Clear Sky Science · it
DPAS: punteggio di anomalia per peptidi associati a malattia per identificare peptidi patogeni tramite apprendimento one-class
Perché i pezzetti di proteine contano per la nostra salute
I peptidi—brevi tratti di proteine—sono diventati protagonisti nella medicina moderna. Possono agire come messaggeri precisi nell’organismo e sono sempre più impiegati come farmaci e marcatori di malattia. Tuttavia stabilire quali peptidi siano effettivamente legati a una patologia spesso richiede esempi chiari sia di peptidi “malattia” sia di peptidi “non-malattia”, cosa che la biologia raramente offre. Questo studio introduce un nuovo modo per individuare peptidi potenzialmente dannosi utilizzando solo quelli già noti essere coinvolti nella malattia, offrendo una strada più rapida e meno soggetta a bias per scoprire futuri strumenti diagnostici e terapeutici.
La sfida di trovare il gruppo “non-malattia”
I modelli computazionali tradizionali apprendono confrontando due lati: esempi positivi noti come correlati alla malattia ed esempi negativi ritenuti innocui. Nella ricerca sui peptidi, questo secondo gruppo è un problema. Molti peptidi semplicemente non sono stati testati, quindi etichettarli come “non-malattia” può essere fuorviante e introdurre bias. Studi precedenti su peptidi anti-cancro o anti-infiammatori hanno raggiunto accuratezze impressionanti, ma spesso si basavano su dataset negativi costruiti a mano o ipotizzati. Di conseguenza, i loro modelli possono avere difficoltà a riconoscere segnali rari o nuovi tipi di peptidi patogenici che non somigliano ai dati di addestramento.
Imparare da ciò che sappiamo, invece di da ciò che supponiamo
Gli autori seguono una strada diversa: invece di forzare un problema a due lati, trattano i peptidi associati a malattia come un gruppo coerente e si chiedono: “Come appare questo gruppo nel dettaglio?” Raccogliono oltre 760.000 peptidi umani mutati da un database specializzato in ambito oncologico e descrivono ciascun peptide mediante un ricco set di caratteristiche. Queste includono la frequenza di ciascun amminoacido, la disposizione delle coppie di amminoacidi, tratti fisico-chimici di base come il volume e l’idrofilia, e brevi motivi ricorrenti nella sequenza noti come motif. Una tecnica chiamata analisi delle componenti principali comprime poi questa descrizione ad alta dimensione in una forma più maneggevole preservando le principali fonti di variazione.
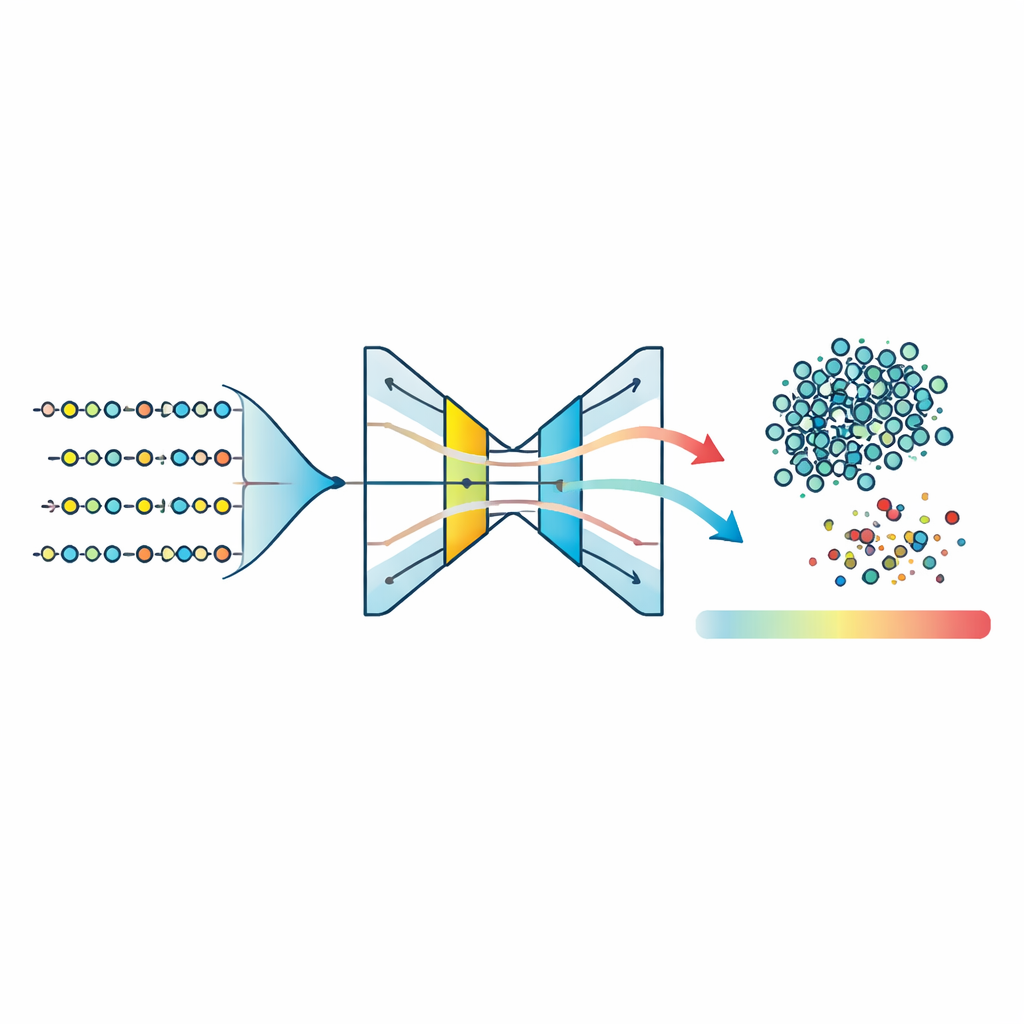
Individuare peptidi insoliti con modelli one-class
