Clear Sky Science · it
Modello basato su clustering e regressione e analisi delle prestazioni per la predizione precoce delle malattie cardiache
Perché è importante individuare precocemente i problemi cardiaci
Le malattie cardiache spesso si sviluppano silenziosamente nell'arco di molti anni e, quando compaiono sintomi evidenti, il danno può essere già avvenuto. Questo studio esplora come sensori indossabili di uso quotidiano e analisi intelligente dei dati possano lavorare insieme per individuare segnali di allarme prima, offrendo a medici e pazienti più tempo per intervenire. Combinando due modalità diverse di interpretare i dati sanitari, i ricercatori puntano a rendere le predizioni più accurate senza rendere la tecnologia più complessa da usare nelle cliniche reali.
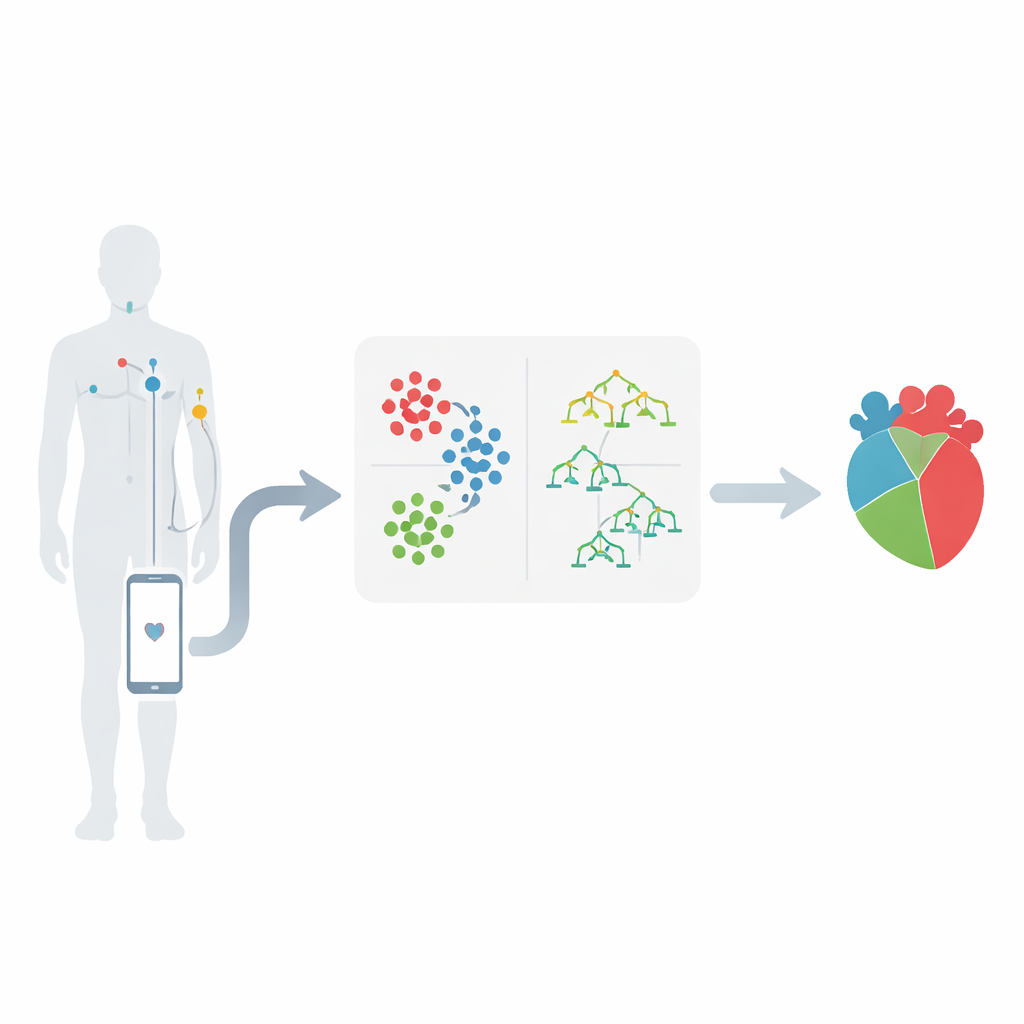
Dai sensori corporei agli avvisi intelligenti
Il lavoro si colloca nell'ambito delle reti di sensori wireless indossabili, dove piccoli sensori applicati sulla pelle monitorano segnali quali frequenza cardiaca, pressione arteriosa e attività elettrica del cuore. Questi sensori trasmettono le misurazioni a un dispositivo mobile, che le inoltra a un centro medico per l'analisi. L'idea chiave è che questi flussi di numeri possono rivelare pattern che suggeriscono problemi cardiaci in sviluppo molto prima di una crisi. Gli autori si concentrano su un noto dataset per le malattie cardiache, selezionando 12 caratteristiche importanti, tra cui il tipo di dolore toracico, la pressione arteriosa, il colesterolo, la glicemia, il disagio toracico indotto dall'esercizio e le modifiche osservate in un elettrocardiogramma.
