Clear Sky Science · it
Ripensare l'engineering del contesto usando un'architettura basata sull'attenzione
Perché gli assistenti software più intelligenti sono importanti
Ogni clic che fai in un'app aziendale—accesso, caricamento di un file, esecuzione di un report—lascia una traccia. Se il software potesse prevedere con affidabilità la tua mossa successiva, potrebbe precaricare dati, suggerire scorciatoie e rispondere quasi istantaneamente. Questo articolo esplora un nuovo modo di insegnare ai computer a comprendere così bene queste sequenze di azioni che gli assistenti digitali possono anticipare cosa farai dopo, quale obiettivo stai cercando di raggiungere e quando sei sul punto di disconnetterti.
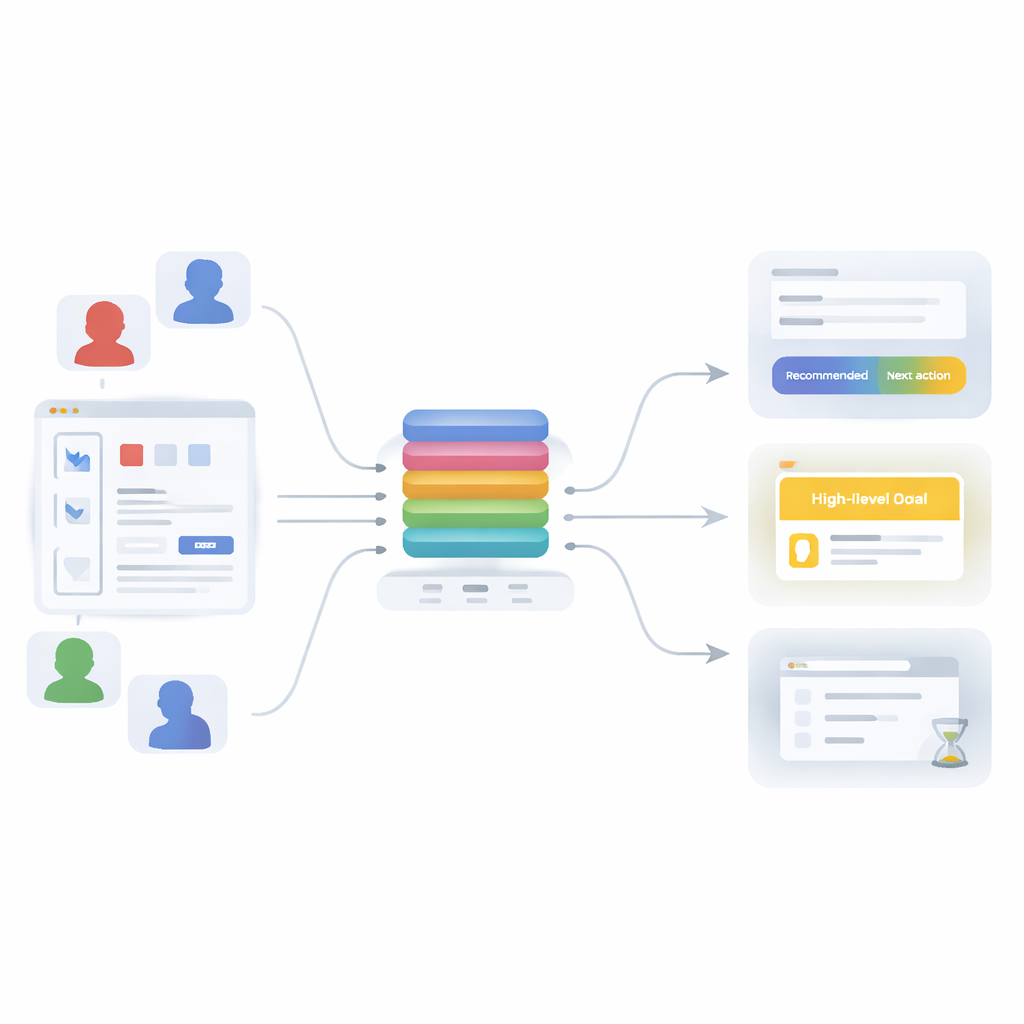
Dalle catene semplici a pattern ricchi
Molti sistemi esistenti che indovinano il passo successivo di un utente si basano su catene di Markov, uno strumento matematico classico che considera solo l'azione più recente per prevedere la successiva. Pur essendo veloci e pratiche, queste strategie a “memoria di un passo” falliscono nei contesti lavorativi reali, dove compiti come costruire una pipeline di machine learning o preparare una dashboard si sviluppano su molti passaggi e coinvolgono strumenti diversi. Gli autori sostengono che modelli così semplici perdono le strutture a lungo raggio, possono gestire un solo obiettivo di predizione alla volta e sono difficili da confrontare tra studi perché spesso dipendono da log privati e scelte opache di pulizia dei dati.
