Clear Sky Science · it
Apprendimento federato a tutela della privacy con CNN migliorate da attenzione leggera per la rilevazione automatica della leucemia su immagini mediche distribuite
Perché condividere conoscenze senza condividere segreti è importante
La medicina moderna si affida sempre più ai computer per leggere immagini mediche, dalle radiografie ai vetrini al microscopio. Ma addestrare questi sistemi di solito significa raccogliere dati sensibili dei pazienti in un unico luogo, il che solleva serie preoccupazioni sulla privacy. Questo studio mostra un modo per permettere agli ospedali di costruire un sistema potente per rilevare la leucemia da immagini del sangue senza mai condividere i dati grezzi dei pazienti, combinando la protezione della privacy con una precisione diagnostica prossima ai livelli migliori.
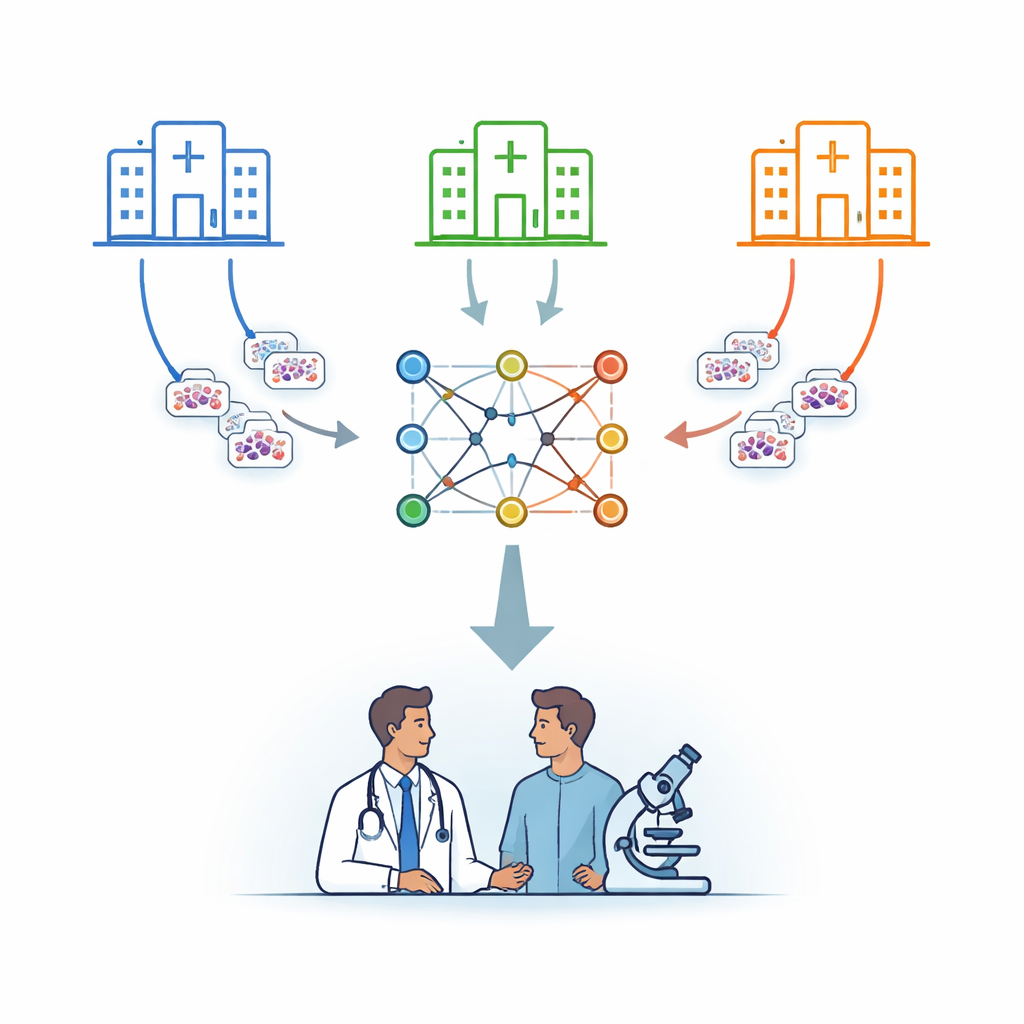
Molti ospedali, un cervello condiviso
I ricercatori si concentrano sulla leucemia, un tumore del sangue che viene diagnosticato in parte esaminando le cellule al microscopio. Invece di inviare le immagini dei pazienti a un server centrale, usano una strategia chiamata apprendimento federato. In questo schema, diversi ospedali mantengono le immagini in sede e addestrano una copia dello stesso modello di calcolo localmente. Periodicamente vengono inviati solo i parametri appresi del modello a un server centrale sicuro, che li media e rimanda un modello combinato migliorato. In questo modo, la conoscenza viene aggregata mentre le immagini sottostanti non lasciano mai l’istituzione d’origine.
