Clear Sky Science · it
Approccio dinamico di machine learning per la previsione del carico di lavoro negli ambienti cloud
Perché la previsione intelligente del traffico è importante
Ogni volta che riproduci un video in streaming, segui un grande evento sportivo online o fai acquisti durante una vendita lampo, migliaia di altri utenti potrebbero cliccare nello stesso istante. Dietro le quinte, i data center cloud si affrettano a mantenere i siti veloci senza sprecare denaro per macchine inattive. Questo articolo affronta una domanda semplice ma di grande impatto pratico: come possono i sistemi cloud anticipare ondate improvvise di traffico web abbastanza da accendere o spegnere i server al momento giusto, invece di indovinare e pagare troppo?
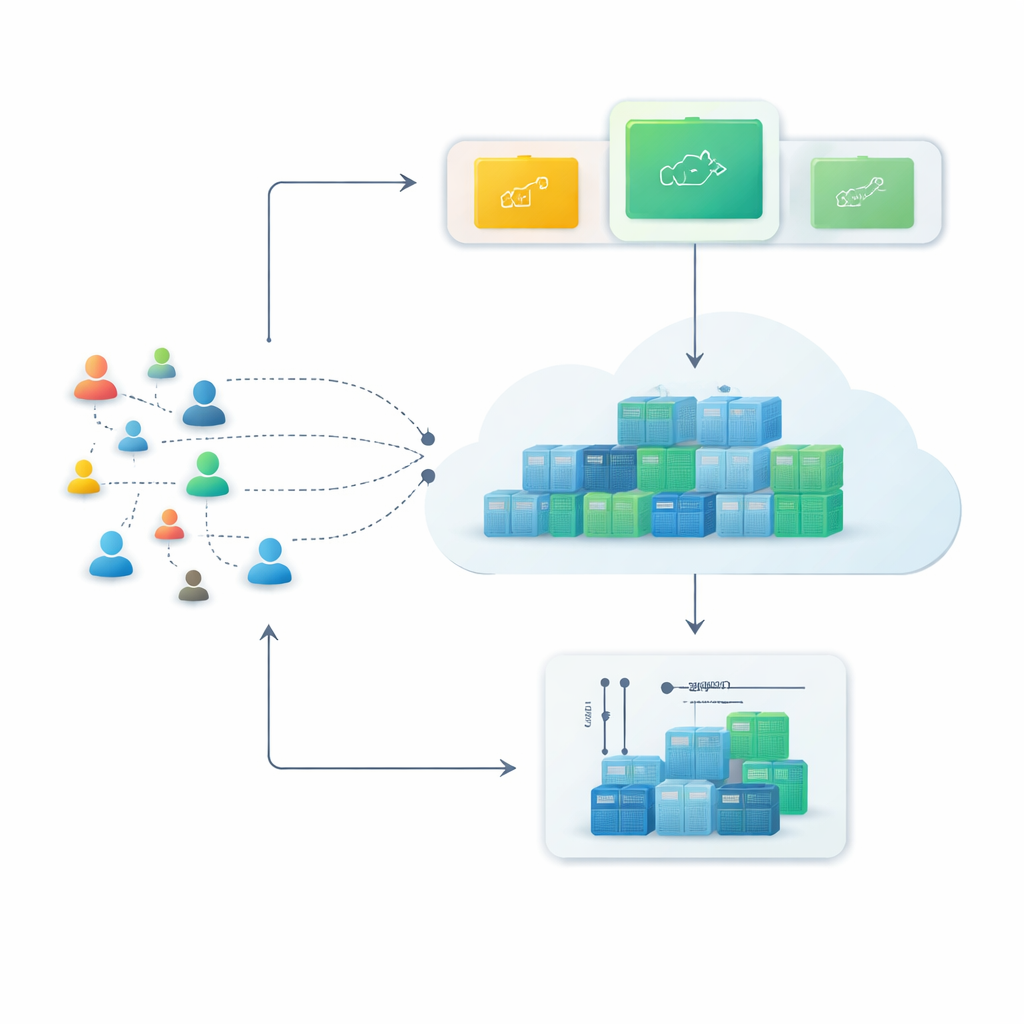
Da server rigidi a container flessibili
Le piattaforme cloud moderne si affidano sempre più ai container, piccoli pacchetti software che possono essere avviati o arrestati in pochi secondi. Rispetto alle tradizionali macchine virtuali, i container sono più leggeri e possono essere impilati più densamente, rendendoli ideali per servizi che devono crescere rapidamente durante le ore di punta e ridursi in seguito. Tuttavia questa flessibilità è vantaggiosa solo se il sistema riesce a prevedere i problemi in anticipo—se può stimare quanti richieste web arriveranno nei prossimi minuti e predisporre il numero giusto di container prima che servano.
