Clear Sky Science · it
PlantCLR: preaddestramento auto-supervisionato contrastivo per il rilevamento generalizzabile delle malattie delle piante
Perché è importante riconoscere meglio le malattie delle piante
Le malattie delle piante sottraggono silenziosamente cibo dalla tavola mondiale, riducendo le rese e danneggiando i redditi degli agricoltori. In molte aree sono disponibili solo pochi esperti formati per identificare i problemi sul campo, e ottenere il loro aiuto può essere lento o impossibile. Questo studio presenta PlantCLR, un sistema informatico che impara a riconoscere le malattie da foto di foglie usando molte meno etichette fornite dall’uomo rispetto al solito. Rendendo la diagnosi automatica più accurata, più affidabile e più facile da distribuire su hardware modesto, il lavoro indica la via verso strumenti basati su smartphone o fotocamere economiche che potrebbero aiutare gli agricoltori a individuare i problemi precocemente e proteggere i raccolti.
Dalle foto delle foglie agli avvisi precoci
Oggi molte malattie delle piante vengono diagnosticate alla vecchia maniera: una persona osserva una foglia e decide se macchie, ingiallimento o accartocciamento siano segni di infezione. Questo giudizio può variare da esperto a esperto ed è facilmente influenzato da ombre, sfondi disordinati o diversi stadi di crescita. I sistemi di visione artificiale basati su deep learning hanno iniziato a dare una mano, ma di solito richiedono decine di migliaia di foto accuratamente annotate. In agricoltura tali immagini etichettate sono scarse e costose da raccogliere, mentre grandi quantità di foto non etichettate da telefoni e fotocamere di campo restano spesso inutilizzate. PlantCLR è progettato per sfruttare questi dati non etichettati, imparando quale aspetto tendono ad avere foglie sane e malate prima ancora di vedere una singola etichetta.
Insegnare a un modello a imparare per confronto