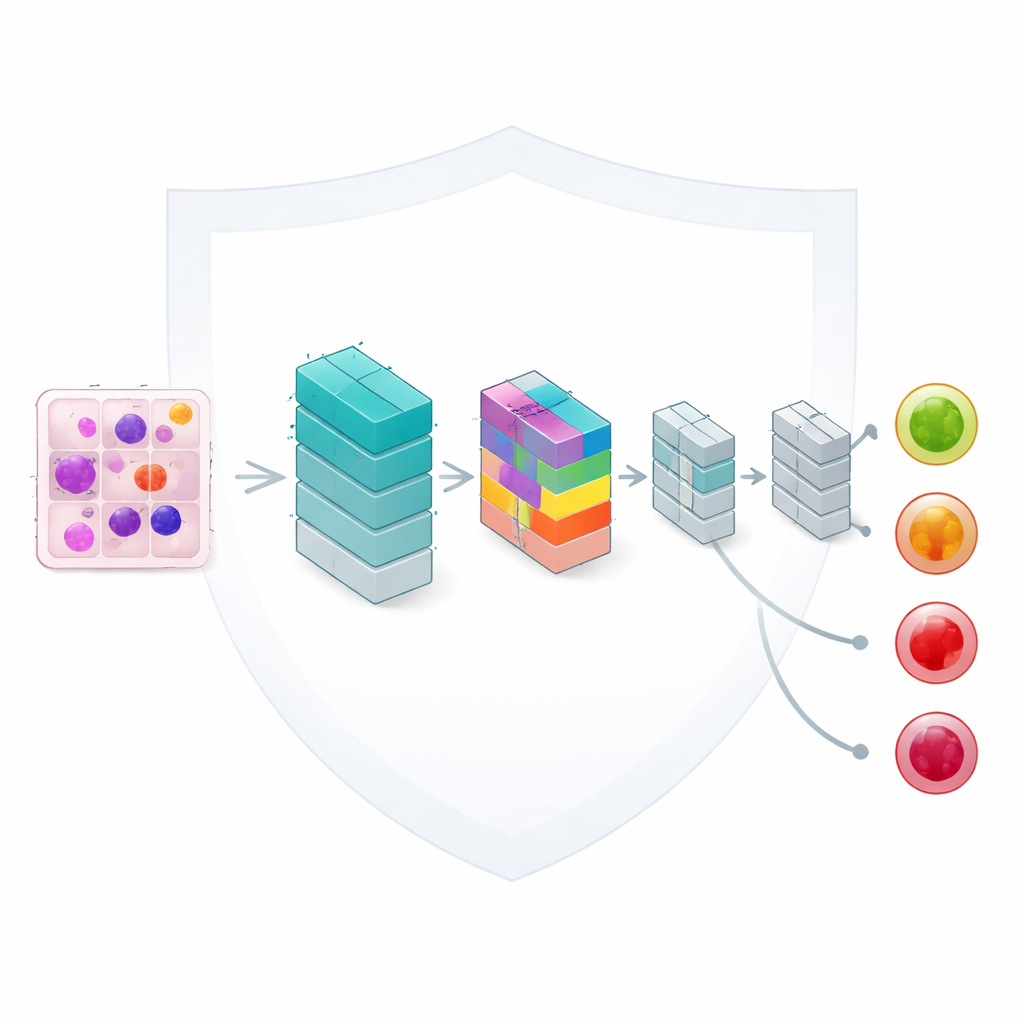
Addestrare una piccola rete a prestare attenzione
Al centro del framework c’è un modello di analisi delle immagini leggero basato su reti neurali convoluzionali, uno strumento standard per l’interpretazione delle immagini. Gli autori lo arricchiscono con un meccanismo di “attenzione” compatto che aiuta la rete a concentrarsi sulle parti più informative di ogni cellula del sangue, come la forma del nucleo e la texture del materiale circostante. Sebbene il modello abbia solo circa 33.000 parametri regolabili — una frazione delle dimensioni di molte reti moderne — riesce comunque a distinguere quattro categorie clinicamente importanti: cellule benigne, alterazioni precoci, stati pre-leucemici e cellule pro-leucemiche completamente sviluppate. Un progetto accurato mantiene i requisiti di calcolo sufficientemente bassi per un uso realistico nei laboratori di routine.