Perché la previsione uguale per tutti fallisce
Ricerche precedenti hanno provato molti metodi diversi per prevedere il traffico web, dalla statistica classica alle reti neurali profonde. Alcuni funzionano bene quando la domanda cambia in modo graduale durante la giornata; altri sono migliori quando il traffico salta in modo imprevedibile, come durante una partita ai Mondiali. Il problema è che nessun singolo metodo è il migliore in ogni situazione. Se gli operatori scelgono un modello preferito e lo mantengono fisso, l'accuratezza può calare bruscamente ogni volta che il comportamento degli utenti cambia, portando a siti lenti oppure a file di macchine poco utilizzate che consumano denaro ed energia inutilmente.
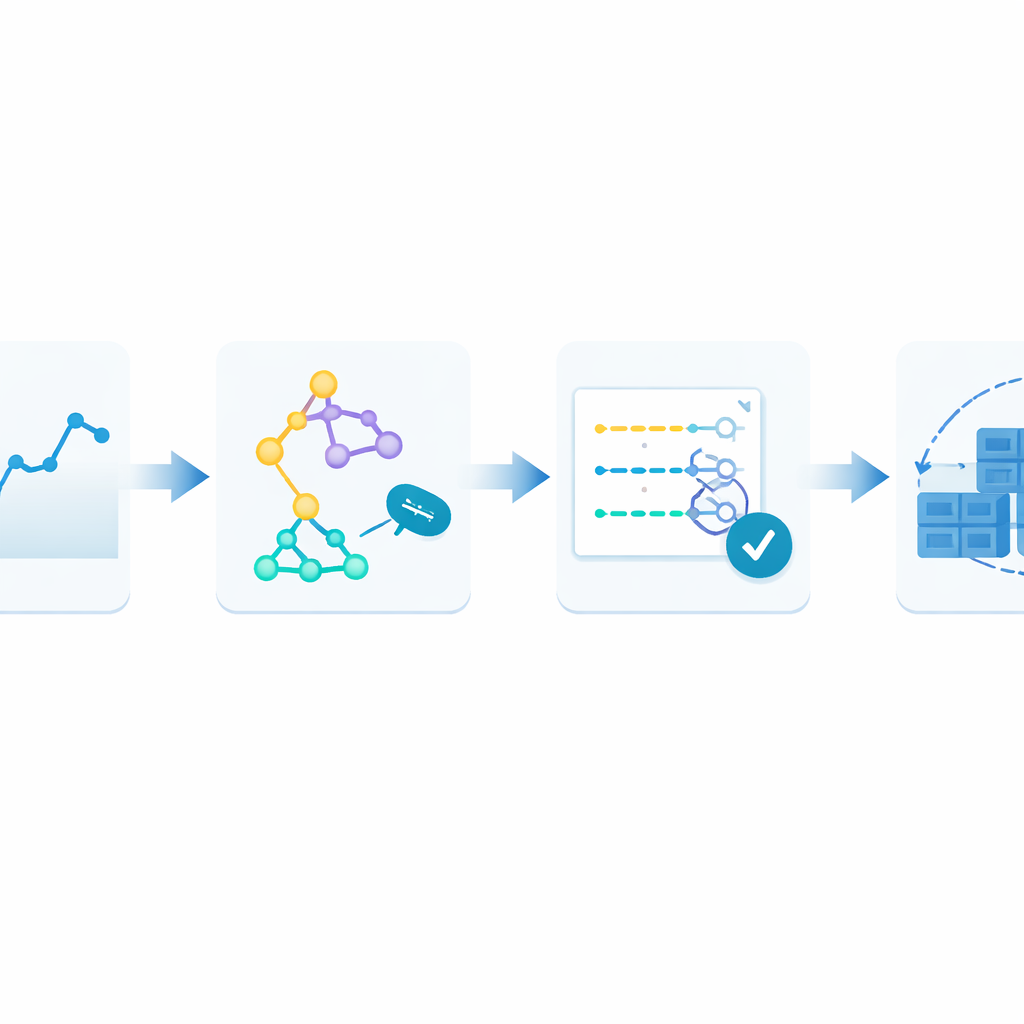
Un ciclo di apprendimento che non smette mai di adattarsi
Per superare questo limite, gli autori propongono un quadro a circuito chiuso che chiamano Monitor–Train–Test–Deploy. L'idea è trattare la previsione come un processo vivo. Prima, il sistema registra continuamente le richieste web in arrivo in una cronologia temporizzata. Poi allena in parallelo diversi metodi di forecasting, ciascuno tentando di apprendere pattern da quella storia recente. Successivamente testa questi modelli candidati sui dati più aggiornati e li valuta in base a quanto le loro stime si discostano dalla realtà. Solo il modello con le prestazioni migliori viene incaricato di fare previsioni in tempo reale, che guidano il numero di container da eseguire. Con l'arrivo di nuovo traffico, il ciclo si ripete: se gli errori di previsione aumentano oltre una soglia tollerata per due cicli consecutivi, il sistema si riaddestra automaticamente e può trasferire il controllo a un modello diverso.
Valutare il framework
I ricercatori hanno valutato questo approccio usando sia tracce sintetiche sia reali di attività web. Hanno generato diversi schemi idealizzati—curve a campana regolari, carichi in crescita costante a diverse velocità e traffico altamente erratico—e hanno anche usato i record dei siti ufficiali dei Mondiali del 1998 e del 2018, dove l'interesse esplode bruscamente. Per ciascun caso hanno confrontato tre o quattro strumenti di previsione noti, tra