Clear Sky Science · it
Valutazione dei modelli linguistici IA nel rispondere a domande sulla gravidanza valutata da specialisti in ostetricia
Perché è importante per le future famiglie
La gravidanza è un periodo pieno di domande, e molte persone si rivolgono oggi a strumenti online e chatbot per risposte rapide. Questo studio pone una domanda semplice ma importante: sulle preoccupazioni comuni in gravidanza, quanto sono bravi gli odierni chatbot di intelligenza artificiale (IA) a fornire informazioni chiare, accurate e rassicuranti che i medici considererebbero affidabili?
Confronto tra tre “motori di risposta” digitali
Ricercatori in Turchia hanno confrontato tre noti modelli linguistici IA—una versione precedente di ChatGPT (3.5), una versione più recente (4.0) e Gemini di Google. Si sono concentrati su dieci domande di uso comune che le persone in gravidanza pongono frequentemente, come quali alimenti evitare, se sono sicuri esercizio e rapporti sessuali, cosa potrebbe significare un sanguinamento precoce, come interpretare i movimenti fetali e quali segni di allarme richiedono cure urgenti. Ogni domanda è stata inserita in tutti e tre i sistemi usando le stesse istruzioni semplici, con impostazioni regolate per ridurre la casualità in modo che le risposte fossero coerenti piuttosto che loquaci o creative.
Ogni modello ha prodotto una risposta per domanda, in turco, senza prompt di follow-up né modifiche. Le risposte sono poi state depurate da qualsiasi elemento che potesse rivelare quale sistema le avesse generate e mescolate in ordine casuale. In questo modo i revisori umani—specialisti in ostetricia e ginecologia—hanno giudicato solo quanto fosse scritto, non il marchio o lo stile che pensassero di riconoscere. 
Come i medici hanno valutato le risposte
Settantacinque specialisti ostetrici, dagli inizi carriera ai clinici molto esperti, hanno valutato tutte e 30 le risposte anonimizzate. Per ciascuna risposta hanno utilizzato una scala a cinque punti per giudicare quattro qualità: accuratezza (corrisponde alle conoscenze e alle linee guida mediche attuali?), affidabilità (il messaggio è internamente coerente e privo di consigli pericolosi?), orientamento al paziente (il tono è adatto e rassicurante per i non esperti?) e comprensibilità (il linguaggio è chiaro, ben strutturato e facile da seguire?). In totale, gli esperti hanno fornito 9.000 valutazioni individuali—un dataset ampio che ha permesso ai ricercatori di rilevare differenze significative tra i tre strumenti IA.
Il team ha poi usato metodi statistici pensati per scale di valutazione per confrontare i modelli. Hanno anche verificato quanto siano coerenti le valutazioni tra diversi medici ed esplorato se i clinici più esperti penalizzassero o meno in modo diverso rispetto ai colleghi più giovani. L’obiettivo non era costruire un chatbot operativo, ma scattare una fotografia accurata del comportamento di questi sistemi in condizioni controllate quando rispondono a domande realistiche sulla gravidanza.
