Clear Sky Science · it
Rilevazione precoce della malattia renale cronica basata su un modello di apprendimento automatico potenziato da SURD
Perché è importante individuare precocemente i problemi renali
La malattia renale cronica spesso avanza silenziosa, mostrando pochi segnali d’allarme finché i reni non sono gravemente compromessi. Tuttavia semplici esami del sangue e delle urine possono evidenziare problemi anni prima, quando il trattamento può rallentare o persino prevenire un peggioramento serio. Questo studio esplora un nuovo modo di analizzare quei risultati routinari usando modelli computazionali avanzati ma interpretabili, in modo da segnalare prima le persone ad alto rischio e permettere ai medici di capire perché.
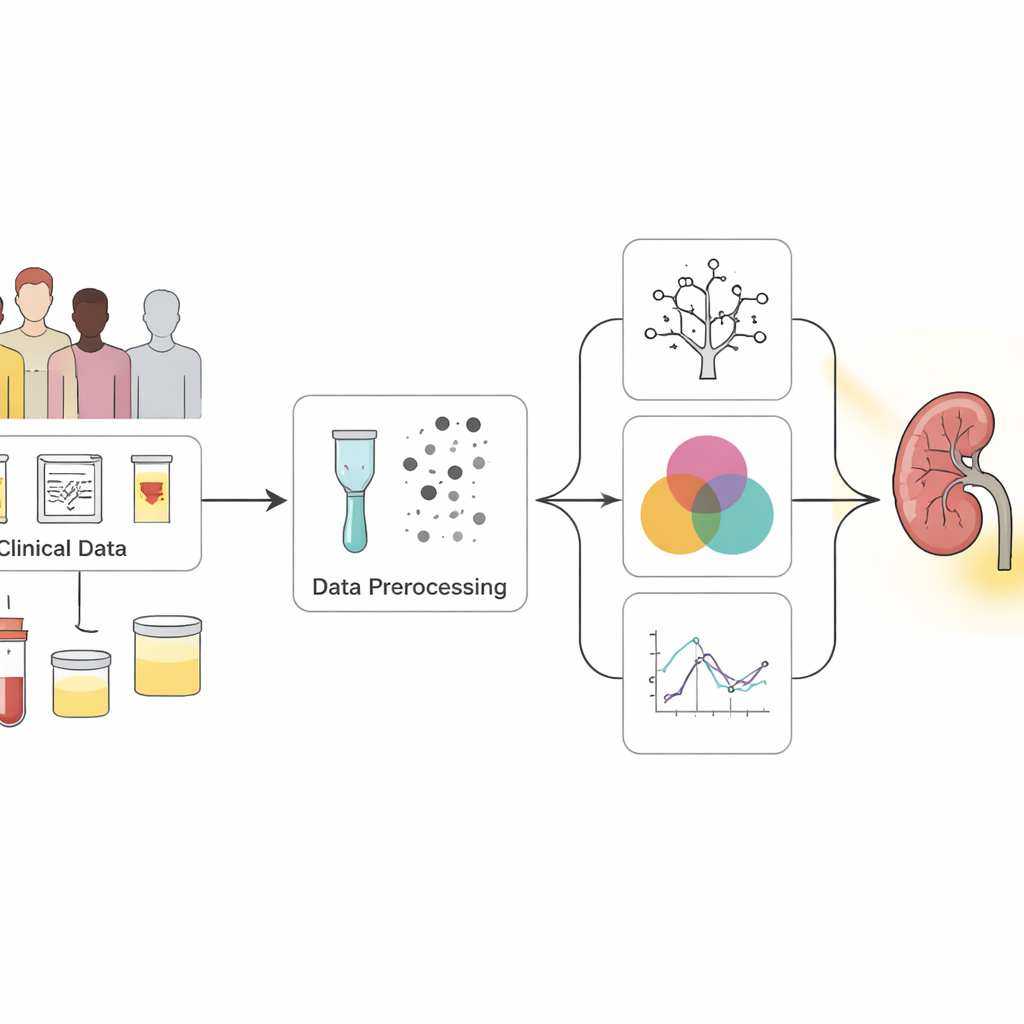
Trasformare dati di controllo disomogenei in segnali chiari
I ricercatori hanno iniziato con un dataset pubblico ampiamente utilizzato di 400 persone, la maggior parte delle quali era già stata diagnosticata con malattia renale cronica. Ogni individuo aveva 25 misurazioni, che andavano dalla pressione sanguigna e gli esami del sangue ai riscontri delle urine e alla storia clinica come diabete e ipertensione. Molte voci erano incomplete, quindi il team ha impiegato tecniche statistiche attente per imputare i valori mancanti invece di scartare semplicemente i pazienti. Hanno inoltre bilanciato i dati in modo che i casi sani e malati fossero rappresentati in modo più uniforme, aiutando i modelli computazionali ad apprendere a riconoscere entrambi i gruppi in modo equo.
