Clear Sky Science · it
Un sistema di recupero multi-utente che preserva la privacy per l’intelligenza artificiale multimodale
Perché è importante mantenere private le ricerche intelligenti
Molti di noi si affidano oggi a intelligenze artificiali basate sul cloud per setacciare foto, documenti e persino esami medici. Questi sistemi sono potenti perché comprendono immagini e parole, ma pongono anche una domanda difficile: come possiamo godere di questa comodità senza consegnare il significato dei nostri dati più sensibili a server remoti? Questo articolo presenta PMIRS, un nuovo sistema che mira a consentire a molti utenti di cercare attraverso collezioni miste di immagini e testo mantenendo nascoste le loro informazioni alle macchine cloud che eseguono le ricerche.
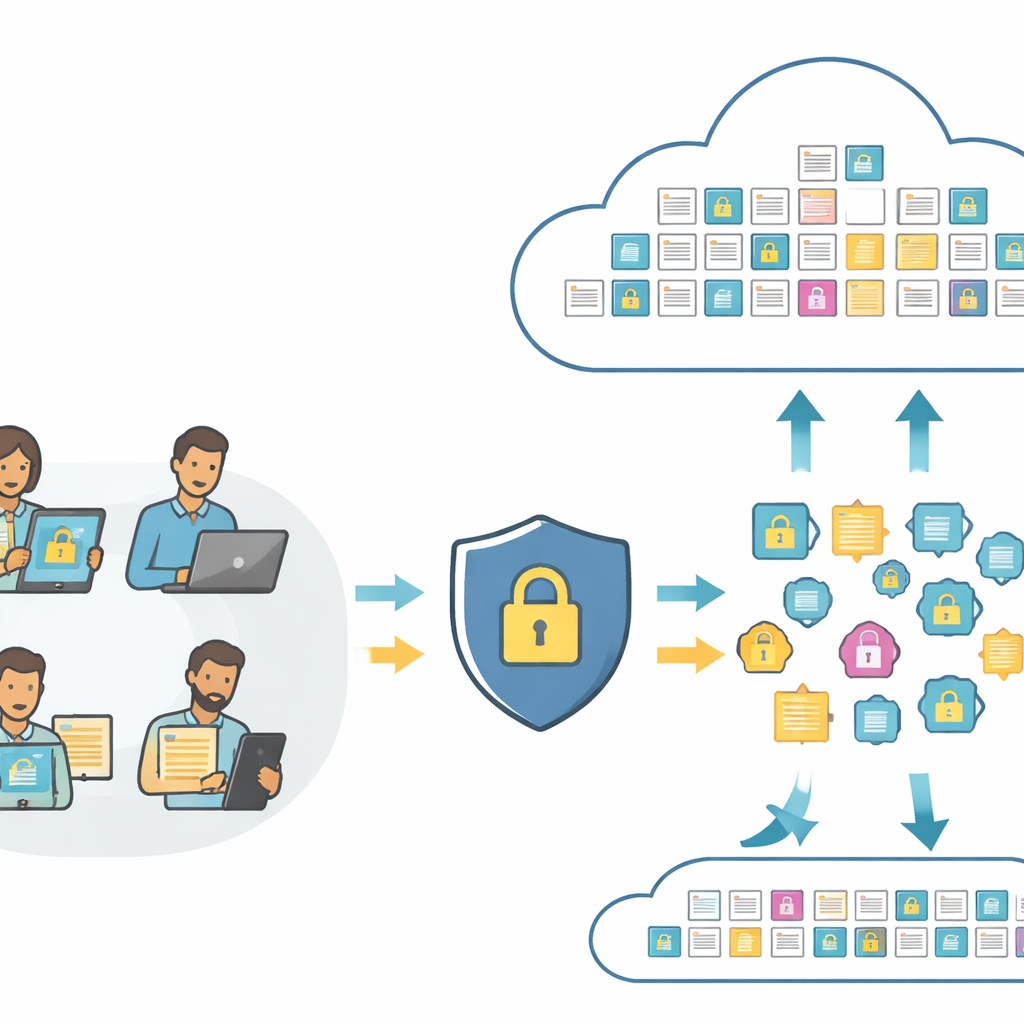
Cercare immagini e testo senza rivelarne il significato
Al centro degli strumenti di ricerca moderni ci sono gli “embeddings”—impronte numeriche che catturano il contenuto di una foto o di una frase in modo che un computer possa confrontarli. I sistemi standard inviano queste impronte direttamente al cloud, dove possono essere analizzate o addirittura usate impropriamente. PMIRS riorganizza questa pipeline. Gli utenti inviano prima le loro immagini e i loro testi grezzi a uno strato locale, che li trasforma in impronte usando un modello compatto visione-linguaggio. Prima che qualcosa lasci il lato dell’utente, le impronte vengono mescolate in modo controllato e poi cifrate. Il cloud vede solo queste impronte protette e copie completamente cifrate dei dati archiviati, eppure può ancora svolgere il matching e restituire i risultati migliori.
