Clear Sky Science · it
Rilevare la sostituzione di campioni nelle indagini anti-doping usando il machine learning
Perché è importante smascherare i furbi
Lo sport d’élite si basa sulla fiducia: quando un atleta vince, vogliamo credere che il risultato sia lecito. I test antidroga moderni sono molto sensibili, eppure alcuni atleti cercano di aggirarli scambiando di nascosto i campioni urinari. Questo studio mostra come il machine learning possa individuare quando un atleta riutilizza un proprio precedente campione “pulito”, un trucco estremamente difficile da scoprire con i controlli di routine attuali. Il lavoro indica nuove modalità per proteggere il fair play esaminando silenziosamente grandi banche dati di test alla ricerca di prove nascoste di manomissione.
Una falla nascosta nei test attuali
I laboratori anti-doping di solito analizzano le urine, perché molti farmaci vietati e i loro prodotti di degradazione rimangono rilevabili lì a lungo. I profili degli ormoni steroidei naturali degli atleti vengono monitorati per anni nel Passaporto Biologico dell’Atleta, perciò un salto improvviso in questi valori può avviare un’indagine. La sostituzione con l’urina di un’altra persona interrompe questo andamento a lungo termine ed è spesso rilevabile. Il vero punto cieco emerge quando un atleta riutilizza di nascosto la propria urina precedente, priva di sostanze. In quel caso il profilo degli steroidi si integra perfettamente nella sua storia, e se il campione viene analizzato in un laboratorio diverso o molto tempo dopo l’originale, attualmente non esiste un modo automatico per rilevare che due campioni sono essenzialmente uguali.
Trasformare la chimica delle urine in modelli ricercabili
Gli autori hanno affrontato il problema concentrandosi sulla dettagliata “impronta” costituita da un insieme di steroidi naturali e dai loro rapporti nelle urine. Hanno raccolto 67.651 profili di steroidi da un laboratorio accreditato dall’Agenzia Mondiale Antidoping (WADA) raccolti tra il 2021 e il 2023, coprendo sia atleti maschi sia femmine. Ogni profilo contiene ormoni chiave come il testosterone e diversi composti correlati, oltre ai rapporti tra di essi. Poiché i casi reali di riutilizzo del campione sono rari e riservati, il team ha combinato questi dati reali con coppie sintetiche accuratamente costruite: alcune coppie sono state rese “simili” aggiungendo un piccolo rumore di misura realistico, altre sono state rese “dissimili” accoppiando casualmente campioni di atleti diversi. Questo ha fornito materiale di addestramento bilanciato per un modello informatico affinché imparasse cosa significa nella pratica “quasi identico”.
Come funziona il rilevatore intelligente
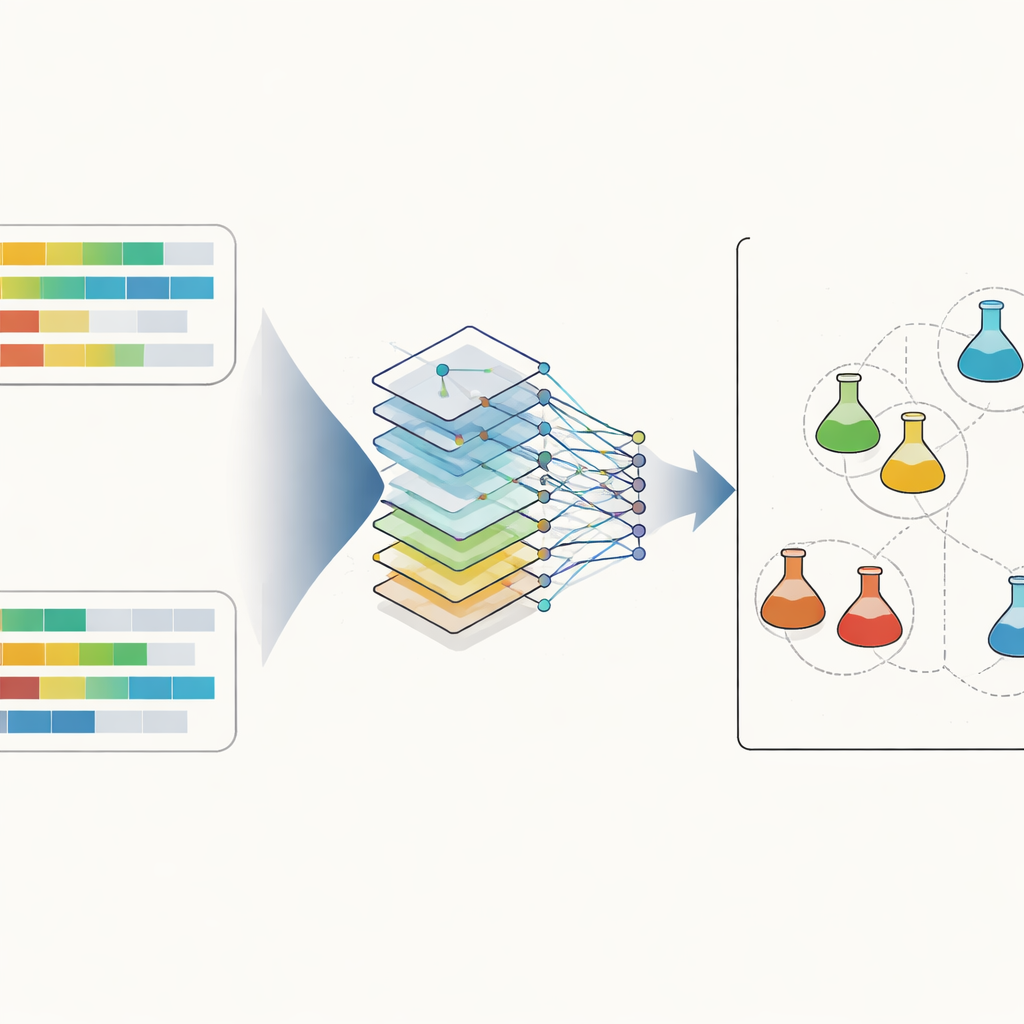