Guardare oltre le semplici correlazioni
La maggior parte degli strumenti di predizione medica tratta ogni risultato di test separatamente: valuta quanto un singolo valore, come la glicemia, sia legato alla malattia. Ma nell’organismo i fattori di rischio raramente agiscono da soli. Alcuni esami forniscono informazioni quasi identiche, mentre altri diventano informativi solo in combinazione. Per cogliere questo, gli autori hanno usato un quadro chiamato SURD che scompone il contributo di ciascuna caratteristica in tre parti: informazioni condivise con altri test, informazioni uniche e informazioni che emergono solo quando le caratteristiche agiscono insieme. Questo ha permesso loro di raggruppare i valori di laboratorio e i riscontri clinici in insiemi “unici”, “ridondanti” e “sinergici” prima di inserirli nei modelli predittivi.
Addestrare molti modelli e scegliere il più affidabile
Con questi gruppi di caratteristiche basati su SURD, il team ha addestrato dieci diversi modelli di machine learning, da semplici alberi decisionali ad approcci più complessi come foreste casuali e reti neurali. Hanno confrontato le prestazioni quando i modelli usavano tutte le caratteristiche disponibili rispetto a quando utilizzavano solo un insieme combinato di caratteristiche uniche e sinergiche. In quasi tutti i tipi di modello, questo insieme ridotto guidato da SURD ha mostrato prestazioni uguali o superiori rispetto alla collezione completa di 25 variabili, migliorando spesso l’equilibrio tra l’identificazione corretta dei pazienti malati ed evitare falsi allarmi. In particolare, i modelli basati su alberi come le foreste casuali e gli alberi potenziati hanno raggiunto punteggi quasi perfetti sul dataset originale.
Testare il metodo su dati ospedalieri del mondo reale
Una performance eccellente su un piccolo dataset di riferimento può essere fuorviante se un modello fallisce quando è esposto a pazienti più variegati. Per tutelarsi da questo, gli autori hanno validato il loro approccio usando un database ospedaliero molto più ampio di oltre 27.000 pazienti di terapia intensiva. Qui, il modello random forest costruito sulle caratteristiche selezionate da SURD ha comunque distinto i pazienti con e senza malattia renale con precisione estremamente elevata. Le sue prestazioni hanno chiaramente superato quelle di un albero decisionale più semplice, indicando che il metodo può generalizzare oltre un dataset di ricerca accuratamente curato fino a cartelle cliniche del mondo reale più disordinate.
