Clear Sky Science · it
Modellizzazione ibrida basata su conoscenza e dati per un rilevamento e una classificazione dei potenziali d’azione robusti nella microneurografia delle fibre C umane
Ascoltare i nervi del dolore e del prurito
Le nostre esperienze quotidiane di dolore e prurito iniziano come minuscoli impulsi elettrici che corrono lungo sottili fibre nervose nella pelle. I ricercatori possono intercettare questi segnali in volontari svegli usando una tecnica chiamata microneurografia, inserendo un elettrodo sottile come un capello in un nervo. Ma in queste registrazioni molte fibre nervose parlano contemporaneamente e le loro “voci” elettriche suonano quasi identiche. Questo articolo presenta un nuovo metodo informatico per separare e identificare meglio questi segnali sovrapposti, con l’obiettivo a lungo termine di decodificare come i nervi umani rappresentano sensazioni come dolore e prurito.
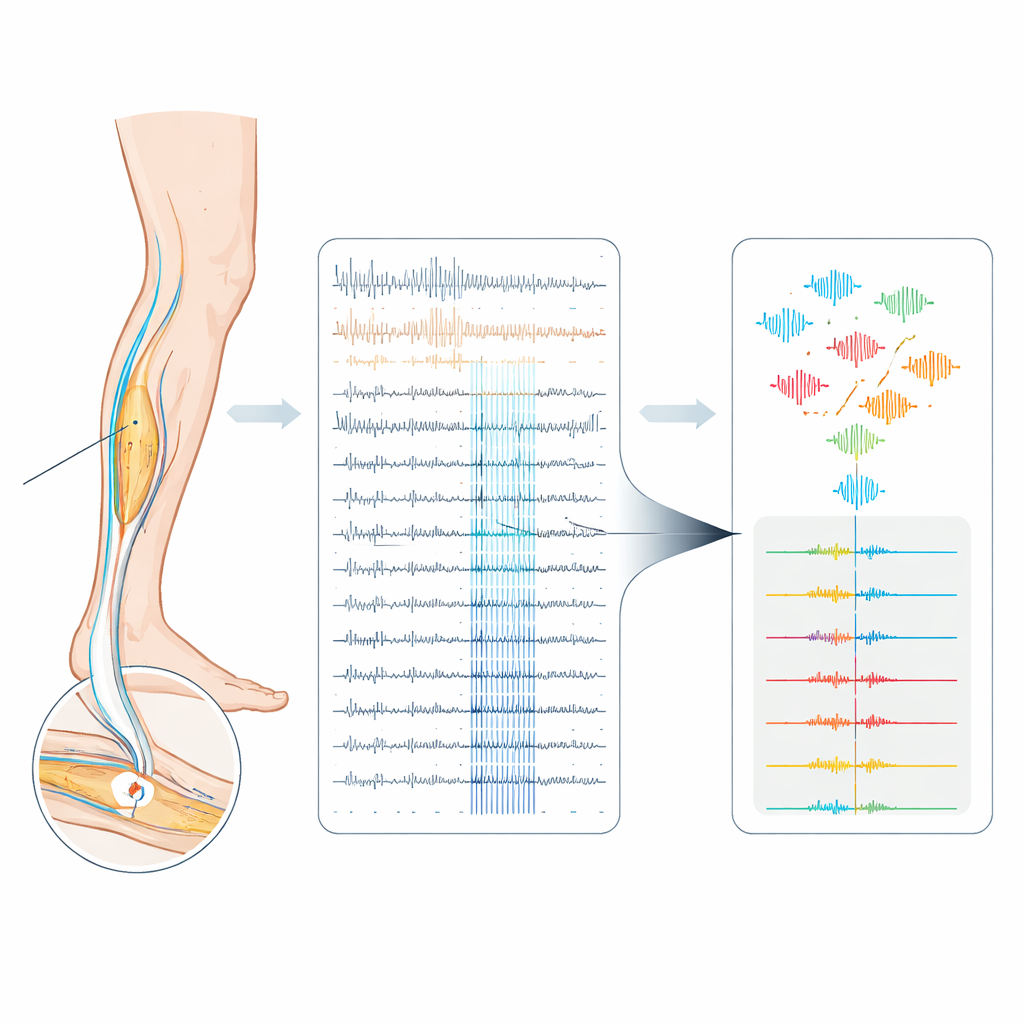
Perché gli spike nervosi sono così difficili da distinguere
Ogni fibra sensoriale comunica con il cervello tramite brevi scariche elettriche chiamate spike. Non solo il numero di spike, ma anche il loro preciso timing e il loro pattern possono modificare la percezione di uno stimolo. Sfortunatamente, nei nervi periferici umani gli spike registrati da fibre diverse spesso appaiono quasi identici e sono sepolti nel rumore. Un singolo elettrodo metallico di solito coglie diverse fibre contemporaneamente e la forma degli spike può cambiare lentamente durante esperimenti prolungati. I metodi automatici esistenti per separare gli spike sono stati progettati principalmente per array con molti elettrodi, dove l’informazione spaziale aiuta. Applicati a registrazioni con un solo elettrodo dalle fibre C umane — fibre non mielinizzate cruciali per dolore e prurito — questi metodi tendono a essere inaffidabili.