Individuare gruppi nascosti nei dati dei pazienti
Invece di inserire tutti i record dei pazienti direttamente in una singola formula predittiva, il team raggruppa prima i pazienti simili fra loro. Utilizzano un metodo chiamato K-means clustering, che ordina le persone in cluster basati sulla somiglianza delle loro misurazioni, con l'età che gioca un ruolo centrale. Per esempio, i pazienti possono raggrupparsi naturalmente in insiemi con pressione molto alta, colesterolo elevato o schemi particolari nei test cardiaci. Questo passaggio di raggruppamento aiuta a mettere in evidenza quali combinazioni di misurazioni sono particolarmente preoccupanti. Rivela anche che certi intervalli — come pressione oltre 150, colesterolo superiore a 300 o specifiche variazioni delle tracce cardiache — tendono a essere associati a un rischio molto più elevato.
Insegnare alle macchine a valutare il rischio
Dopo il raggruppamento dei dati, i ricercatori applicano diversi metodi di machine learning che apprendono dai casi passati per prevedere se un nuovo paziente è probabile che abbia una malattia cardiaca significativa. Confrontano approcci diversi, incluse le decision tree, k-nearest neighbors, support vector machines, regressione logistica, Naïve Bayes e random forest. Nel loro design ibrido, ogni nuovo paziente viene prima assegnato al cluster più vicino; poi un modello random forest addestrato specificamente su quel tipo di pazienti fornisce la predizione finale del rischio. I dati sono accuratamente puliti, scalati e divisi in set di addestramento e test, e si affronta lo sbilanciamento delle classi (più pazienti sani che malati) in modo che i modelli non diventino pregiudicati verso il gruppo maggioritario.
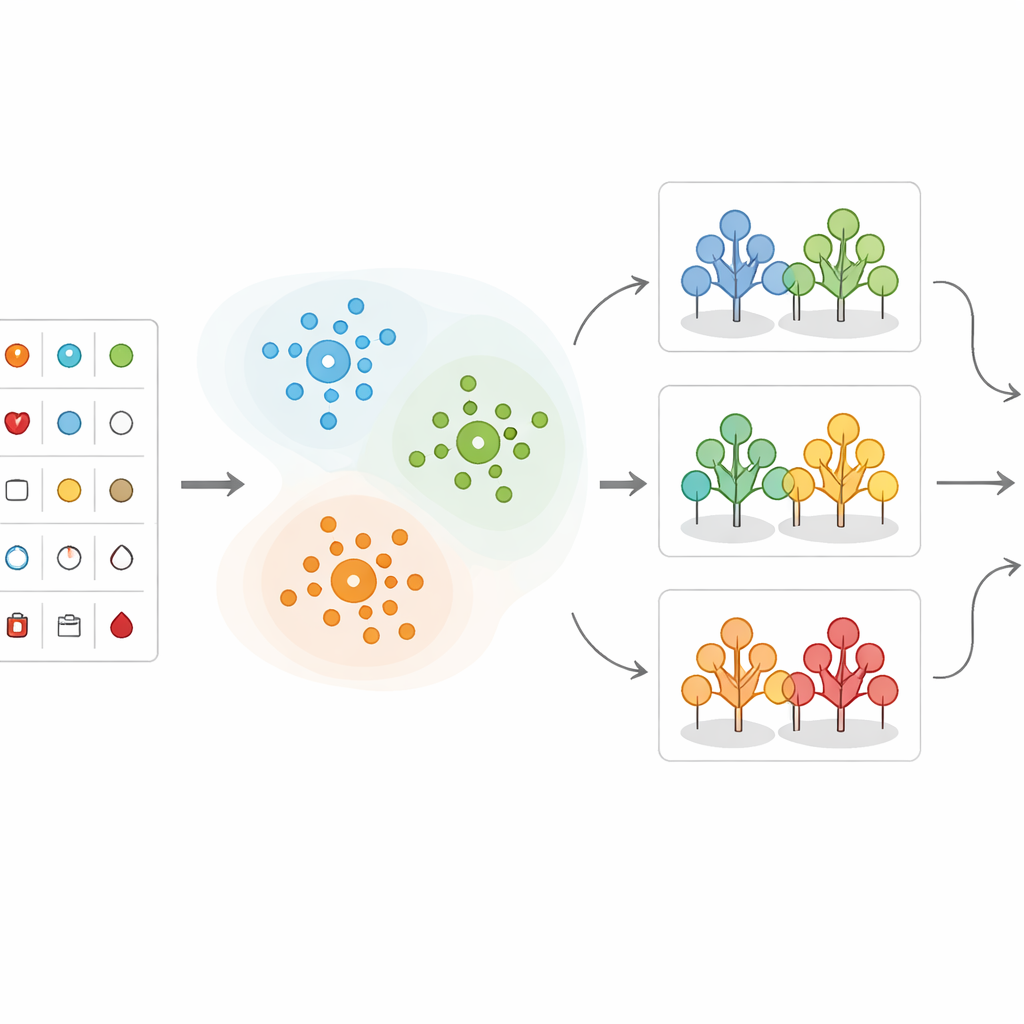
Quanto bene si comporta il modello ibrido