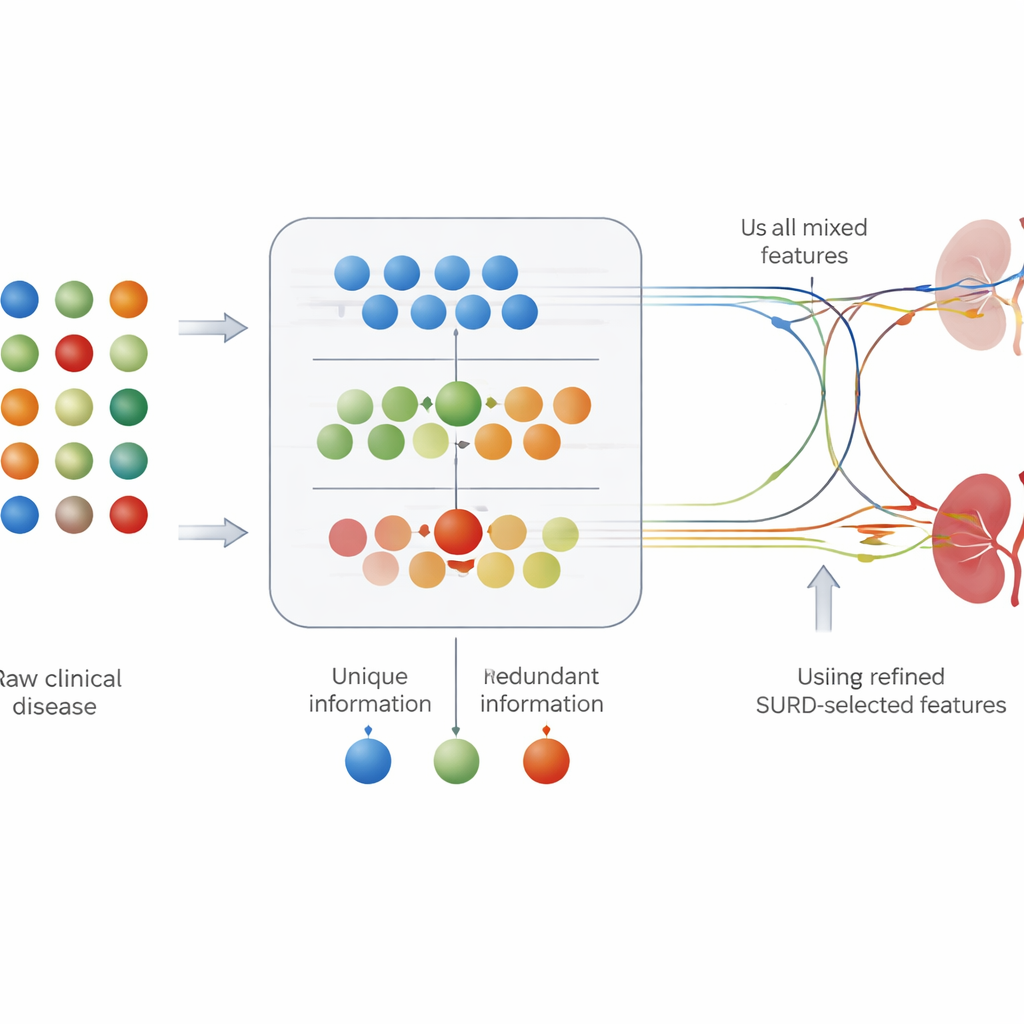
Vedere quali esami contano e in che modo
La sola accuratezza non è sufficiente per l’uso clinico; i medici devono anche sapere quali risultati di esami stanno guidando una predizione. Lo studio ha combinato SURD con strumenti moderni di spiegazione che assegnano a ciascuna caratteristica un contributo alla decisione del modello per un dato paziente. Questa analisi ha evidenziato marcatori di rischio familiari, come la creatinina sierica (un indicatore diretto della funzione renale), i livelli di emoglobina, la concentrazione delle urine e la presenza di diabete o ipertensione. Interessantemente, SURD ha mostrato che alcuni di questi fattori agiscono per lo più in concerto con altri, mentre la creatinina si distingue come segnale fortemente informativo da solo. Insieme, queste tecniche offrono sia una visione globale di quali test il modello utilizza sia ripartizioni a livello di singolo paziente del perché una persona è prevista a rischio elevato.
Cosa significa per la cura quotidiana
In termini semplici, lo studio mostra che è possibile costruire un calcolatore del rischio di malattia renale che sia sia altamente accurato sia ragionevolmente trasparente. Separando le informazioni sovrapposte da quelle davvero uniche nei dati di laboratorio e anamnestici di routine, i modelli guidati da SURD producono predizioni più nette senza diventare una scatola nera misteriosa. Sebbene sia necessario ulteriore lavoro su gruppi di pazienti più ampi e diversificati, questo approccio potrebbe alla fine aiutare i clinici a individuare prima i problemi renali, concentrare l’attenzione sugli esami più informativi e spiegare ai pazienti in termini chiari quali aspetti della loro salute mettono a rischio i reni.
Citazione: Xue, N., Bai, T., Jia, X. et al. Early detection of chronic kidney disease based on a SURD-enhanced machine learning model. Sci Rep 16, 10444 (2026). https://doi.org/10.1038/s41598-026-41050-z
Parole chiave: malattia renale cronica, predizione del rischio renale, apprendimento automatico medico, IA interpretabile, cartelle cliniche elettroniche