Usare il timing proprio del nervo come guida
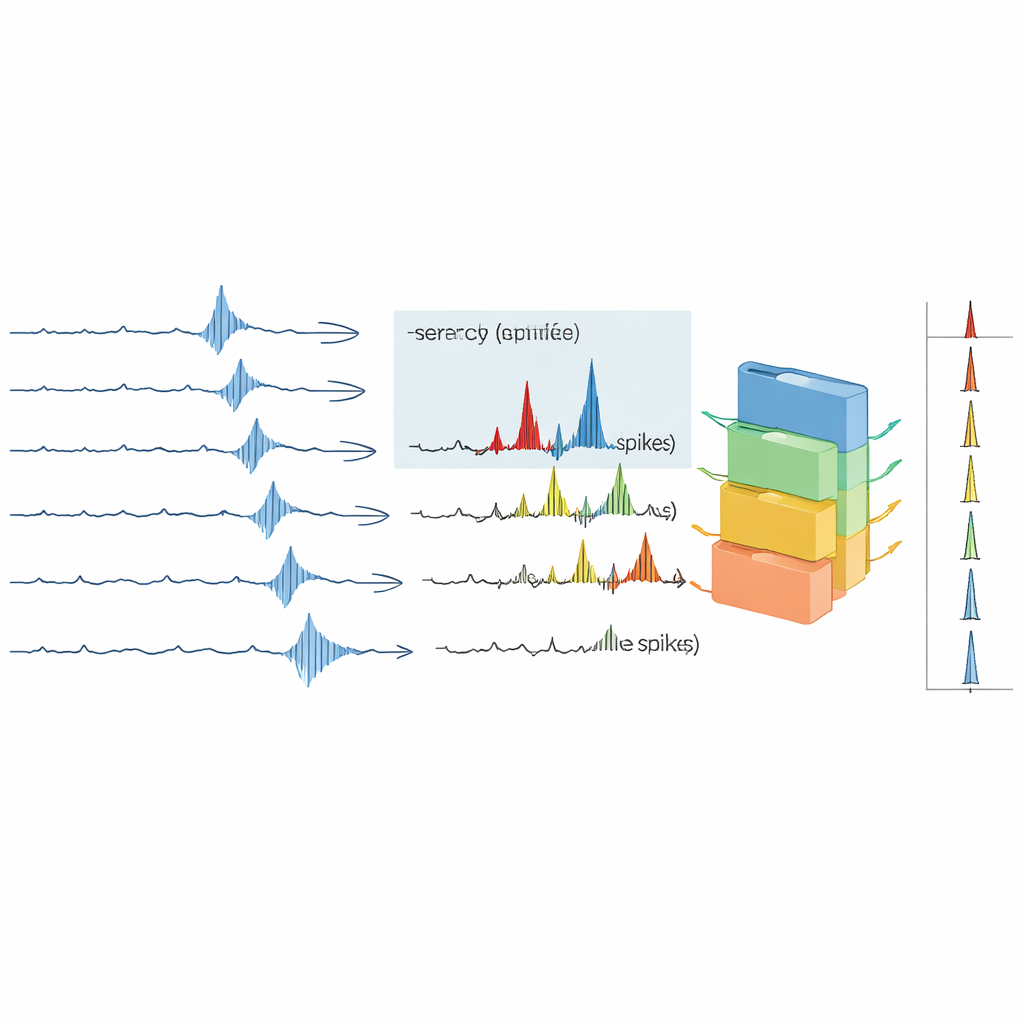
Gli autori si basano su un trucco già usato in microneurografia chiamato “metodo di marcatura”. Durante un esperimento, la pelle viene stimolata con impulsi elettrici delicati a bassa e costante frequenza. Ogni impulso provoca in modo affidabile uno spike da ciascuna fibra C attivata dopo un ritardo fisso, così le risposte ripetute della stessa fibra formano una “traccia” verticale quando i dati sono tracciati prova dopo prova. Se una fibra ha sparato spike extra poco prima dell’impulso successivo, la sua conduzione rallenta leggermente e la risposta successiva arriva in ritardo. Questo ritardo, noto come rallentamento dipendente dall’attività, funge da impronta digitale dell’attività recente di quella singola fibra. Il nuovo lavoro estende questa idea riprogettando il protocollo di stimolazione in modo che non solo gli impulsi di fondo regolari, ma anche impulsi extra inseriti tra di essi, siano trattati come ancore temporali. Di conseguenza, tutti gli spike evocati elettricamente nella registrazione diventano precisamente sincronizzati e etichettati, creando un raro dataset di “ground truth” in un nervo umano rumoroso.