Con questo spazio di caratteristiche compresso, il gruppo allena tre modelli “one-class”—algoritmi progettati per imparare la forma di un unico gruppo e segnalare tutto ciò che non vi rientra. Testano One-Class Support Vector Machines, Isolation Forests e un tipo di rete neurale chiamata autoencoder. L’autoencoder impara a comprimere le caratteristiche di ogni peptide in una rappresentazione interna ristretta e poi a ricostruirle; i peptidi appartenenti al modello di malattia appreso vengono ricostruiti con precisione, mentre quelli insoliti provocano un errore di ricostruzione maggiore. Il confronto dei punteggi di anomalia normalizzati tra tutti i metodi mostra che l’autoencoder produce il cluster più compatto di peptidi tipici e la separazione più netta tra inlier e outlier. Impostando una soglia sull’errore di ricostruzione intorno al 95° percentile, il modello classifica la maggior parte dei peptidi come probabilmente associati alla malattia mentre individua in modo consistente una piccola frazione come atipica.
Trasformare punteggi complessi in un unico numero significativo
Per rendere i risultati più interpretabili biologicamente, gli autori introducono il Disease Peptide Anomaly Score (DPAS). Questo punteggio fonde due ingredienti: quanto un peptide appare insolito all’autoencoder (il suo errore di ricostruzione normalizzato) e quanto le sue caratteristiche contribuiscono alle predizioni, misurato da un popolare metodo di spiegazione chiamato SHAP. In pratica, emergono come particolarmente informativi i motif e specifici tratti fisico‑chimici. DPAS combina questi segnali in modo che i peptidi sia strutturalmente anomali sia supportati da caratteristiche biologicamente significative ricevano punteggi più alti. I peptidi con punteggio più elevato vengono poi esaminati con uno strumento di ricerca di motif che li collega a firme funzionali note come siti di fosforilazione, regioni di legame a metalli e altri schemi regolatori coinvolti frequentemente nella segnalazione e nel controllo enzimatico.
Cosa significa per future diagnostiche e terapie
In termini pratici, questo lavoro offre un filtro più intelligente per individuare peptidi sospetti senza fingere di sapere quali siano certamente innocui. Imparando solo da esempi confermati di peptidi associati a malattia e poi classificando nuovi candidati con DPAS, i ricercatori possono dare priorità a una lista ristretta e biologicamente plausibile di peptidi da testare in laboratorio. Molti dei candidati con i punteggi più alti contengono motif funzionali ben noti, rafforzando l’ipotesi che possano avere ruoli nei processi patologici. Sebbene il metodo dipenda ancora da assunzioni e manchi di peptidi “sicuri” convalidati sperimentalmente per una verifica completa, fornisce una base più realistica e trasparente per la scoperta di biomarcatori peptidici e potrebbe essere adattato ad altri tipi di dati biologici in cui gli esempi negativi affidabili scarseggiano.
Citazione: Khalid, Z., Khalid, R. & Sezerman, O.U. DPAS: disease-associated peptide anomaly score for identifying pathogenic peptides via one-class learning. Sci Rep 16, 9170 (2026). https://doi.org/10.1038/s41598-026-40099-0
Parole chiave: peptidi associati a malattia, rilevamento delle anomalie, autoencoder, scoperta di biomarcatori, apprendimento one-class