cui un metodo basato sulla statistica, un modello a support vector, un insieme di alberi decisionali e, in esperimenti successivi, un tipo popolare di rete neurale ricorrente. Il risultato chiave è stato che il “vincitore” variava a seconda della situazione: i modelli statistici semplici eccellevano quando la domanda era stabile, mentre i metodi basati sull'apprendimento erano chiaramente superiori quando il traffico diventava selvaggio e burtoso.
Vantaggi in accuratezza ed efficienza
Passando continuamente al modello più adatto al comportamento osservato, il framework ha ridotto gli errori di previsione fino a circa il 15 percento rispetto all'uso di un modello fisso. Altrettanto importante, lo ha fatto senza eseguire tutti i modelli contemporaneamente. Durante l'operazione live è attivo un solo predittore; gli altri vengono riaddestrati e verificati periodicamente, mantenendo modesto il carico computazionale. Gli autori introducono inoltre una soglia che si stringe gradualmente per decidere quando riaddestrare, in modo che il sistema diventi meno tollerante verso errori ripetuti, riducendo il rischio di lunghi periodi di previsione scadente.
Cosa significa per gli utenti cloud di tutti i giorni
In termini pratici, lo studio mostra che le piattaforme cloud possono essere gestite in modo più intelligente lasciando che i modelli di previsione competano e adattando la scelta nel tempo. Per gli utenti ciò può tradursi in esperienze online più fluide durante i grandi eventi e in meno rallentamenti quando le folle appaiono inaspettatamente. Per i fornitori promette un uso più snello delle risorse di calcolo, costi operativi inferiori e meno energia sprecata. Piuttosto che puntare su un singolo algoritmo brillante, questo lavoro sostiene un anello di controllo flessibile che continua a imparare, testare e rivedere come anticipare la domanda in un mondo digitale sempre più imprevedibile.
Citazione: Nashaat, M., Moussa, W., Rizk, R. et al. Dynamic machine learning approach for workload prediction in cloud environments. Sci Rep 16, 10983 (2026). https://doi.org/10.1038/s41598-026-40777-z
Parole chiave: previsione carico cloud, autoscaling, container, machine learning, serie temporali