Un nuovo progetto di apprendimento multi-task
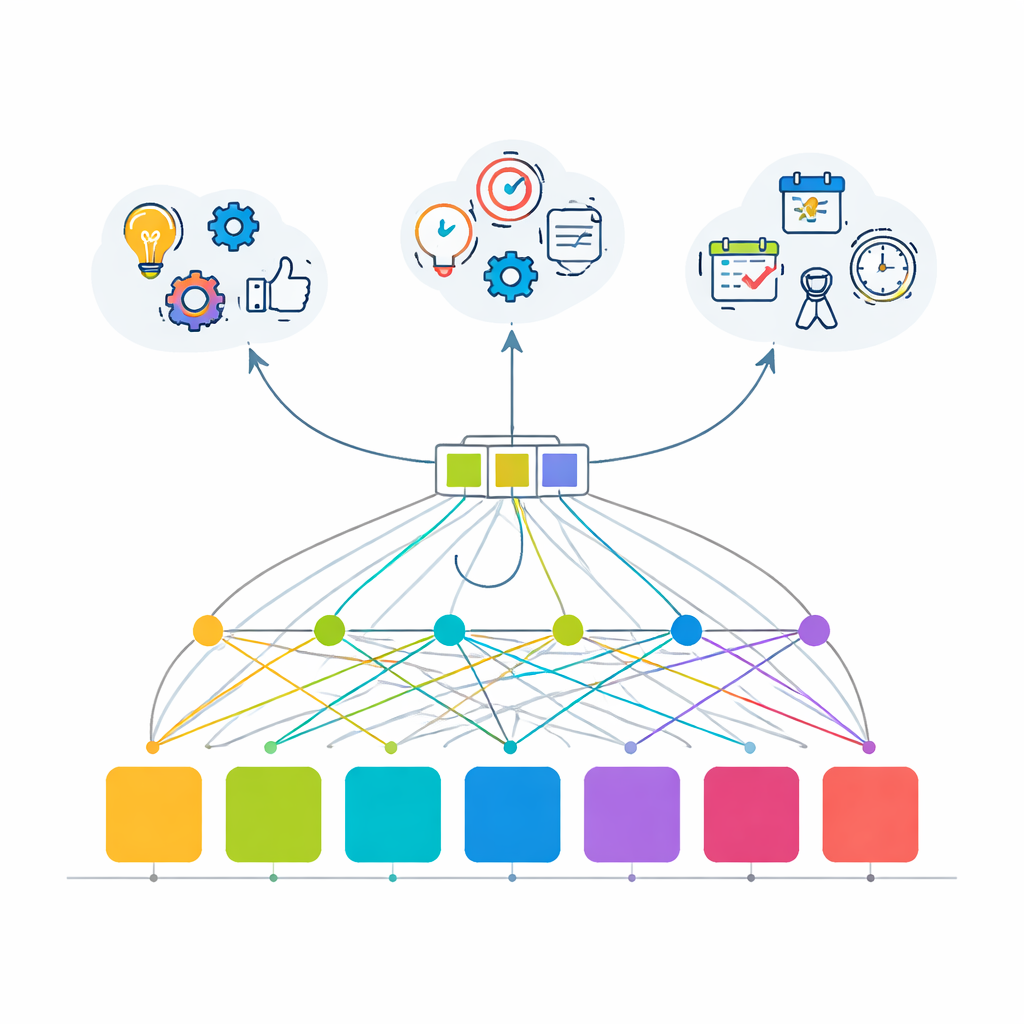
Per superare questi limiti, l'articolo introduce un modello trasformatore basato sull'attenzione—la stessa famiglia di tecniche alla base degli strumenti linguistici moderni—reimmaginato per il comportamento degli utenti. Invece di imparare una sola cosa, il modello è addestrato a risolvere tre compiti correlati contemporaneamente: prevedere l'azione successiva (quale API chiamerà un utente), inferire l'obiettivo complessivo della sessione (ad esempio eseguire una pipeline di machine learning, fare analisi dei dati, gestire utenti o creare visualizzazioni rapide) e decidere se l'attuale passaggio è probabilmente l'ultimo della sessione. Tutti e tre i compiti condividono un “backbone” comune che trasforma una breve cronologia di azioni recenti in una singola, ricca rappresentazione di ciò che sta accadendo, poi inviata a tre piccoli moduli di predizione.