Il nucleo del sistema è un tipo di rete neurale artificiale nota come rete convoluzionale, ampiamente usata nel riconoscimento delle immagini. Qui, invece delle immagini, l’ingresso è una coppia di profili di steroidi disposti fianco a fianco. La rete scorre sulle caratteristiche per cogliere sottili relazioni locali, come il modo in cui due ormoni e il loro rapporto si muovono insieme. Per rendere i dati più gestibili e interpretabili, i ricercatori hanno anche utilizzato una tecnica chiamata analisi delle componenti principali per proiettare tutti i profili in uno spazio tridimensionale, dove semplici misure di distanza possono evidenziare corrispondenze strette. Durante l’addestramento, la rete impara a restituire la probabilità che due profili provengano dalla stessa urine sottostante, distinguendo la vera similarità dalle normali differenze biologiche osservate tra atleti e nel tempo.
Mettere il metodo alla prova
Il team ha valutato il proprio approccio su più fronti. Innanzitutto lo ha testato su dati tenuti fuori dall’addestramento per ciascun anno, usando profili non visti durante l’allenamento ma perturbati entro l’incertezza di misura prevista del 15%. La rete convoluzionale ha conseguito costantemente un’accuratezza molto alta, identificando correttamente le coppie simili mantenendo basse le falsi allarmi, e ha superato metodi più tradizionali come regressione logistica, macchine a vettori di supporto e modelli ad albero. Successivamente hanno sfidato il sistema con oltre 800 campioni di “conferma”—specimen urinari reali che i laboratori avevano rianalizzato con procedure leggermente diverse. Questi forniscono un sostituto realistico per campioni ripetuti o riutilizzati. Anche qui, la rete ha funzionato estremamente bene sia per uomini sia per donne, con ottima sensibilità (catturando le corrispondenze vere) e specificità (evitando quelle spurie), suggerendo che può gestire il vero rumore di laboratorio e la variazione biologica.
Cosa significa per lo sport pulito
Per i non specialisti, la conclusione principale è che ora sta diventando fattibile esaminare automaticamente vaste banche dati anti-doping alla ricerca di segnali che un campione di urine apparentemente nuovo sia, in realtà, una copia quasi perfetta di uno più vecchio. Il quadro di machine learning proposto non sostituisce i test esistenti per sostanze vietate; invece aggiunge un potente controllo di background che può segnalare campioni sospettosamente simili per un esame forense più approfondito. Sebbene il metodo dipenda in parte da dati simulati e utilizzi modelli complessi “a scatola nera” non completamente trasparenti, offre tuttavia alle autorità sportive uno strumento pratico. Se integrato nei sistemi attuali del Passaporto Biologico dell’Atleta, potrebbe rendere il trucco una volta indetectabile del riutilizzo di urine pulite molto più rischioso, rafforzando la fiducia che le medaglie siano guadagnate sul merito piuttosto che sulla manipolazione.
Citazione: Rahman, M.R., Piper, T., Thevis, M. et al. Detection of sample swapping in anti-doping investigations using machine learning. Sci Rep 16, 9230 (2026). https://doi.org/10.1038/s41598-026-43502-y
Parole chiave: anti-doping, profili urinari di steroidi, sostituzione di campioni, machine learning, integrità sportiva