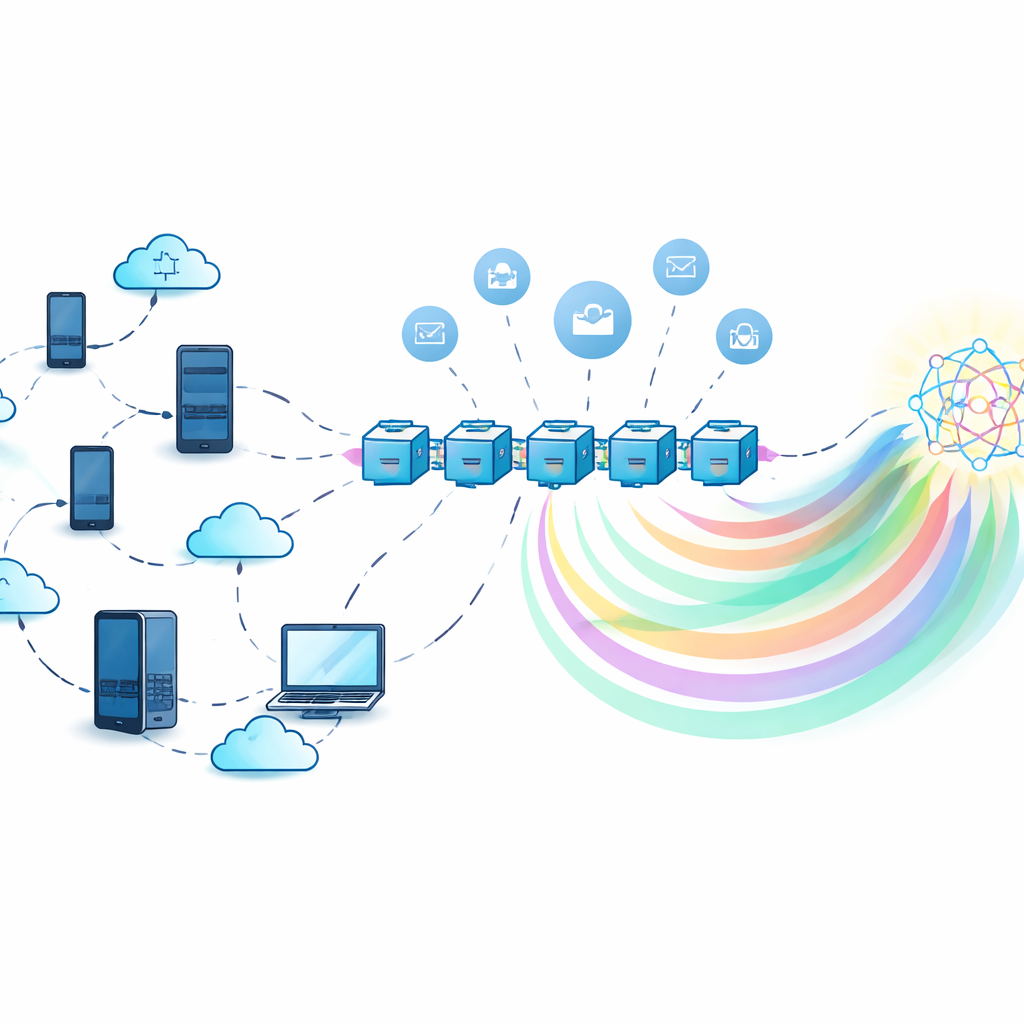
Addestrare insieme senza condividere i segreti
Nell’apprendimento federato classico, un server centrale raccoglie aggiornamenti del modello da molti partecipanti e li combina. Questo evita che i dati grezzi circolino, ma il server stesso diventa un bersaglio appetibile: se fallisce, l’intero sistema si blocca, e se non è affidabile può abusare o perdere informazioni nascoste negli aggiornamenti del modello. Gli autori invece utilizzano un registro decentralizzato su blockchain per coordinare l’addestramento. Ogni partecipante allena un modello locale sui propri dati e poi interagisce con smart contract sulla blockchain che registrano i contributi, aggregano informazioni e distribuiscono ricompense, il tutto senza dipendere da una singola autorità centrale.
Condividere conoscenza, non modelli pesanti
Per ridurre i costi di comunicazione e proteggere ulteriormente la privacy, il framework si basa sulla distillazione della conoscenza. Piuttosto che inviare parametri completi del modello, ogni partecipante manda soltanto “soft label” — le probabilità previste del modello per un insieme di input condivisi — che sono molto più leggere e rivelano meno sui dati di ciascuno. Poiché un vero dataset condiviso potrebbe non esistere, il sistema utilizza un modello generativo chiamato autoencoder variazionale condizionale per creare un dataset sintetico “pseudo-pubblico” che approssima la distribuzione complessiva delle etichette senza esporre record originali. I partecipanti si addestrano sui propri dati, effettuano predizioni su questo dataset sintetico e poi affinano i loro modelli usando un segnale aggregato derivato dalla conoscenza combinata di tutti.
