Clear Sky Science · it
Collisioni esatte di caratteristiche nelle reti neurali
Quando immagini diverse ingannano una macchina intelligente
I sistemi di intelligenza artificiale moderni possono riconoscere volti, leggere immagini mediche e guidare auto a guida autonoma. Sappiamo già che possono essere ingannati da piccole modifiche all’immagine, accuratamente studiate. Questo studio mostra qualcosa di ancora più sorprendente: le stesse reti possono essere cieche davanti a cambiamenti grandi e ovvi, trattando immagini molto diverse come se fossero identiche. Capire come e perché ciò accade è cruciale se vogliamo sistemi di IA di cui poterci davvero fidare.
Dalle piccole alterazioni ai grandi punti ciechi
Le reti neurali profonde alimentano le scoperte odierne in visione, linguaggio e molti altri campi. Ricerche precedenti sugli esempi avversari hanno rivelato che una modifica appena visibile a un’immagine può far sì che una rete la classifichi erroneamente con alta confidenza. Lavori più recenti hanno scoperto il problema opposto: alcune reti reagiscono di poco a cambiamenti ampi e ovvi, producendo previsioni quasi identiche. In quei casi, le caratteristiche interne estratte da due immagini molto diverse «collisionano», cioè la rete le rappresenta in modo quasi equivalente. Questo studio porta l’idea molto oltre, dimostrando che le reti comuni non hanno solo collisioni approssimative, ma possono avere collisioni di caratteristiche esatte, in cui due input distinti vengono mappati esattamente agli stessi segnali interni.
Come nascono le collisioni dentro una rete
Per spiegare queste collisioni, gli autori osservano il funzionamento interno delle reti neurali e si concentrano sulle loro matrici di pesi, i numeri addestrati che connettono uno strato al successivo. Una collisione di caratteristiche si verifica quando due input diversi producono la stessa uscita in uno strato; una volta che ciò accade, tutti gli strati successivi vedono la stessa cosa e quindi non possono distinguere gli input. Matematicamente, questo avviene quando la differenza tra due input giace nello «spazio nullo» dei pesi di uno strato: direzioni nello spazio degli input che lo strato ignora completamente. Gli autori mostrano che ogni volta che una matrice di pesi ha un valore proprio zero o mappa da uno spazio a dimensione più alta a uno a dimensione più bassa, tali direzioni ignorate devono esistere. Poiché la maggior parte delle architetture reali, inclusi i modelli popolari per classificazione, segmentazione e rilevamento degli oggetti, utilizza molti di questi strati, le collisioni non sono casi rari ma una proprietà quasi inevitabile di queste reti.
Un nuovo modo di costruire input che collidono
Sfruttando questa intuizione, l’articolo introduce una ricetta pratica chiamata ricerca nello spazio nullo. Invece di affidarsi a tentativi o a trucchi basati sul gradiente, questo metodo utilizza direttamente lo spazio nullo della prima matrice di pesi. Partendo da qualsiasi immagine, gli autori calcolano un vettore che il primo strato ignora, quindi aggiungono una versione scalata di quel vettore all’immagine. Poiché quella direzione è invisibile allo strato, le caratteristiche interne della rete — e la previsione finale — restano esattamente le stesse, anche se l’immagine appare fortemente distorta a un osservatore umano. La stessa idea si estende agli strati convoluzionali e, in linea di principio, anche a strati successivi. Gli autori analizzano molti modelli standard e scoprono che la maggior parte possiede numerose direzioni di questo tipo, il che significa che si possono generare innumerevoli immagini in collisione per una vasta gamma di compiti.
