Clear Sky Science · it
Affrontare il problema dello squilibrio dei dati nella modellizzazione con machine learning di eventi di interruzione rari e dirompenti
Perché previsioni meteorologiche migliori contano per te
Quando una grande tempesta provoca un’interruzione di corrente, lo viviamo in modo molto personale: luci spente, riscaldamento assente, cibo che si rovina e comunicazioni interrotte. Le utility cercano di prevedere questi blackout in anticipo per poter schierare le squadre di riparazione e proteggere le persone. Ma le tempeste più gravi sono rare, il che significa che esistono sorprendentemente pochi dati su di esse. Questo articolo mostra come un nuovo tipo di intelligenza artificiale possa “immaginare” tempeste rare realistiche, colmando le lacune nei nostri archivi e rendendo le previsioni dei blackout più accurate proprio quando è più importante.
La sfida di apprendere dai disastri rari
La maggior parte dei blackout è causata dal tempo, in particolare uragani, Nor’easter, tempeste di neve e ghiaccio e temporali violenti. Questi eventi stanno diventando più intensi con il riscaldamento climatico, esercitando uno stress aggiuntivo sulle reti elettriche invecchiate. Eppure le tempeste più dannose sono, per definizione, poco frequenti. Gli strumenti statistici tradizionali e i modelli di machine learning tendono ad apprendere meglio dalle molte tempeste lievi e moderate, e fanno fatica con la manciata di casi veramente estremi. Questo squilibrio nei dati porta a sottostime dei danni proprio quando le utility hanno più bisogno di indicazioni affidabili.
Insegnare ai computer a creare nuove tempeste
Per superare questo squilibrio, gli autori costruiscono un sistema che genera tempeste sintetiche — ovvero eventi creati al computer che assomigliano e si comportano come tempeste reali ma non sono copie di un singolo evento passato. Si concentrano sul Connecticut, rappresentando ogni tempesta come una griglia di 815 celle con 19 tipi di informazioni per cella, inclusi vento, pioggia, pressione, turbolenza, vegetazione e disposizione delle linee elettriche. Innanzitutto raggruppano 294 tempeste storiche in 12 cluster sulla base di quanto e dove si sono verificati i “punti critici” — luoghi danneggiati che le squadre devono riparare. Le tempeste rare e ad alto impatto finiscono in quattro piccoli cluster che necessitano di potenziamento.
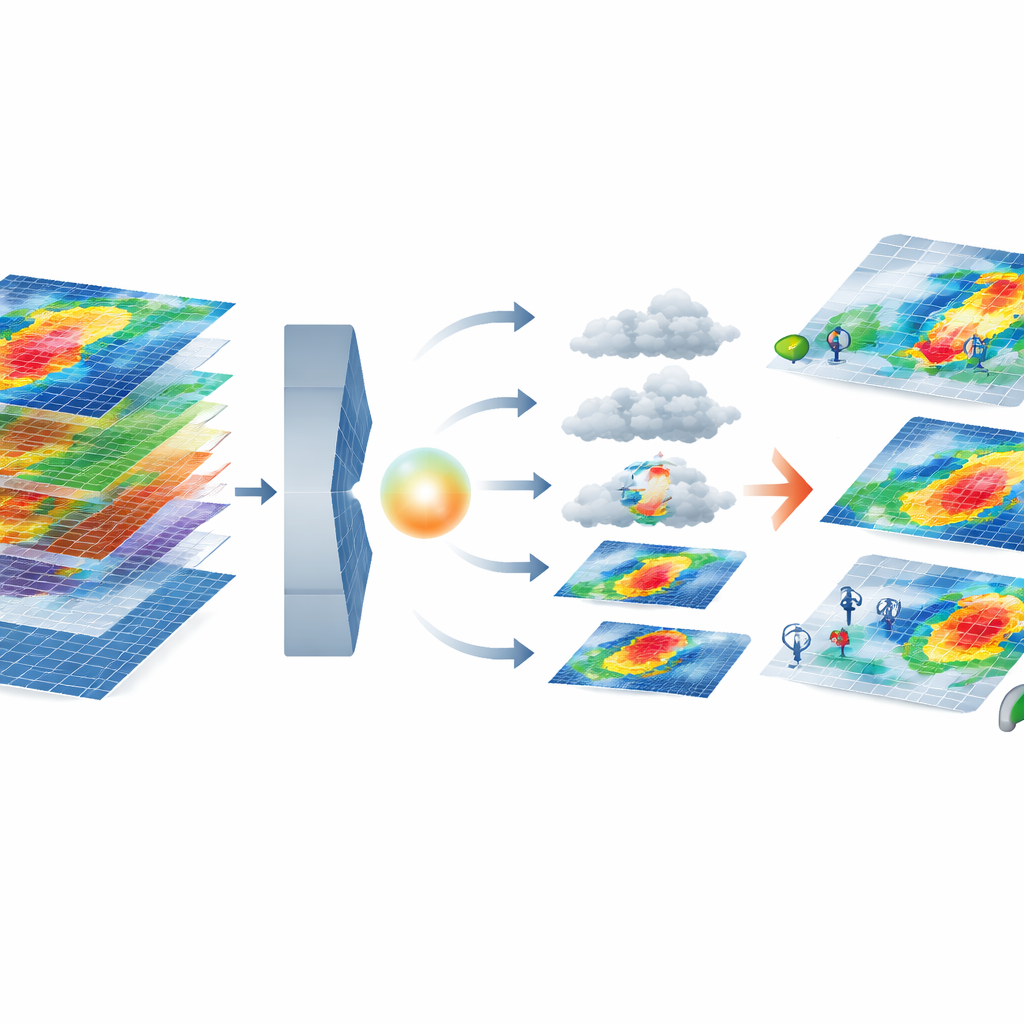
Come il nuovo modello AI costruisce gli estremi realistici