Quale chatbot ha fatto meglio?
Nel complesso, la più recente ChatGPT-4.0 si è classificata al primo posto. I medici hanno giudicato le sue risposte le più accurate e le più orientate al paziente, ed è risultata la migliore anche in termini di affidabilità. Gemini si è collocata generalmente al livello intermedio: le sue risposte erano spesso chiare e facili da leggere, e in termini di comprensibilità era simile a ChatGPT-4.0, ma tendeva a essere un po’ meno dettagliata e precisa. ChatGPT-3.5, il modello più vecchio, ha ricevuto consistentemente i punteggi più bassi, con spiegazioni spesso più brevi o meno complete. È interessante notare che sulla chiarezza di base e sulla struttura testuale tutti e tre i modelli apparivano più simili, il che suggerisce che rendere il testo leggibile può essere più semplice che garantire che ogni dettaglio medico sia corretto e bilanciato. 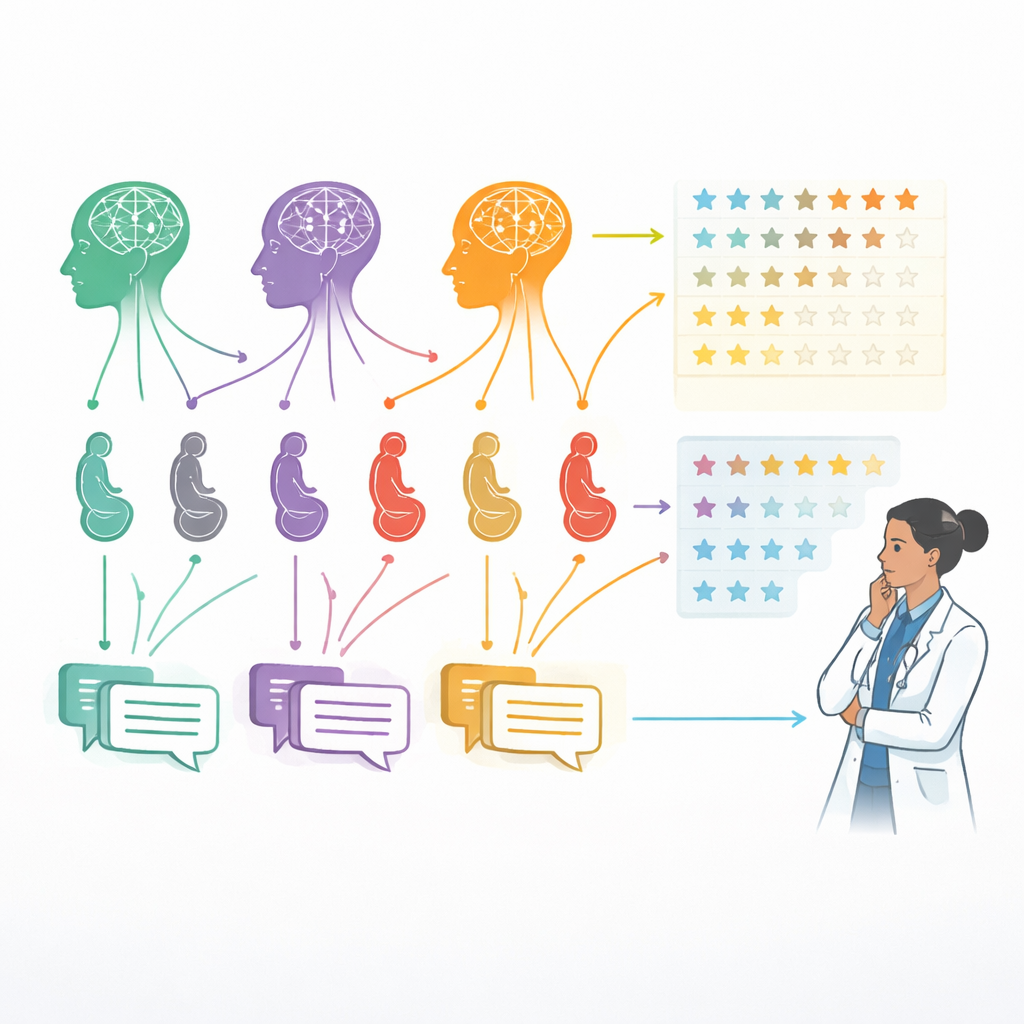
Le valutazioni dei medici sono risultate molto coerenti tra loro, a indicare che i risultati non sono stati determinati da poche opinioni anomale. È emersa una tendenza modesta per cui i clinici più esperti davano punteggi di affidabilità leggermente più alti nel complesso, ma le loro opinioni differivano poco su quanto le risposte fossero amichevoli o facili da capire.
Cosa significa per l’uso nella pratica
Per un utente non esperto, la conclusione è che gli strumenti IA moderni—soprattutto ChatGPT-4.0—possono già fornire informazioni sulla gravidanza che molti specialisti ostetrici considerano ragionevolmente accurate, sicure e facilmente leggibili. Detto questo, lo studio evidenzia anche un limite importante: anche il sistema con le migliori prestazioni non è un medico. I ricercatori non hanno confrontato le risposte dei chatbot con gli “standard oro” delle linee guida ufficiali, né hanno valutato come i pazienti interpretino o mettano in pratica i consigli. Poiché il lavoro è stato condotto interamente in turco, le prestazioni in altre lingue e culture possono differire.
In termini concreti, questi chatbot IA possono essere utili compagni per informarsi sulla gravidanza, soprattutto quando una visita in clinica è lontana o il tempo con il professionista è limitato. Possono supportare, ma non dovrebbero sostituire, le conversazioni con gli operatori sanitari. Gli autori sottolineano che la supervisione di esperti rimane essenziale per individuare errori, evitare falsi rassicuramenti e garantire che le situazioni sfumate o ad alto rischio ricevano le cure personali e in presenza di cui hanno bisogno.
Citazione: Keyif, B., Yurtçu, E., Başbuğ, A. et al. Evaluation of AI language models in answering pregnancy-related questions assessed by obstetrics specialists. Sci Rep 16, 9322 (2026). https://doi.org/10.1038/s41598-026-40609-0
Parole chiave: educazione in gravidanza, chatbot IA, consigli sanitari online, ostetricia, qualità delle informazioni per i pazienti