Apprendere da molti utenti senza raccogliere i loro dati in un unico luogo
Allenare un buon modello immagine–testo normalmente richiede di raccogliere grandi quantità di esempi etichettati in un unico posto—un chiaro rischio per la privacy. PMIRS invece utilizza il federated learning. In questa configurazione, il modello sottostante, adattato dall’architettura nota CLIP, viene inviato a molti dispositivi. Ognuno si allena localmente sui propri coppie immagine–testo private e invia indietro solo i pesi del modello aggiornati, che a loro volta sono cifrati. Un server centrale media questi aggiornamenti per migliorare un modello condiviso senza vedere mai le foto o le descrizioni raw di nessun utente. Gli autori riducono ulteriormente e rifiniscono il modello tramite un processo a fasi di “distillazione” che elimina le parti non necessarie preservando l’accuratezza, rendendo il sistema sufficientemente leggero per una distribuzione pratica.
Nascere il significato dentro impronte mescolate
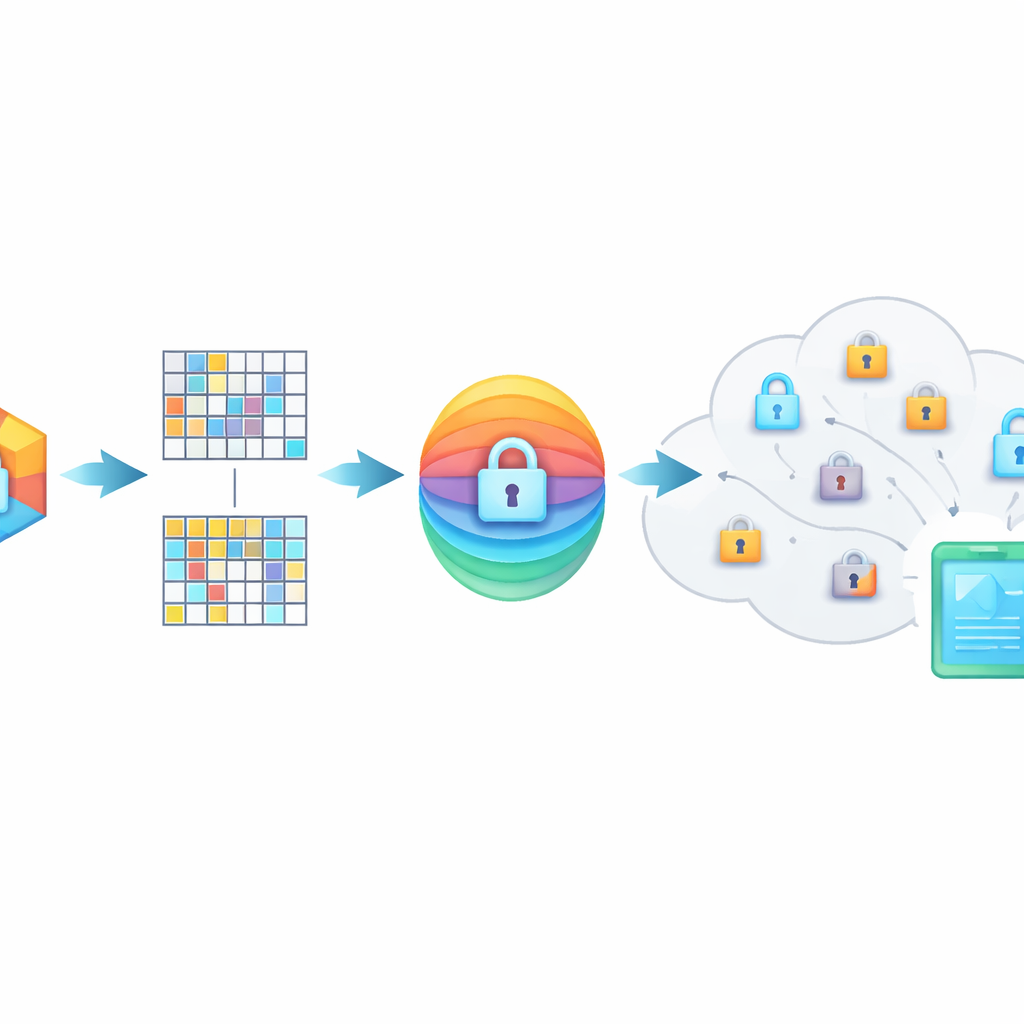
PMIRS protegge le query con uno scudo a due livelli. Primo, ogni impronta è divisa in blocchi e ciascun blocco è trasformato da una matrice segreta, oltre a un pattern di rumore progettato con cura. Questo mescolamento nasconde la struttura originale dei dati ma è progettato in modo che, quando due elementi correlati sono entrambi trasformati, la loro similarità rimanga la stessa. Secondo, il risultato viene cifrato usando il metodo AES ampiamente adottato, con chiavi che non vengono mai trasmesse in chiaro attraverso la rete. Per situazioni in cui una persona deve cercare nei dati di un’altra—ad esempio un medico che consulta uno specialista—il sistema usa un protocollo di scambio di chiavi Diffie–Hellman in modo che possano concordare segreti condivisi senza esporli a intercettatori.
Come si comporta il sistema nella pratica