Apprendimento equo da dati disparati e distribuiti
Nei sistemi sanitari reali, gli ospedali non vedono la stessa composizione di pazienti. Un centro può osservare per lo più malattie in fase iniziale, un altro casi più avanzati. Il team replica deliberatamente questo squilibrio del mondo reale dividendo un dataset di 3.256 immagini di strisci di sangue tra più ospedali simulati con proporzioni differenti di ogni stadio della leucemia. Analizzano quindi come questa distribuzione diseguale influenzi l’apprendimento, usando misure statistiche per quantificare quanto i dati di ciascun ospedale siano diversi e quanto siano simili le loro accuratezze finali. Uno schema di media pesata garantisce che i siti con più dati abbiano un’influenza proporzionata pur mantenendo le differenze di performance tra i siti molto ridotte.
Accuratezza che rivaleggia con l’addestramento centralizzato
Nonostante i dati rimangano frammentati e distribuiti in modo diseguale, il modello condiviso impara a classificare gli stadi della leucemia con abilità impressionante. Con tre ospedali simulati, il modello globale raggiunge circa il 95,7% di accuratezza su immagini di test tenute separate; con cinque ospedali e più round di addestramento, l’accuratezza sale a circa il 96,6%. Le categorie maligne — quelle che rappresentano stati pre-leucemici e malattia più avanzata — sono riconosciute particolarmente bene, con punteggi quasi perfetti in alcuni casi. La categoria più difficile, quella benigna, che è sotto-rappresentata, ottiene risultati leggermente inferiori, evidenziando la necessità di un miglior bilanciamento o di tecniche mirate per classi rare ma importanti. Tuttavia, il sistema federato si avvicina per frazioni all’accuratezza ottenuta quando tutti i dati sono centralizzati, pur mantenendo i vantaggi di privacy dell’archiviazione locale.
Rendere visibile e affidabile il ragionamento della macchina
Per costruire fiducia con i clinici, gli autori vanno oltre la sola accuratezza ed esaminano come il modello prende le sue decisioni. Generano sovrapposizioni visive che evidenziano quali parti di ciascuna immagine cellulare hanno maggiormente influenzato il risultato. Queste mappe rivelano che il modello si concentra su caratteristiche di significato medico, come forme nucleari anomale negli stadi più pericolosi della leucemia, e mostra pattern più diffusi per le cellule benigne. Il team studia anche quanto il modello sia fiducioso nelle sue previsioni e scopre che le risposte corrette tendono ad avere alta fiducia, specialmente per gli stadi maligni, suggerendo una buona corrispondenza tra la certezza del sistema e la sua affidabilità.
Che cosa significa per la diagnosi del cancro nel futuro
Per i non esperti, il messaggio chiave è che ora è possibile per gli ospedali collaborare a diagnostiche oncologiche più intelligenti senza cedere le immagini dei pazienti. Questo lavoro dimostra che un modello compatto e progettato con cura, addestrato tramite apprendimento federato, può avvicinarsi all’accuratezza dei metodi tradizionali basati su dati aggregati, rispettando al contempo le regole sulla privacy e i limiti pratici di potenza di calcolo e traffico di rete. Con ulteriori lavori per gestire meglio i tipi cellulari sotto-rappresentati e ridurre i costi di comunicazione, sistemi simili a tutela della privacy potrebbero essere estesi ad altri tumori e test di imaging, aiutando i clinici di tutto il mondo a beneficiare dell’esperienza condivisa senza esporre i pazienti individuali.
Citazione: Awan, M.Z., Khan, N.A., Strakos, P. et al. Privacy-preserving federated learning with light-weight attention improved CNNs for automated leukemia detection across distributed medical imaging. Sci Rep 16, 9768 (2026). https://doi.org/10.1038/s41598-026-40581-9
Parole chiave: apprendimento federato, imaging della leucemia, privacy nell’IA medica, CNN basata sull’attenzione, patologia digitale