Costruire un banco di prova realistico in silico
Poiché i registri di attività aziendali reali sono spesso sensibili e difficili da condividere, gli autori costruiscono un ambiente simulato sofisticato che imita come i professionisti dei dati usano una grande piattaforma interna. Definiscono 100 API distinte raggruppate in 10 aree funzionali, tra cui autenticazione, input dei dati, elaborazione, addestramento dei modelli, visualizzazione, esportazione e amministrazione. Quattro profili utente—data scientist, analisti aziendali, sviluppatori e power user—seguono flussi di lavoro caratteristici ma imperfetti, con probabilità che riflettono sia comportamenti di routine sia deviazioni occasionali. Il dataset risultante contiene 2.000 sessioni utente e 20.000 chiamate API, con obiettivi di sessione come “pipeline di machine learning” e “visualizzazione rapida” che producono percorsi riconoscibili come accesso, caricamento dei dati, elaborazione, creazione di un grafico ed esportazione del risultato.
Quanto bene il modello impara ad anticipare
Addestrato su questo ambiente strutturato ma vario, il modello trasformatore dimostra che l'apprendimento basato sull'attenzione può catturare le regolarità nascoste nel comportamento degli utenti molto meglio dei metodi più vecchi. Per il compito principale—indovinare la chiamata API immediatamente successiva tra 100 scelte—ottiene la risposta esatta quasi l'80% delle volte e pone la scelta corretta tra le sue prime cinque proposte più del 99,9% delle volte, un salto di oltre quattro volte rispetto a una catena di Markov di base. Allo stesso tempo, identifica correttamente l'obiettivo complessivo della sessione in circa l'82% dei casi e rileva quasi perfettamente quando una sessione sta per terminare. Gli autori sottolineano inoltre che il modello è relativamente compatto ed efficiente, rendendo possibile l'uso in tempo reale per assistenti live che devono rispondere senza ritardi percepibili.
Strumenti da riutilizzare ed estendere
Per rendere il loro approccio più di un esperimento isolato, gli autori rilasciano un pacchetto software open-source, chiamato context-engineer, insieme all'intero dataset simulato. Con queste risorse, altri ricercatori e professionisti possono riprodurre i risultati riportati, testare modelli alternativi su un benchmark condiviso o collegare i propri log interni mappando azioni e etichette di sessione in un formato numerico semplice. Questa apertura affronta un ostacolo importante nel campo, dove molti sistemi passati non potevano essere confrontati o riutilizzati in modo equo perché i loro dati e codici non erano disponibili.
Cosa significa per gli utenti di tutti i giorni
Per un non specialista, la conclusione principale è che l'articolo offre una ricetta pratica per far sembrare gli strumenti digitali più “un passo avanti”. Imparando congiuntamente cosa le persone stanno cercando di fare, cosa è probabile che clicchino dopo e quando stanno per concludere, il sistema proposto basato su trasformatore trasforma le cronologie degli utenti in una forma di consapevolezza del contesto. Nelle applicazioni reali, questo potrebbe significare chatbot che preparano il report successivo prima che lo chiedi, piattaforme di analytics che suggeriscono azioni di follow-up sensate e dashboard aziendali che riducono silenziosamente i tempi di attesa. Sebbene lo studio attuale sia basato su dati simulati e richieda test su log reali, pone una base chiara e riproducibile per costruire assistenti software più intelligenti e anticipatori su molti tipi di piattaforme digitali.
Citazione: Yin, Y. Rethink context engineering using an attention-based architecture. Sci Rep 16, 8851 (2026). https://doi.org/10.1038/s41598-026-43111-9
Parole chiave: predizione del comportamento dell'utente, raccomandazione sequenziale, trasformatore basato sull'attenzione, assistenti digitali proattivi, ingegneria del contesto