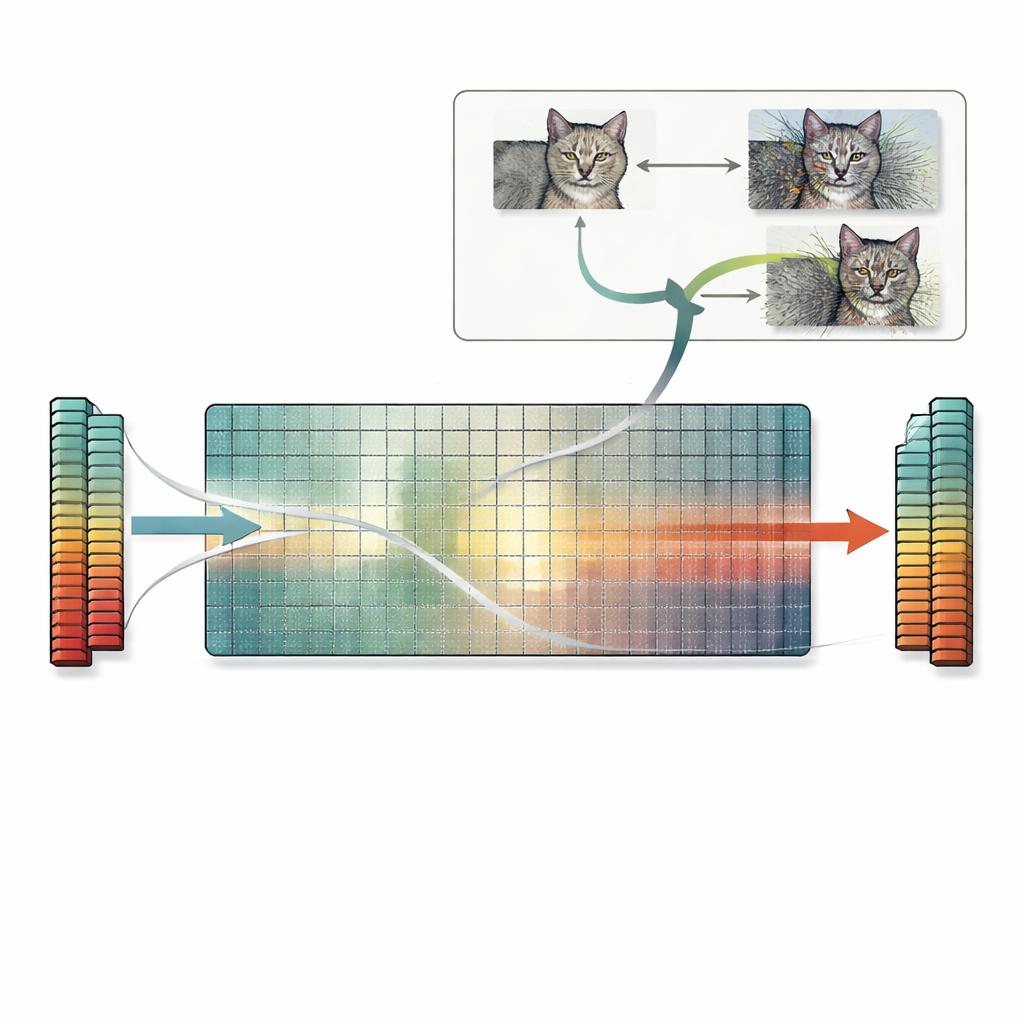
Rischi nascosti per somiglianza, spiegazioni e sicurezza
Queste collisioni di caratteristiche esatte hanno conseguenze di ampia portata. Due immagini con caratteristiche in collisione non solo condivideranno la stessa previsione, ma spesso avranno anche le stesse mappe esplicative prodotte dagli strumenti di interpretabilità più diffusi. Ciò può far sì che un’immagine irriconoscibile e pesantemente perturbata appaia altrettanto ben supportata quanto una pulita, minando la fiducia nei metodi di spiegazione. Il problema riguarda anche le misure di somiglianza basate su caratteristiche che si appoggiano alle reti neurali: tali metriche possono giudicare un’immagine fortemente corrotta come «identica» all’originale perché le caratteristiche corrispondono esattamente, mentre semplici punteggi basati sui pixel segnalerebbero correttamente grandi differenze. Infine, la ricerca nello spazio nullo può essere combinata con attacchi avversari standard, producendo molte immagini avversarie diverse che forniscono tutte la stessa predizione errata e restano entro i limiti di perturbazione tipici, aggravando le preoccupazioni di sicurezza esistenti.
Cosa significa questo per costruire IA più sicure
In termini semplici, questo lavoro mostra che le reti neurali odierne spesso scartano informazioni in modi prevedibili, lasciando intere direzioni nello spazio degli input che non influenzano affatto le loro decisioni. Gli aggressori possono sfruttare questi punti ciechi per creare immagini bizzarre o avversarie che la rete tratta come identiche a quelle normali. Gli autori suggeriscono di usare semplici conteggi di queste direzioni ignorate come modo per valutare quanto un modello potrebbe essere vulnerabile, e sostengono che reti più snelle e meglio regolarizzate con spazi nulli più piccoli potrebbero essere più robuste. Sebbene molto debba ancora essere testato in pratica, il messaggio centrale è chiaro: se vogliamo un’IA affidabile, dobbiamo prestare attenzione non solo a ciò a cui le reti rispondono, ma anche a ciò che ignorano.
Citazione: Ozbulak, U., Rao, S., De Neve, W. et al. Exact feature collisions in neural networks. Sci Rep 16, 10139 (2026). https://doi.org/10.1038/s41598-026-40605-4
Parole chiave: reti neurali, esempi avversari, collisioni di caratteristiche, robustezza del modello, ricerca nello spazio nullo