PlantCLR si basa su un approccio recente chiamato apprendimento auto-supervisionato contrastivo, in cui il modello si istruisce confrontando immagini invece di leggere etichette. Prima, il sistema prende un’immagine di foglia non etichettata e crea due versioni leggermente diverse tramite ritagli casuali, riflessioni, variazioni di colore o sfocatura. Queste due versioni dovrebbero rappresentare chiaramente la stessa foglia, quindi il modello viene addestrato a considerarle una coppia corrispondente e a dare loro rappresentazioni interne simili, mentre allontana le rappresentazioni di foglie diverse presenti nello stesso batch di addestramento. Questa fase di preaddestramento utilizza un backbone compatto ma moderno per l’elaborazione delle immagini chiamato ConvNeXt-Tiny, affiancato da un piccolo modulo aggiuntivo usato solo durante questo passaggio di apprendimento per confronto. 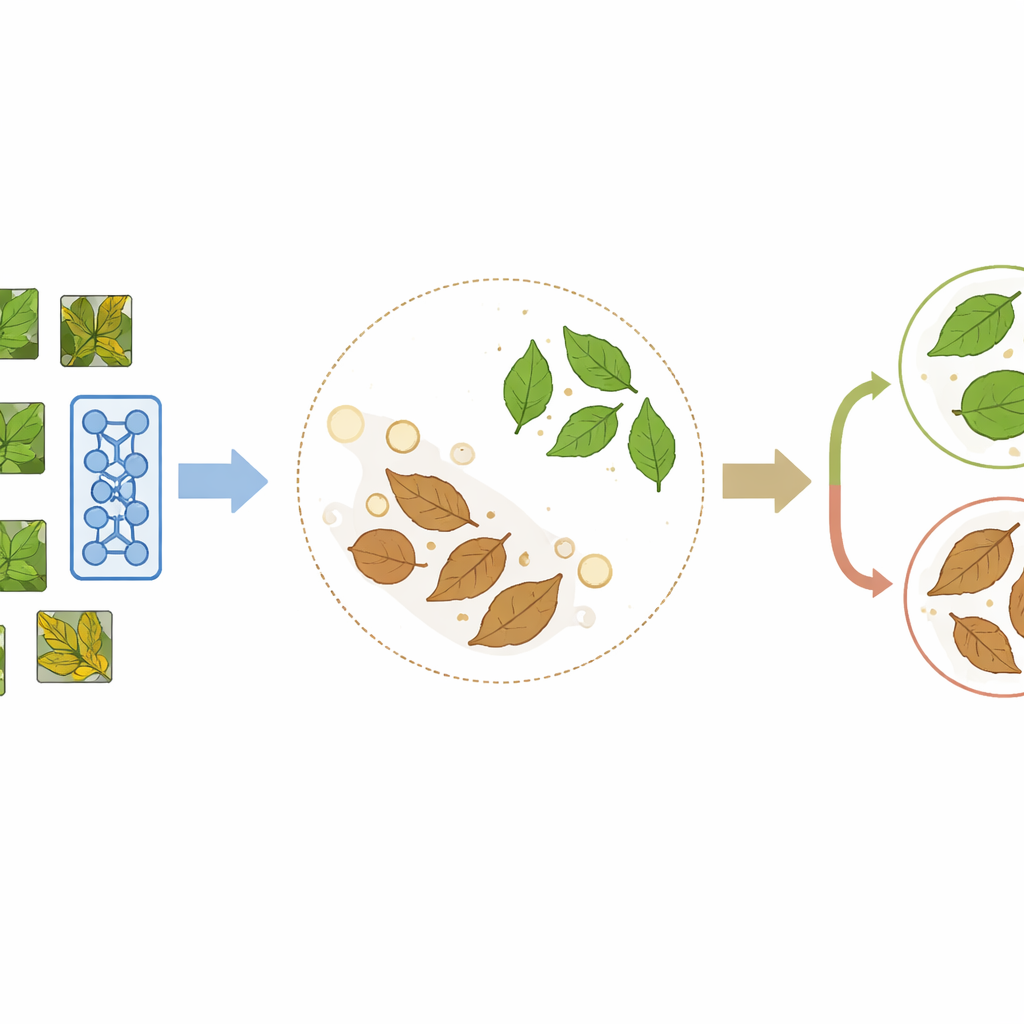
Mettere il sistema alla prova
Per verificare quanto bene funzioni questa strategia nella pratica, gli autori si sono rivolti a due dataset di foglie popolari che imitano ambienti reali molto diversi. Il dataset PlantVillage contiene più di 54.000 immagini di foglie fotografate in condizioni ordinate e controllate, solitamente con sfondi puliti e sintomi chiari, distribuite su 38 categorie di malattie e colture. Invece, il dataset Cassava Leaf Disease comprende circa 21.000 immagini di foglie di manioca scattate direttamente sul campo, con sfondi disordinati, illuminazione irregolare e foglie sovrapposte o contorte in molte direzioni, suddivise in cinque classi che includono diverse infezioni virali e batteriche gravi. Lo studio usa principalmente PlantVillage come ricca fonte di immagini non etichettate per il preaddestramento e poi valuta le prestazioni sia su quel dataset sia, in modo più critico, sulle foto di manioca in condizioni di campo più ostiche.
