Clear Sky Science · it
CMT-Unet: sfruttare un framework ibrido per fasi per una maggiore accuratezza ed efficienza nella segmentazione delle immagini mediche
Visioni più nitide all'interno del corpo
La medicina moderna si basa molto su esami come TC e risonanza magnetica per guardare all'interno del corpo, ma trasformare queste immagini in scala di grigi, spesso sfocate, in contorni netti di organi e tessuti resta una sfida. I medici hanno bisogno di confini precisi per pianificare interventi chirurgici, monitorare la funzione cardiaca o misurare la risposta di un tumore a una terapia. Questo articolo presenta un nuovo approccio di visione artificiale, chiamato CMT-Unet, pensato per tracciare quei contorni in modo più accurato ed efficiente, avvicinando l'analisi automatizzata delle immagini a un uso clinico quotidiano.
Perché i contorni delle immagini sono importanti
Prima di un'operazione o di un trattamento complesso, i clinici spesso necessitano di una mappa a livello di pixel di organi o strutture in una scansione—un processo noto come segmentazione. Tradizionalmente, gli esperti tracciavano queste regioni manualmente, un compito lungo e faticoso soggetto a variabilità tra osservatori. Nell'ultimo decennio, i metodi di deep learning hanno preso in carico gran parte di questo lavoro, in particolare i modelli basati su reti convoluzionali e meccanismi di attenzione in stile Transformer. I modelli convoluzionali eccellono nell'individuare dettagli locali fini come i bordi, mentre i Transformer sono particolarmente efficaci nel cogliere il contesto ampio sull'intera immagine. Tuttavia, ciascuno presenta compromessi: le convoluzioni possono perdere relazioni a lungo raggio, mentre i Transformer spesso richiedono ingenti risorse di calcolo e memoria.
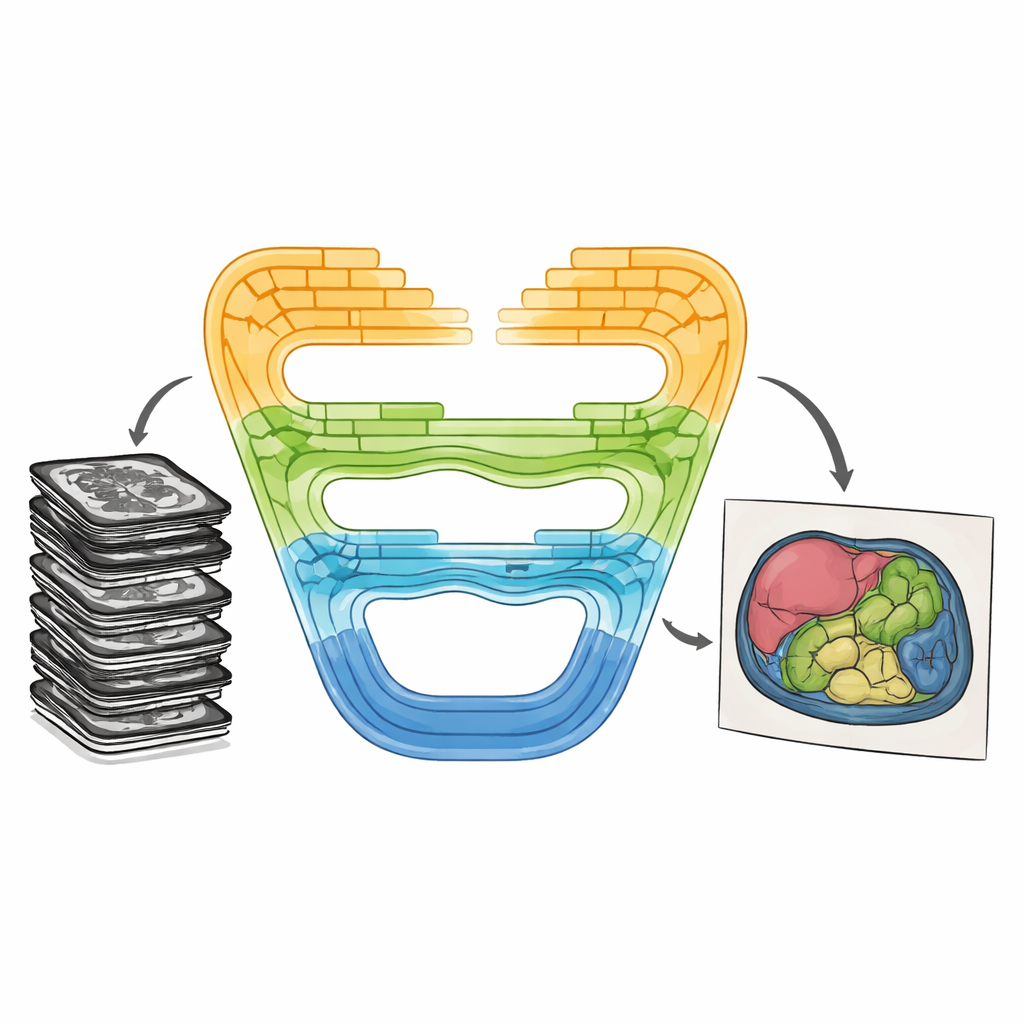
Combinare i punti di forza in modo nuovo