Misurare chi aiuta davvero
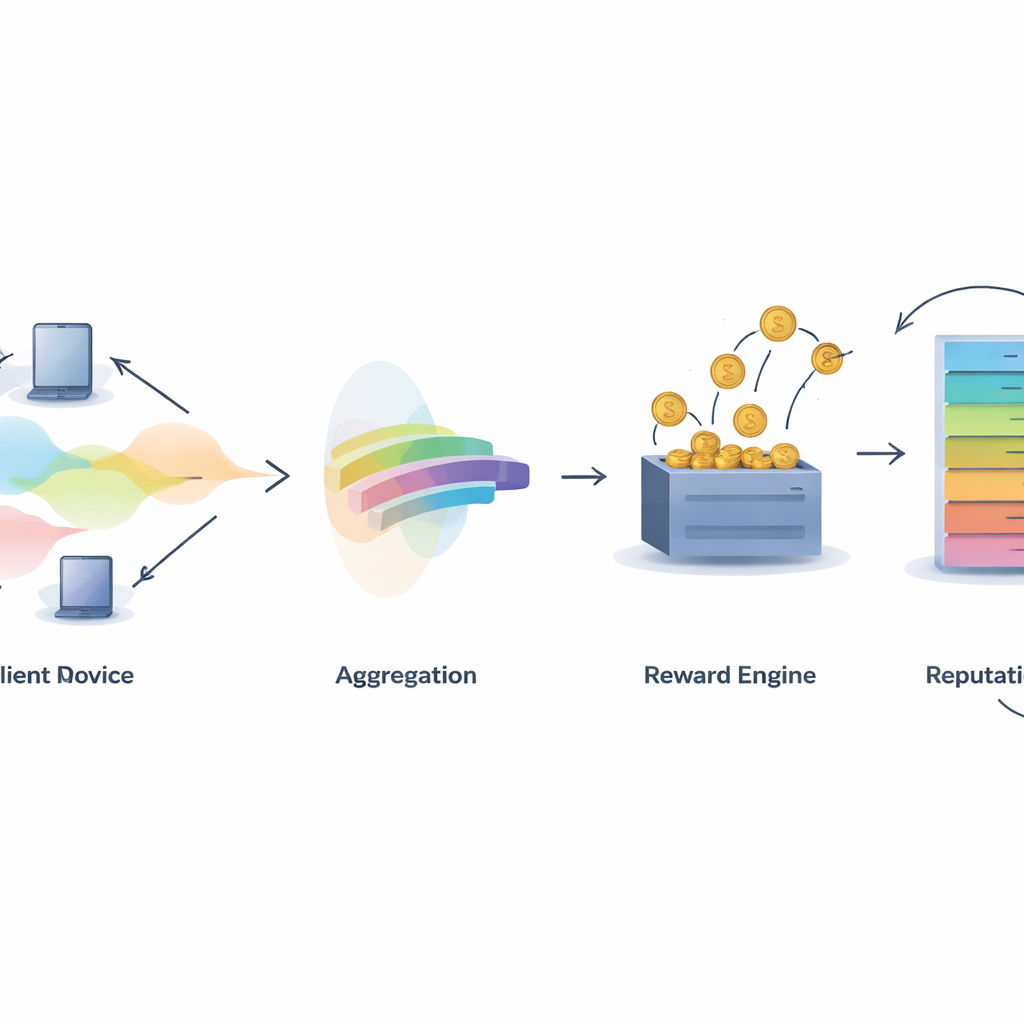
Una sfida centrale in qualsiasi sistema collaborativo è decidere chi merita credito. IMFLKD affronta questo con un metodo di valutazione del contributo in due fasi basato sull’aggregazione delle etichette. Innanzitutto, un algoritmo bayesiano leggero esamina le predizioni di tutti i partecipanti e inferisce sia l’etichetta più probabile per ciascun campione sia un punteggio di qualità per ciascun modello, aggiornando questi punteggi man mano che arrivano nuovi compiti. Questo approccio funziona online, senza memorizzare dati passati, e gestisce contributori rumorosi o malevoli diminuendo il peso dei modelli che spesso discordano dal consenso emergente. Gli esperimenti mostrano che questa aggregazione delle etichette migliora l’accuratezza di circa il 10 percento rispetto al semplice voto di maggioranza, rimanendo sufficientemente veloce per ambienti su larga scala e con risorse limitate.
Trasformare la qualità in ricompense e reputazione
Una volta nota la qualità del contributo, IMFLKD utilizza uno schema di incentivi chiamato weighted peer truth serum per convertirla in ricompense. I partecipanti vengono confrontati con un consenso tra pari ponderato per la qualità: chi le cui predizioni si allineano con pari di alta qualità guadagna di più, mentre chi devia o è spesso in disaccordo viene penalizzato. Questo rende la segnalazione onesta la strategia più proficua nel lungo termine, anche di fronte a collusioni. Inoltre, il sistema costruisce un punteggio di reputazione multidimensionale per ciascun partecipante, combinando qualità dei dati, livello di attività e stabilità comportamentale, e adeguando comportamenti passati con un fattore di decadimento temporale. La reputazione viene quindi reinserita nei round successivi influenzando quanto peso hanno le predizioni di un partecipante e se viene selezionato per compiti futuri.
Costruire fiducia nell’intelligenza collettiva
Nel complesso, il framework IMFLKD dimostra che è possibile coordinare l’apprendimento tra molti dispositivi indipendenti in modo efficiente, attento alla privacy e resistente a parassiti e attaccanti. Mescolando generazione di dati sintetici, una rigorosa valutazione dei contributi, ricompense basate sulla teoria dei giochi e tracciamento dinamico della reputazione su una blockchain, il sistema incoraggia i partecipanti a comportarsi in modo onesto e coerente su molti round di addestramento. Per un lettore non tecnico, la conclusione è che possiamo sfruttare il potere collettivo dei dati distribuiti — come cartelle cliniche, rilevamenti di sensori o dispositivi personali — senza consegnare tutto a una singola azienda o server, assicurando al contempo che chi fornisce le informazioni più utili sia anche chi ne beneficia maggiormente.
Citazione: Ying, X., Yan, K., Gao, X. et al. IMFLKD: an incentive mechanism for decentralized federated learning based on knowledge distillation. Sci Rep 16, 10567 (2026). https://doi.org/10.1038/s41598-026-46234-1
Parole chiave: apprendimento federato, blockchain, distillazione della conoscenza, meccanismi di incentivo, sistemi di reputazione