Il nucleo del framework combina due strumenti AI moderni. Un autoencoder variazionale comprime ogni mappa multi-livello della tempesta in una rappresentazione “latente” a dimensione ridotta che preserva ancora pattern importanti, come venti più forti vicino alla costa. In questo spazio compresso, un modello di diffusione impara a partire dal rumore casuale e a raffinarlo gradualmente in una tempesta realistica, condizionata sul cluster di gravità degli blackout richiesto. Il sistema poi seleziona le tempeste generate usando una serie di metriche che confrontano le loro statistiche con quelle degli eventi reali — verificando non solo caratteristiche individuali come la velocità del vento ma anche come le caratteristiche si muovono insieme, come catturato dai pattern di correlazione. Vengono conservate solo le tempeste sintetiche che corrispondono strettamente al comportamento fisico e statistico delle tempeste reali in un dato cluster.
Mettere alla prova le tempeste sintetiche
Gli autori pongono quindi la domanda cruciale: queste tempeste sintetiche aiutano davvero a prevedere i blackout? Allenano un modello esistente di predizione dei blackout due volte — prima solo sui dati reali e poi sugli stessi dati arricchiti con eventi sintetici accuratamente selezionati per i cluster rari e ad alto impatto. Valutano le prestazioni usando un rigoroso test leave-one-storm-out, che imita la previsione di eventi nuovi e non visti. Con l’arricchimento sintetico, l’errore strutturale del modello diminuisce nettamente e l’adattamento complessivo migliora. Per le tempeste rare e più dirompenti, l’errore quadratico medio centrale scende di circa il 45% e misure riassuntive di abilità, come l’efficienza di Nash–Sutcliffe, passano da livelli peggiori del basale a prestazioni chiaramente utili. Un confronto con un’“aumento” casuale, che aggiunge tempeste sintetiche senza un controllo di qualità, mostra guadagni molto più piccoli o addirittura negativi, sottolineando l’importanza di un filtraggio rigoroso.
Cosa significa per le tempeste future
In termini chiari, questo studio mostra che lasciare che l’IA inventi tempeste estreme fisicamente coerenti — e essere selettivi su quali tempeste inventate si ritengono affidabili — può rendere le previsioni dei blackout più attendibili per gli eventi che causano i danni maggiori. Arricchendo i dati scarsi su fenomeni rari ma devastanti, l’approccio aiuta le utility a prevedere meglio quanti luoghi danneggiati dovranno affrontare e dove. Sebbene dimostrato per uno stato e un tipo di pericolo, la stessa strategia potrebbe essere estesa a incendi boschivi, alluvioni e altre minacce naturali, offrendo un nuovo modo per rafforzare la pianificazione infrastrutturale in un mondo di estremi climatici crescenti.
Citazione: Azizi, M., Zhang, X., Yasenpoor, T. et al. Addressing the data imbalance issue in machine learning modeling of rare and disruptive outage events. Sci Rep 16, 8876 (2026). https://doi.org/10.1038/s41598-026-41838-z
Parole chiave: dati sintetici sulle tempeste, predizione dei blackout, modelli di diffusione, fenomeni meteorologici estremi, sbilanciamento dei dati