Per valutare il successo, lo studio considera non solo l'accuratezza complessiva ma anche quanto spesso il modello segnala correttamente i pazienti malati (recall), rassicura correttamente quelli sani (specificità) e bilancia entrambi gli obiettivi (F1 score e ROC–AUC). Studi precedenti che utilizzavano dati simili spesso si fermavano intorno all'85 percento di accuratezza e facevano fatica a migliorare queste misure più fini. Qui, l'approccio combinato clustering più random forest raggiunge circa il 91 percento di accuratezza, con un buon recall e una specificità molto elevata. Gli intervalli di confidenza per questo modello non si sovrappongono a quelli dei metodi più semplici, suggerendo che il miglioramento è improbabile che sia dovuto al caso. Allo stesso tempo, i tempi di calcolo rimangono in una fascia pratica — dell'ordine dei millisecondi ai secondi — adatta per sistemi di monitoraggio in tempo reale o quasi real-time.
Cosa significa per pazienti e medici
In termini pratici, lo studio mostra che lasciare che i computer prima ordinino i pazienti in gruppi significativi e poi applichino regole predittive su misura può affinare la rilevazione precoce delle malattie cardiache. Il metodo è particolarmente promettente per configurazioni di monitoraggio continuo, dove i sensori indossabili raccolgono silenziosamente i dati in background. Sebbene i risultati provengano da un dataset di dimensioni modeste e strutturato piuttosto che da cartelle cliniche complete, e gli autori mettano in guardia su possibili bias, il messaggio è chiaro: un uso più intelligente delle misurazioni esistenti può fornire ai medici un sistema di allerta precoce più affidabile. Con ulteriori sviluppi e dataset più ampi e ricchi, questo tipo di analisi ibrida potrebbe contribuire a trasformare le letture grezze dei sensori in avvisi personalizzati e tempestivi che prevengano infarti e altri eventi gravi prima che si verifichino.
Citazione: Tolani, M., AlZahrani, Y., Suman, G. et al. Clustering-cum-regression based model and performance analysis for early prediction of heart disease. Sci Rep 16, 9494 (2026). https://doi.org/10.1038/s41598-026-40626-z
Parole chiave: predizione delle malattie cardiache, sensori indossabili per la salute, apprendimento automatico, clustering di dati medici, modello random forest