Un percorso ibrido dal rumore grezzo alle serie di spike pulite
Dotati di questo ground truth, il gruppo costruisce una pipeline di analisi semi-automatica che miscela conoscenza esperta e apprendimento automatico. Nella fase guidata dalla conoscenza, calcolano prima template medi degli spike per tutte le tracce visibili e scelgono la fibra con lo spike più grande e più pulito come target principale. Misurano il ritardo tipico delle risposte di quella fibra e cercano intervalli in cui il ritardo si allunga, segnalando attività extra. La rilevazione degli spike viene quindi limitata a questi intervalli, riducendo molto lo spazio di ricerca e diminuendo i falsi allarmi. Nella fase guidata dai dati, ogni forma d’onda rilevata viene convertita in caratteristiche numeriche — o descrittori compatti o il frammento grezzo di voltaggio di 3 millisecondi — e fornita a diversi classificatori, inclusi support vector machines e un noto metodo a boosting di alberi chiamato XGBoost. I modelli sono addestrati sugli spike affidabilmente etichettati dal protocollo di ground truth e ottimizzati con cross‑validation per trovare la migliore combinazione modello‑caratteristiche per ciascuna registrazione.
Quanto bene funziona il nuovo approccio
Gli autori testano la pipeline su sei registrazioni impegnative da volontari umani, con qualità del segnale e numero di fibre attive variabili. Confrontano i loro risultati con Spike2, un programma commerciale molto usato che si basa sul matching dei template. Tra i dataset, nessuna singola ricetta di machine learning vince sempre, ma XGBoost con forme d’onda grezze tende a fornire la migliore performance mediana. Le registrazioni con rapporto segnale‑rumore più alto e meno fibre si classificano meglio, mentre un dataset particolarmente rumoroso con forme d’onda molto simili rimane sostanzialmente non separabile. Nel complesso, la nuova pipeline raggiunge punteggi F1 più elevati e un numero nettamente inferiore di falsi positivi rispetto a Spike2, specialmente quando l’attenzione è limitata agli intervalli temporali in cui gli spostamenti di latenza fisiologica indicano attività reale. In un esempio realistico in cui una sostanza che provoca prurito è iniettata nella pelle, la pipeline e Spike2 concordano in larga misura su quali spike provengono dalla fibra d’interesse, ma il nuovo metodo evita molti spike extra dubbi con tassi di scarica implausibilmente elevati.
Cosa significa questo per la comprensione del dolore e del prurito
Per chi non è specialista, il messaggio chiave è che lo studio fornisce un modo più affidabile per ascoltare singole fibre nervose nell’uomo, anche quando i loro segnali sono piccoli, rumorosi e sovrapposti. Combinando comportamenti fisiologici noti — come gli spike si allineano nel tempo e come i loro ritardi cambiano con l’attività recente — con l’apprendimento automatico moderno, gli autori possono decidere meglio quali spike appartengono veramente a una data fibra e quali no. Questa migliore classificazione è un passo necessario prima che i ricercatori possano interpretare in sicurezza pattern dettagliati di spike come codici per dolore, prurito o altre sensazioni. Sebbene alcune registrazioni rimangano troppo disordinate per essere analizzate, la pipeline offre criteri chiari per giudicare quando i dati sono utilizzabili e getta le basi per studi futuri che mirano a decodificare segnali di dolore spontaneo nelle neuropatie e a personalizzare i trattamenti in base al modo in cui singole fibre nervose umane sparano.
Citazione: Troglio, A., Fiebig, A., Maxion, A. et al. Hybrid knowledge- and data-driven modelling for robust spike detection and sorting in human C-fiber microneurography. Sci Rep 16, 8975 (2026). https://doi.org/10.1038/s41598-026-41561-9
Parole chiave: microneurografia, fibre C, spike sorting, dolore e prurito, apprendimento automatico