CMT-Unet affronta questi compromessi intrecciando tre tipi di blocchi costitutivi in modo graduato per fasi, invece di fare affidamento su un unico tipo lungo tutta la rete. All'ingresso del sistema, un'unità convoluzionale a residuo invertito apprende rapidamente pattern locali—bordi netti e texture che aiutano a distinguere i tessuti adiacenti. Nelle fasi intermedie, un modulo basato sui cosiddetti modelli di spazio di stato, adattato da una recente architettura chiamata Mamba, trasmette informazione lungo sequenze di feature dell'immagine in modo consapevole del contesto e dal costo computazionale contenuto. Più in profondità nella rete, blocchi Transformer potenziati con attenzione HiLo separano l'informazione in componenti ad alta e bassa frequenza, permettendo al modello di catturare sia dettagli minimi sia forme organiche ampie prima di ricomporli. Questo design stratificato riflette la progressione naturale dai pixel grezzi al significato astratto durante l'elaborazione delle immagini.
Come funziona il nuovo modello sotto il cofano
In pratica, CMT-Unet segue il familiare layout a forma di U, popolare nell'imaging medico: un encoder che comprime l'informazione in feature più ricche, un decoder che ricostruisce una previsione a dimensione completa, e connessioni skip che trasferiscono dettagli spaziali. La differenza chiave sta nei moduli usati a ciascuna profondità. L'unità convoluzionale iniziale gestisce la struttura a grana fine che i componenti Mamba e Transformer altrimenti potrebbero sfocare. Il blocco MambaVision modificato migliora il contesto a media distanza miscelando l'informazione spaziale tramite operazioni bidimensionali progettate ad hoc, evitando il costo elevato dell'attenzione completa pur guardando oltre i patch locali. L'attenzione HiLo nella fase Transformer separa esplicitamente i bordi netti dai pattern di sfondo più uniformi, combinandoli in modo da preservare i confini. Infine, un modulo duale di upsampling nel decoder aiuta a ricostruire contorni puliti e continui riducendo artefatti comuni come i pattern a scacchiera.