Per verificare se queste protezioni hanno un costo eccessivo, i ricercatori hanno costruito un benchmark che abbina immagini di uso quotidiano a brevi frasi in linguaggio naturale—più vicino a come le persone descrivono realmente le cose rispetto a etichette di una singola parola. Hanno confrontato PMIRS con una ricerca standard basata su CLIP su tre temi: scene naturali, oggetti prodotti e attività o paesaggi. Su molte dimensioni di repository, PMIRS ha costantemente trovato un migliore equilibrio tra intercettare tutti i risultati corretti (recall) ed evitare corrispondenze errate (precision), portando a un punteggio F1 medio—una misura combinata di accuratezza—circa 7,7% superiore al baseline. È importante che i tempi di risposta siano rimasti sotto i circa 180 millisecondi, abbastanza veloci per un uso interattivo, e spesso leggermente più rapidi del baseline non protetto nonostante i passaggi aggiuntivi di protezione.
Cosa significa questo per gli utenti comuni
In termini semplici, PMIRS dimostra che è possibile costruire strumenti di ricerca cloud che comprendono bene immagini e testo, servono molti utenti contemporaneamente e mantengono comunque il significato dei dati di ciascuno fuori dalla portata del provider cloud. Combinando addestramento locale, un mescolamento intelligente delle impronte, cifratura forte e scambio di chiavi sicuro, il sistema offre una pipeline end-to-end che preserva la privacy anziché proteggere solo una fase. Pur non coprendo ancora ogni possibile attacco e richiedendo ulteriori perfezionamenti e prove sul campo, il lavoro indica servizi futuri—come la ricerca di immagini mediche, bot per l’assistenza clienti o archivi aziendali—in cui le persone possono usufruire di ricerche AI multimodali ricche con molte meno preoccupazioni che i loro contenuti personali vengano rivelati o abusati.
Citazione: Gao, Y., Luo, W., Wang, C. et al. A privacy-preserving multi-user retrieval system for multimodal artificial intelligence. Sci Rep 16, 10348 (2026). https://doi.org/10.1038/s41598-026-40734-w
Parole chiave: IA che preserva la privacy, ricerca multimodale, federated learning, ricerca cifrata, calcolo cloud sicuro