Prestazioni robuste attraverso condizioni variabili
PlantCLR ha raggiunto il 99,10% di accuratezza sul set di test PlantVillage e il 96,83% sul set di test Cassava, con punteggi F1 altrettanto elevati che mostrano come il modello funzioni bene anche su malattie meno comuni. Questi numeri superano una serie di reti deep note, inclusi DenseNet, ResNet, VGG e un modello vision transformer, tutti addestrati in modo puramente supervisionato sotto condizioni accuratamente corrispondenti. 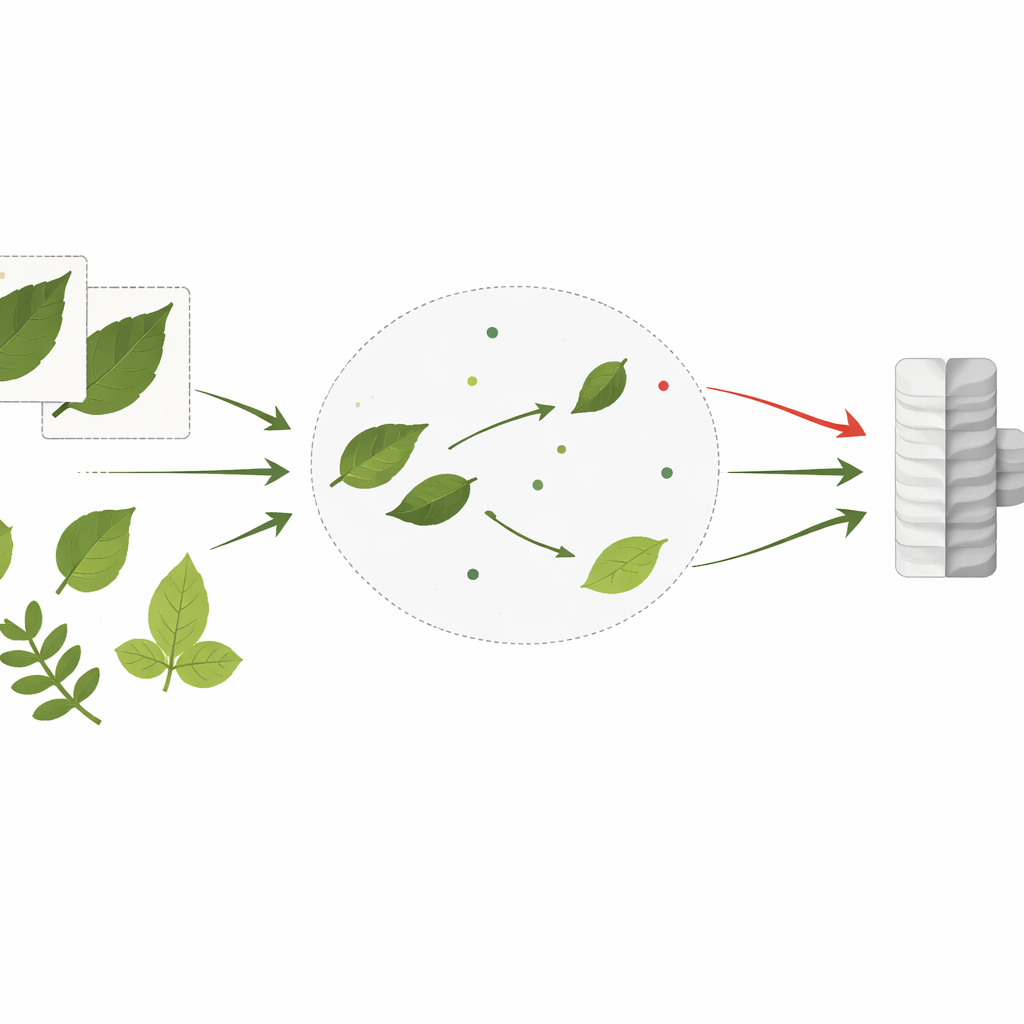
Perché questo approccio è un passo avanti
Per i non specialisti, il messaggio chiave è che PlantCLR dimostra come una macchina possa diventare un valido “medico delle piante” imparando prima da grandi raccolte di immagini non etichettate e poi affinando le proprie abilità con un set più piccolo e etichettato. Questa strategia non solo raggiunge elevate accuratezze, ma si mantiene solida quando la fotocamera passa dal laboratorio al campo, dove le condizioni sono molto meno ordinate. Poiché il modello sottostante è relativamente leggero, potrebbe infine essere distribuito su hardware accessibile, rendendo la diagnosi avanzata delle malattie più disponibile per agricoltori e tecnici di divulgazione in tutto il mondo. In breve, lo studio dimostra una strada pratica verso strumenti di monitoraggio della salute delle colture scalabili, robusti ed efficienti in termini di etichette, che potrebbero contribuire a proteggere le risorse alimentari.
Citazione: Shah, S.S.A., Saeed, F., Raza, M.U. et al. PlantCLR: contrastive self-supervised pretraining for generalizable plant disease detection. Sci Rep 16, 10550 (2026). https://doi.org/10.1038/s41598-026-45684-x
Parole chiave: rilevamento delle malattie delle piante, apprendimento auto-supervisionato, apprendimento contrastivo, IA agricola, monitoraggio della salute delle colture