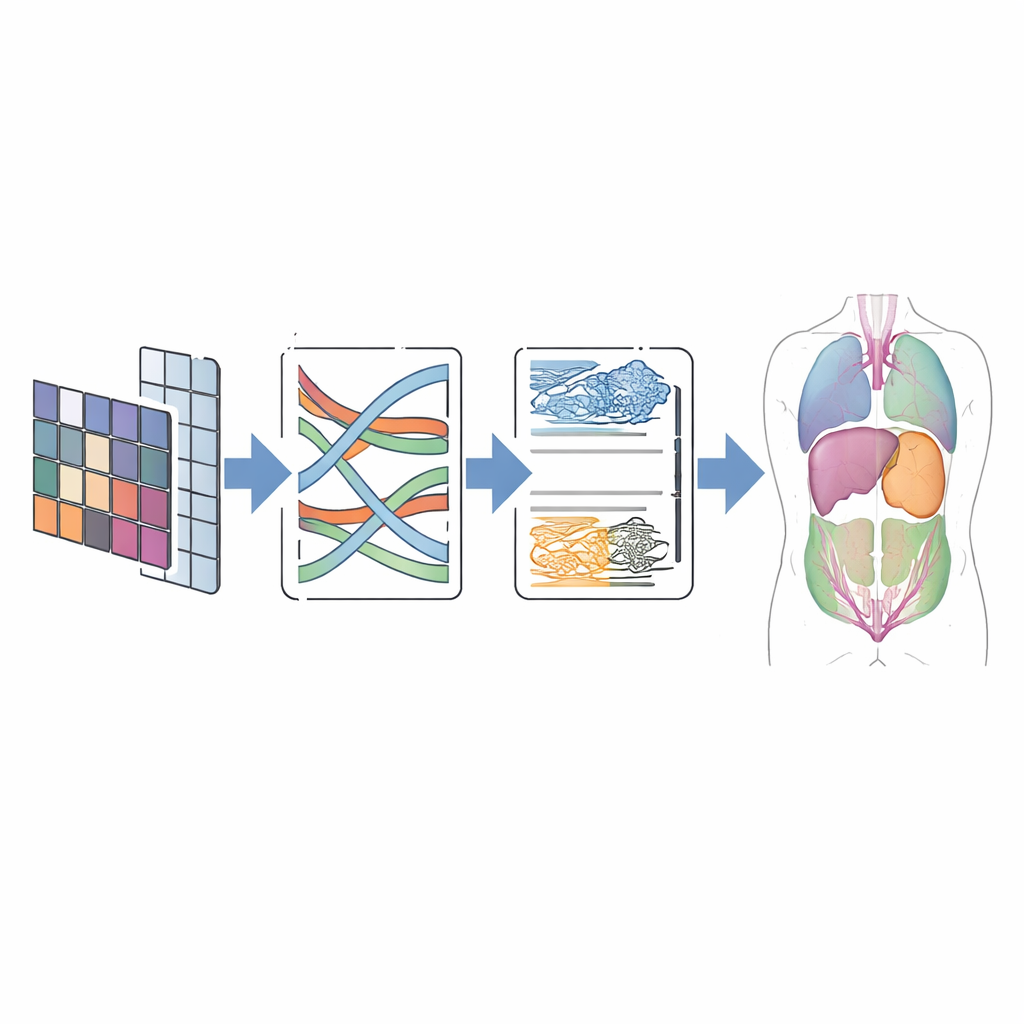
Test su scansioni del mondo reale
Per valutare se questo design dà i suoi frutti, gli autori hanno testato CMT-Unet su due dataset pubblici ampiamente usati. Il primo, chiamato Synapse, contiene TC addominali con otto organi etichettati, tra cui fegato, reni e stomaco. Il secondo, ACDC, include immagini MRI cardiache con etichette per i ventricoli e la parete muscolare del cuore. Su questi benchmark, CMT-Unet ha raggiunto punteggi di segmentazione paragonabili o superiori ai principali modelli convoluzionali, Transformer e ibridi, pur utilizzando un numero moderato di parametri e una quantità di calcolo gestibile. Le comparazioni visive hanno mostrato contorni più lisci e più coerenti dal punto di vista anatomico, soprattutto attorno a regioni difficili come le cavità cardiache, cruciali per misurare la funzione e pianificare interventi.
Cosa significa per pazienti e cliniche
Per i non specialisti, la conclusione principale è che CMT-Unet offre un modo più intelligente per tracciare le strutture nelle immagini mediche abbinando con cura lo strumento giusto alla fase giusta dell'elaborazione. Bilanciando dettaglio locale e contesto globale, il modello può produrre contorni organici accurati e puliti senza richiedere risorse di livello supercomputer. Sebbene il lavoro corrente si concentri su scansioni bidimensionali e un set limitato di dataset pubblici, l'approccio è promettente per estensioni future all'imaging tridimensionale e a contesti clinici più ampi. Se validato ulteriormente, questo tipo di segmentazione leggera ma precisa potrebbe supportare diagnosi più rapide, pianificazioni terapeutiche più affidabili e guida in tempo reale in ospedali affollati.
Citazione: Wang, R., Liu, H. & Wang, G. CMT-Unet: leveraging stage-wise hybrid framework for enhanced accuracy and efficiency in medical image segmentation. Sci Rep 16, 10079 (2026). https://doi.org/10.1038/s41598-026-40572-w
Parole chiave: segmentazione delle immagini mediche, deep learning, reti neurali ibride, modelli di spazio di stato, imaging medicale